Что такое Milvus?
Milvus — хищная птица из рода Milvus семейства ястребиных (Accipitridae), известная своей скоростью в полете, острым зрением и замечательной приспособляемостью.
Компания Zilliz выбрала название Milvus для своей высокопроизводительной и масштабируемой векторной базы данных с открытым исходным кодом, которая эффективно работает в самых разных средах — от ноутбуков до крупномасштабных распределенных систем. Она доступна как в виде программного обеспечения с открытым исходным кодом, так и в виде облачного сервиса.
Разработанная компанией Zilliz и вскоре переданная в дар LF AI & Data Foundation при Linux Foundation, Milvus стала одним из ведущих в мире проектов векторных баз данных с открытым исходным кодом. Он распространяется по лицензии Apache 2.0, и большинство участников проекта — эксперты из сообщества высокопроизводительных вычислений (HPC), специализирующиеся на создании крупномасштабных систем и оптимизации кода с учётом аппаратных особенностей. В число основных участников входят специалисты из компаний Zilliz, ARM, NVIDIA, AMD, Intel, Meta, IBM, Salesforce, Alibaba и Microsoft.
Интересно, что каждый проект Zilliz с открытым исходным кодом назван в честь птицы — это традиция, символизирующая свободу, дальновидность и динамичное развитие технологий.
Неструктурированные данные, вложения и Milvus
Неструктурированные данные, такие как текст, изображения и аудио, имеют различные форматы и несут в себе богатую семантику, что затрудняет их анализ. Для управления этой сложностью используются вложения, которые преобразуют неструктурированные данные в числовые векторы, отражающие их основные характеристики. Затем эти векторы хранятся в векторной базе данных, что обеспечивает быстрый и масштабируемый поиск и аналитику.
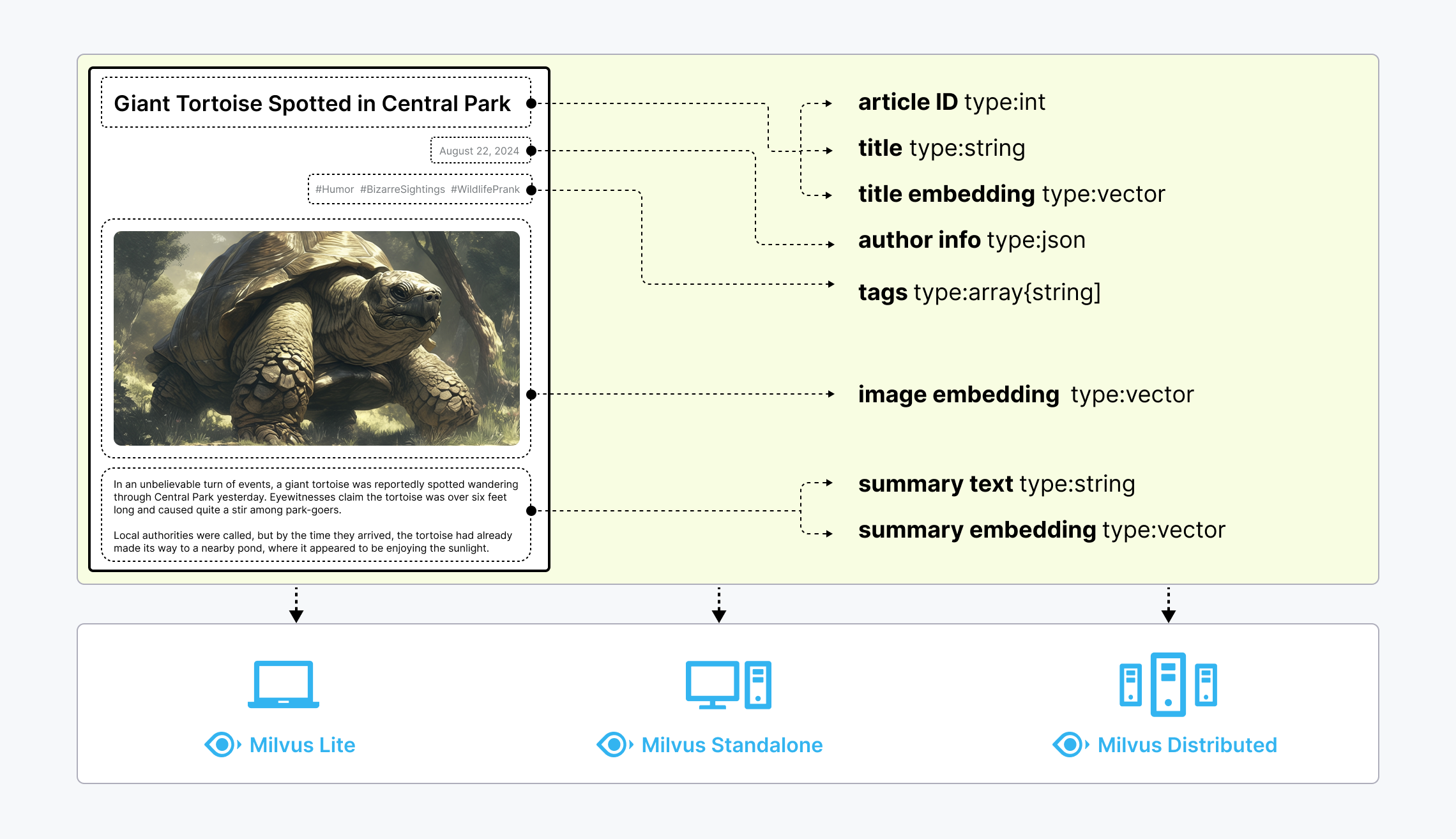
Milvus предлагает мощные возможности моделирования данных, позволяющие организовывать неструктурированные или мультимодальные данные в структурированные коллекции. Система поддерживает широкий спектр типов данных для моделирования различных атрибутов, включая распространённые числовые и символьные типы, различные векторные типы, массивы, множества и JSON, что избавляет вас от необходимости поддерживать несколько систем баз данных.
 Неструктурированные данные, вложения и Milvus
Неструктурированные данные, вложения и Milvus
Milvus предлагает три режима развертывания, охватывающих широкий диапазон масштабов данных — от локального прототипирования в Jupyter Notebooks до массивных кластеров Kubernetes, управляющих десятками миллиардов векторов:
- Milvus Lite — это библиотека на Python, которую можно легко интегрировать в ваши приложения. Являясь облегчённой версией Milvus, она идеально подходит для быстрого прототипирования в Jupyter Notebooks или запуска на периферийных устройствах с ограниченными ресурсами. Узнайте больше.
- Milvus Standalone — это развертывание сервера на одной машине, при котором все компоненты объединены в один образ Docker для удобного развертывания. Узнайте больше.
- Milvus Distributed можно развернуть в кластерах Kubernetes; он отличается облачной архитектурой, разработанной для сценариев с миллиардами векторов и более. Такая архитектура обеспечивает избыточность критически важных компонентов. Узнайте больше.
Что делает Milvus таким быстрым?
С самого начала Milvus разрабатывался как высокоэффективная система векторных баз данных. В большинстве случаев Milvus превосходит другие векторные базы данных в 2–5 раз (см. результаты теста VectorDBBench). Такая высокая производительность является результатом нескольких ключевых проектных решений:
Оптимизация с учётом аппаратных особенностей: чтобы обеспечить работу Milvus в различных аппаратных средах, мы оптимизировали его производительность специально для множества аппаратных архитектур и платформ, включая AVX512, SIMD, графические процессоры (GPU) и SSD-накопители NVMe.
Передовые алгоритмы поиска: Milvus поддерживает широкий спектр алгоритмов индексирования и поиска как в памяти, так и на диске, включая IVF, HNSW, DiskANN и другие, каждый из которых был тщательно оптимизирован. По сравнению с популярными реализациями, такими как FAISS и HNSWLib, Milvus демонстрирует на 30–70 % более высокую производительность.
Поисковая система на C++: Более 80 % производительности векторной базы данных определяется её поисковой системой. Milvus использует C++ для реализации этого критически важного компонента благодаря высокой производительности языка, низкоуровневой оптимизации и эффективному управлению ресурсами. Что наиболее важно, Milvus включает в себя множество оптимизаций кода с учётом аппаратных возможностей — от векторизации на уровне ассемблера до многопоточной параллелизации и планирования — для полного использования возможностей аппаратного обеспечения.
Колоночная архитектура: Milvus — это векторная база данных с колоночной архитектурой. Основные преимущества связаны с моделями доступа к данным. При выполнении запросов столбцово-ориентированная база данных считывает только конкретные поля, затронутые запросом, а не целые строки, что значительно сокращает объем данных, к которым осуществляется доступ. Кроме того, операции над данными, организованными по столбцам, легко векторизируются, что позволяет применять операции сразу ко всем столбцам, еще больше повышая производительность.
Что делает Milvus настолько масштабируемой
В 2022 году Milvus поддерживала векторы в миллиардном масштабе, а в 2023 году масштабировалась до десятков миллиардов с неизменной стабильностью, обеспечивая работу крупномасштабных сценариев для более чем 300 крупных предприятий, включая Salesforce, PayPal, Shopee, Airbnb, eBay, NVIDIA, IBM, AT&T, LINE, ROBLOX, Inflection и др.
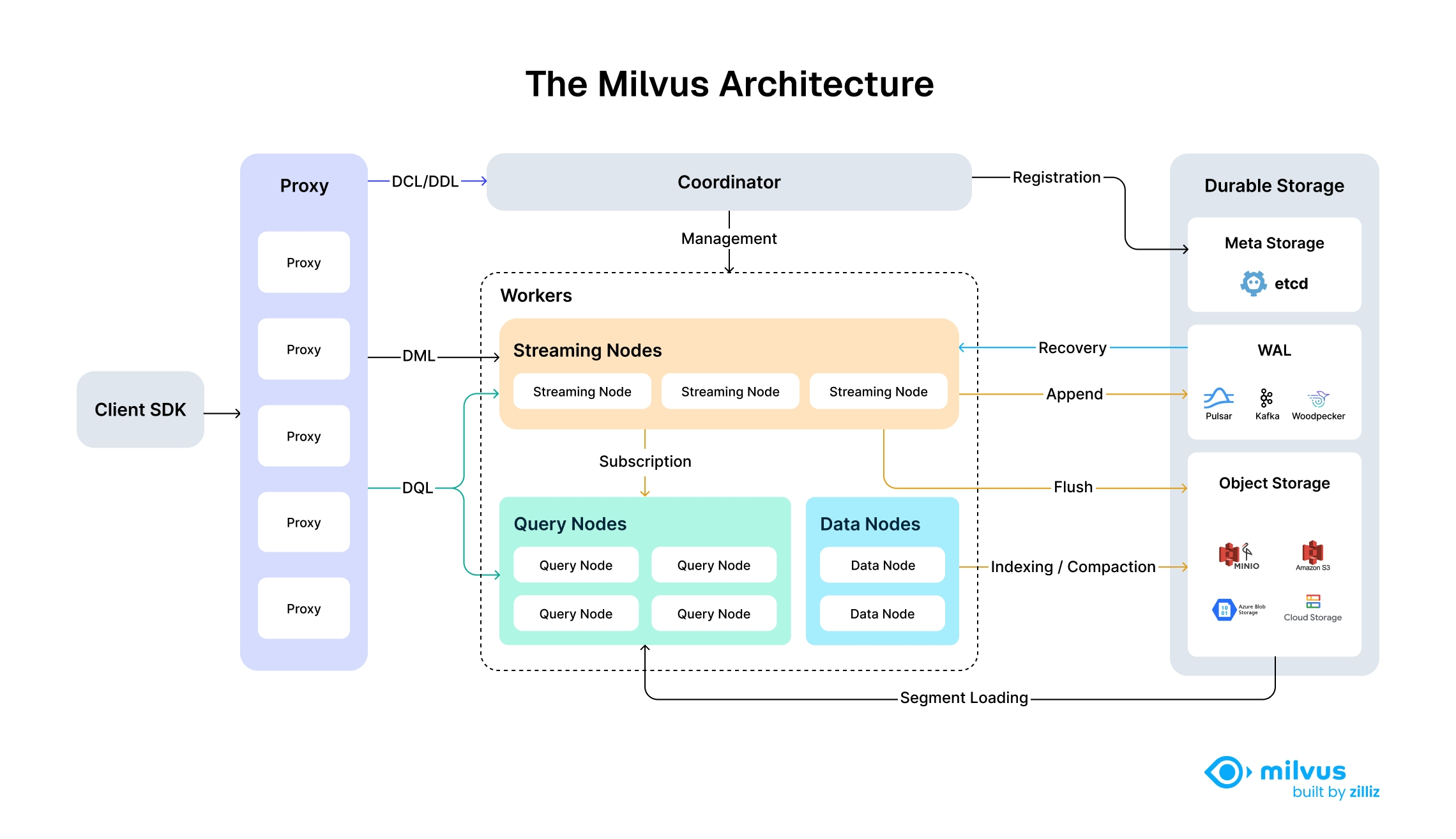
Облачная и высокоразвязанная системная архитектура Milvus гарантирует, что система может непрерывно расширяться по мере роста объема данных:
 Высокодекуплированная системная архитектура Milvus
Высокодекуплированная системная архитектура Milvus
Сама система Milvus является полностью безсостоятельной, поэтому её можно легко масштабировать с помощью Kubernetes или публичных облаков. Кроме того, компоненты Milvus хорошо развязаны между собой: три наиболее важные задачи — поиск, вставка данных и индексирование/уплотнение — реализованы в виде процессов, легко поддающихся параллелизации, при этом сложная логика вынесена за пределы этих процессов. Это гарантирует, что соответствующие узел запросов, узел данных и узел индексации могут масштабироваться как по вертикали, так и по горизонтали независимо друг от друга, что позволяет оптимизировать производительность и экономическую эффективность.
Типы поиска, поддерживаемые Milvus
Milvus поддерживает различные типы поисковых функций для удовлетворения потребностей различных сценариев использования:
- Поиск по ANN: находит K векторов, наиболее близких к вектору запроса.
- Поиск с фильтрацией: выполняет поиск ANN при заданных условиях фильтрации.
- Поиск по диапазону: находит векторы в пределах заданного радиуса от вектора запроса.
- Гибридный поиск: выполняет поиск с помощью нейронной сети на основе нескольких векторных полей.
- Полнотекстовый поиск: полнотекстовый поиск на основе алгоритма BM25.
- Переранжирование: корректирует порядок результатов поиска на основе дополнительных критериев или вторичного алгоритма, уточняя первоначальные результаты поиска по ANN.
- Извлечение: извлекает данные по их первичным ключам.
- Запрос: извлекает данные с использованием определённых выражений.
Широкий набор функций
Помимо ключевых функций поиска, упомянутых выше, Milvus также предоставляет набор функций, реализованных на основе поиска с использованием нейронных сетей (ANN), что позволяет в полной мере использовать его возможности.
API и SDK
- RESTful API (официальный)
- PyMilvus (SDK для Python) (официальный)
- Go SDK (официальный)
- Java SDK (официальный)
- SDK дляNode.js (JavaScript) (официальный)
- C# (предоставлено Microsoft)
- C++ SDK (официальный)
- Rust SDK (в разработке)
Расширенные типы данных
Помимо примитивных типов данных Milvus поддерживает различные расширенные типы данных и соответствующие метрики расстояния для них.
- Разреженные векторы
- Двоичные векторы
- Поддержка JSON
- Поддержка массивов
- Геолокация
- Текст (в стадии разработки)
Почему Milvus?
Высокая производительность при масштабировании и высокая доступность
Milvus обладает распределенной архитектурой, в которой вычислительные ресурсы и хранилище разделены. Milvus может горизонтально масштабироваться и адаптироваться к различным моделям трафика, достигая оптимальной производительности за счет независимого увеличения количества узлов запросов при нагрузке с преобладанием чтения и узлов данных при нагрузке с преобладанием записи. Микросервисы без состояния на K8s позволяют быстро восстанавливаться после сбоев, обеспечивая высокую доступность. Поддержка реплик дополнительно повышает отказоустойчивость и пропускную способность за счет распределения сегментов данных по нескольким узлам запросов. См. тесты производительности для сравнения.
Поддержка различных типов векторных индексов и аппаратное ускорение
Milvus разделяет систему и ядро векторного поискового движка, что позволяет ему поддерживать все основные типы векторных индексов, оптимизированные для различных сценариев, включая HNSW, IVF, FLAT (метод перебора), SCANN и DiskANN, а также их варианты на основе квантования и mmap. Milvus оптимизирует векторный поиск для таких расширенных функций, как фильтрация по метаданным и поиск по диапазону. Кроме того, Milvus реализует аппаратное ускорение для повышения производительности векторного поиска и поддерживает индексирование на GPU, например с помощью технологии CAGRA от NVIDIA.
Гибкая многопользовательская архитектура и «горячее»/«холодное» хранение
Milvus поддерживает многопользовательский режим за счет изоляции на уровне базы данных, коллекции, раздела или ключа раздела. Гибкие стратегии позволяют одному кластеру обслуживать от сотен до миллионов пользователей, а также обеспечивают оптимизированную производительность поиска и гибкий контроль доступа. Milvus повышает экономическую эффективность за счет использования «горячего» и «холодного» хранилищ. Часто используемые «горячие» данные могут храниться в памяти или на SSD-накопителях для обеспечения более высокой производительности, в то время как реже используемые «холодные» данные хранятся на более медленных и экономичных носителях. Этот механизм позволяет значительно сократить затраты, сохраняя при этом высокую производительность при выполнении критически важных задач.
Редкий вектор для полнотекстового и гибридного поиска
Помимо семантического поиска с использованием плотного вектора, Milvus также изначально поддерживает полнотекстовый поиск с использованием алгоритма BM25, а также обученные разреженные вложения, такие как SPLADE и BGE-M3. Пользователи могут хранить разреженные и плотные векторы в одной коллекции и определять функции для переранжирования результатов по нескольким поисковым запросам. См. примеры гибридного поиска с использованием семантического поиска и полнотекстового поиска.
Безопасность данных и тонкий контроль доступа
Milvus обеспечивает безопасность данных за счет обязательной аутентификации пользователей, шифрования TLS и управления доступом на основе ролей (RBAC). Аутентификация пользователей гарантирует, что доступ к базе данных имеют только авторизованные пользователи с действительными учетными данными, а шифрование TLS защищает всю сетевую коммуникацию. Кроме того, система RBAC позволяет осуществлять тонкое управление доступом путем присвоения пользователям определённых прав в зависимости от их ролей. Эти функции делают Milvus надёжным и безопасным решением для корпоративных приложений, защищая конфиденциальные данные от несанкционированного доступа и потенциальных утечек.
Интеграция с ИИ
Интеграция моделей вложения Модели вложения преобразуют неструктурированные данные в их числовое представление в высокомерном пространстве данных, что позволяет хранить их в Milvus. В настоящее время PyMilvus, SDK для Python, интегрирует несколько моделей вложения, благодаря чему вы можете быстро подготовить свои данные для преобразования в векторные вложения. Подробности см. в разделе «Обзор вложения».
Интеграция моделей переранжирования В сфере поиска информации и генеративного ИИ реранкер является важным инструментом, оптимизирующим порядок результатов первоначального поиска. PyMilvus также интегрирует несколько моделей переранжирования для оптимизации порядка результатов, возвращаемых по результатам первоначального поиска. Подробности см. в разделе «Обзор реранкеров».
Интеграция с LangChain и другими инструментами ИИ В эпоху генеративного ИИ (GenAI) такие инструменты, как LangChain, привлекают большое внимание разработчиков приложений. Являясь ключевым компонентом, Milvus обычно выступает в качестве векторного хранилища в таких инструментах. Чтобы узнать, как интегрировать Milvus в ваши любимые инструменты ИИ, ознакомьтесь с нашими разделами «Интеграции» и «Учебные материалы».
Инструменты и экосистема
Attu Attu — это универсальный интуитивный графический интерфейс, который помогает управлять Milvus и хранящимися в нём данными. Подробности см. в репозитории Attu.
Birdwatcher Birdwatcher — это инструмент отладки для Milvus. Используя его для подключения к etcd, вы можете проверять состояние вашей системы Milvus или настраивать её в режиме реального времени. Подробности см. в разделе BirdWatcher.
Интеграция с Prometheus и Grafana Prometheus — это набор инструментов с открытым исходным кодом для мониторинга системы и оповещений в Kubernetes. Grafana — это стек визуализации с открытым исходным кодом, который может подключаться ко всем источникам данных. Вы можете использовать Prometheus и Grafana в качестве поставщика услуг мониторинга для визуального отслеживания производительности распределенной системы Milvus. Подробности см. в разделе «Развертывание служб мониторинга».
Milvus Backup Milvus Backup — это инструмент, позволяющий пользователям создавать резервные копии и восстанавливать данные Milvus. Он предоставляет как CLI, так и API, что позволяет адаптировать его к различным сценариям применения. Подробности см. в разделе «Milvus Backup».
Milvus Capture Data Change (CDC) Milvus CDC может реплицировать изменения данных из одного кластера Milvus в другой для обеспечения аварийного восстановления по схеме «основной-резервный». Подробности см. в разделе «Milvus CDC».
Коннекторы Milvus Milvus подготовил набор коннекторов, позволяющих легко интегрировать Milvus со сторонними инструментами, такими как Apache Spark. В настоящее время вы можете использовать наш коннектор Spark для передачи данных из Milvus в Apache Spark с целью обработки с помощью машинного обучения. Подробности см. в разделе «Коннектор Spark-Milvus».
Службы передачи векторных данных (VTS) Milvus предоставляет набор инструментов для передачи данных между экземпляром Milvus и различными источниками данных, включая кластеры Zilliz, Elasticsearch, Postgres (PgVector) и другой экземпляр Milvus. Подробности см. в разделе VTS.