Claudeのコードコンテキスト管理に最適なオープンソースツール7選
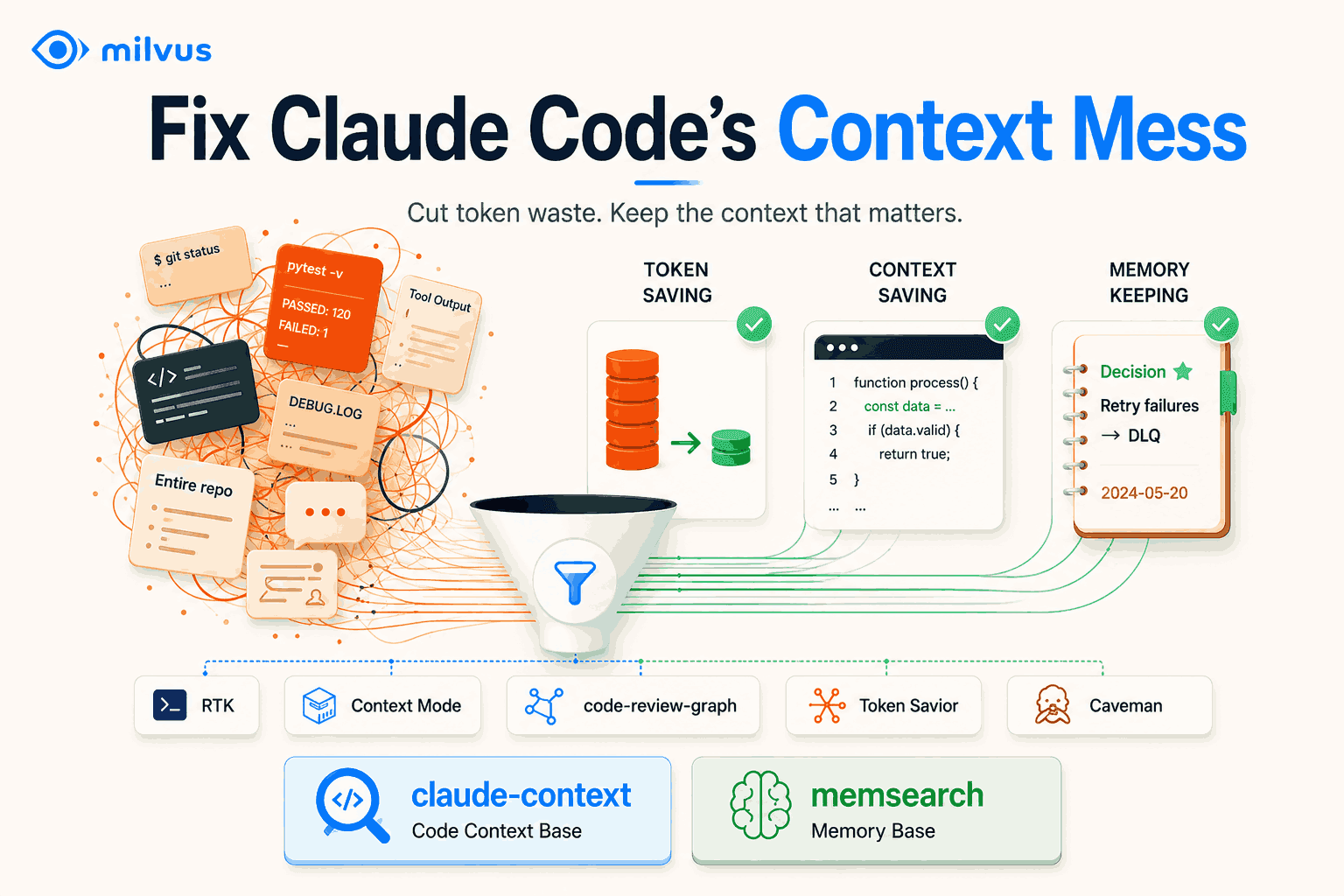
Claude Code に 100 万トークンのコンテキストウィンドウを指定しても、時間の経過とともに回答の質が低下することがあります。問題はコンテキストのサイズだけではありません。コンテキストの質にも原因があります。
ターミナルのログ、ツールの生の出力、繰り返されるファイル読み込み、冗長な応答、そして忘れ去られたプロジェクトの履歴などが、すべてモデルの注意を奪い合うと、Claude Codeのセッションの品質は低下します。長時間実行されるエージェントのワークフローでは、そのノイズがループ化してしまいます。モデルが話の筋を見失い、回答を修正するためにターン数を増やせば、その分、さらにノイズが増えてしまうのです。
これが「コンテキストの焦点喪失」です。モデルには情報を保持する十分な容量があるものの、重要な情報が信号の弱いコンテキストの下に埋もれてしまっているのです。ウィンドウが大きくなると、開発者がプロンプトに何を入力するかを慎重に考えなくなるため、この問題を無視しやすくなってしまいます。
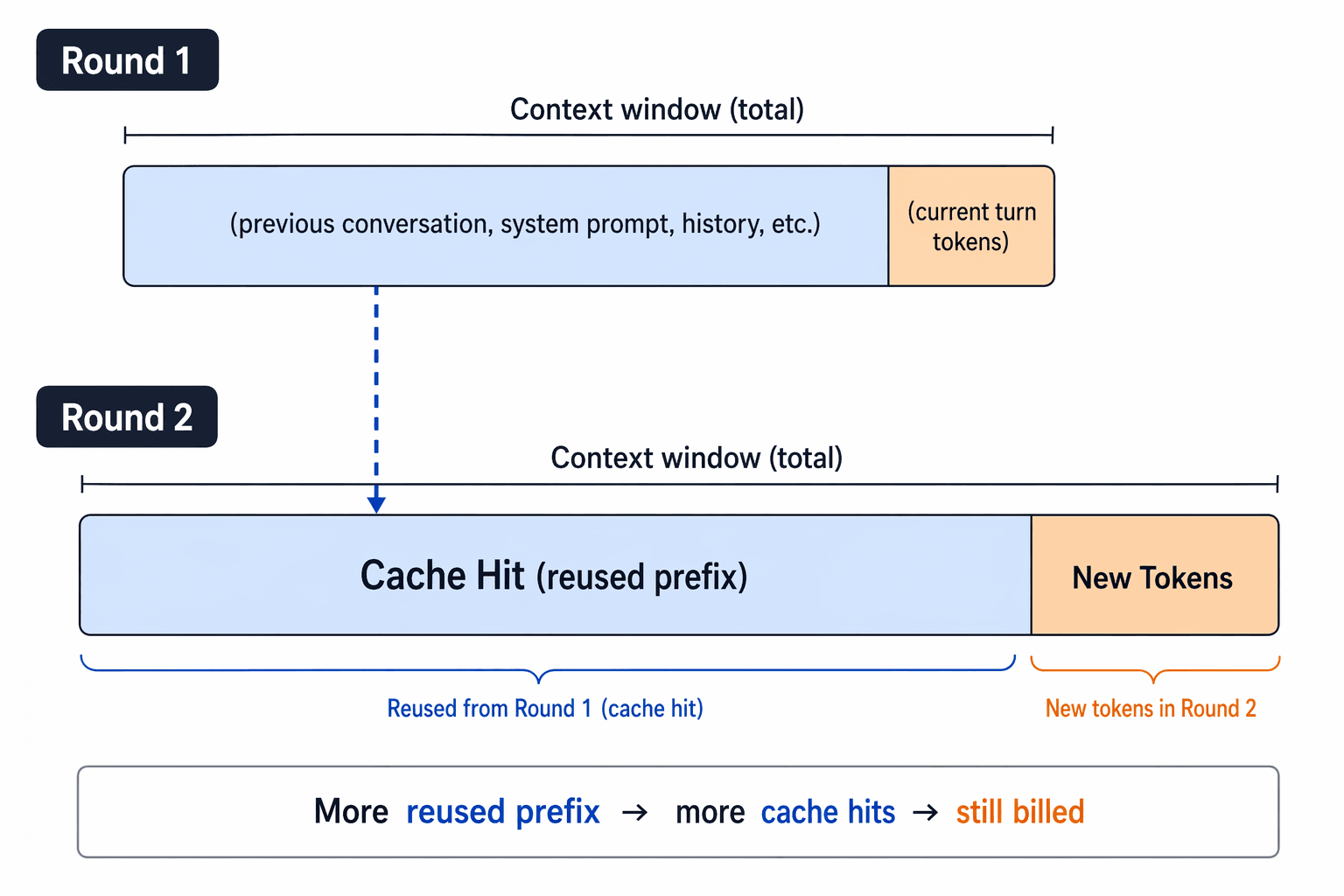 再利用されたプレフィックスが、ターン間で課金対象となるコンテキストを依然として増加させる仕組みを示すプロンプトキャッシュの図
再利用されたプレフィックスが、ターン間で課金対象となるコンテキストを依然として増加させる仕組みを示すプロンプトキャッシュの図
プロンプトキャッシュは、プレフィックスの繰り返しによるコストを削減できますが、コンテキストウィンドウを「ガラクタ入れ」に変えるわけではありません。新しいトークンには依然としてコストがかかり、モデルが正しい情報に基づいて推論を行う必要があります。
本記事では、コンテキストの焦点喪失に、ターミナル出力、ツール出力、コードベースのナビゲーション、ファイル読み取り、モデルの冗長性、意味的コード検索、セッション間メモリという異なるレイヤーから取り組む7つのオープンソースツールを紹介する。また、これらのアイデアが、ベクトルデータベースの設計、ベクトル類似度検索、およびMilvusのような検索システムにどのように対応するかも解説する。
Claude Codeのコンテキストの焦点喪失の原因とは?
Claude Codeのコンテキストの焦点喪失は、通常、5つの失敗モードに起因します。それは、生の指示テキストが多すぎる、ノイズの多いツール出力、コードベースの探索の繰り返し、モデルの応答が長すぎる、およびセッションやエージェント間の記憶の断絶です。
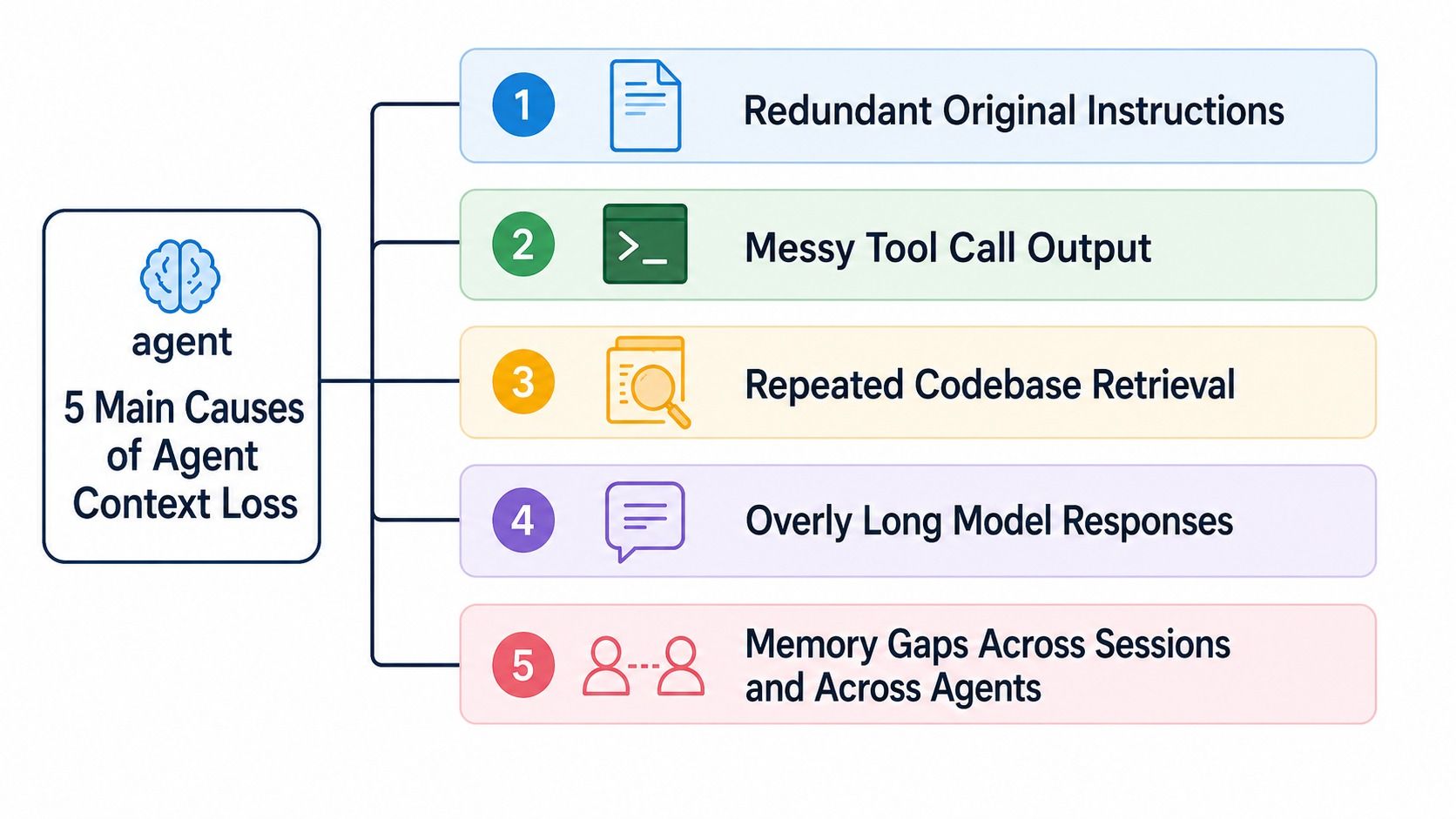 Claude Codeのコンテキスト喪失の5つの原因:冗長な指示、乱雑なツール出力、繰り返されるコードベースの探索、長い応答、および記憶の断絶
Claude Codeのコンテキスト喪失の5つの原因:冗長な指示、乱雑なツール出力、繰り返されるコードベースの探索、長い応答、および記憶の断絶
| コンテキストの失敗モード | Claude Codeにおける具体的な症状 | 役立つツールのカテゴリ |
|---|---|---|
| ターミナルログがノイズが多い | git、pytest 、gh 、およびクラウドCLIは、モデルが必要とする量以上のテキストを出力します。 | CLI出力の圧縮 |
| ツールの出力がウィンドウを埋め尽くす | テストログ、DOMダンプ、MCPの出力が、巨大な生のブロックとしてチャットに表示される。 | ツール出力のサンドボックス化 |
| コードベースのナビゲーションが繰り返される | Claudeはディレクトリを列挙し、grepを実行し、ファイルを読み込み、セッションごとに同じ探索を繰り返す。 | コードグラフまたは意味的検索 |
| ファイルの読み込み範囲が広すぎる | モデルは、1つのシンボルや要約だけで済むにもかかわらず、ファイル全体を読み込んでしまう。 | 段階的なコード読み取り |
| Claudeの話しすぎ | 回答自体が、その後のやり取りに不要な文脈を追加してしまう。 | 応答の圧縮 |
| 記憶が保持されない | 新しいセッションを始めるたびに、プロジェクトの決定事項を改めて説明することになる。 | 「マークダウン優先」の記憶 |
優れたコンテキスト管理スタックには、3つの役割が求められます。不要な情報を排除し、必要に応じて適切なプロジェクト知識を取り出し、セッションをまたいで決定内容を永続的に保持することです。
どのClaude Codeコンテキストツールを最初に使うべきか?
ワークフローの中で最もノイズを生み出しているレイヤーから始めましょう。ターミナルの出力が問題なら、RTKから始めます。Claudeが巨大なリポジトリ内をさまよってしまうなら、claude-contextやcode-review-graphから始めます。毎日同じ決定事項を説明し直さなければならないことが本当の悩みなら、memsearchから始めましょう。
| ツール | 解決する主な問題 | 最適な組み合わせ |
|---|---|---|
| RTK | 一般的な開発者向けコマンドによるノイズの多いターミナル出力。 | Claude Code内で多くのCLIコマンドを実行する開発者。 |
| コンテキストモード | メインの会話に大量の生のツール出力が流入する。 | Playwright、GitHub、ログ、またはMCPツールを多用するユーザー。 |
| code-review-graph | 大規模なリポジトリにおけるコードベースの盲目的な探索。 | レビュー、依存関係分析、および影響範囲に関する質問。 |
| Token Savior | シンボルの要約で事足りる場面でもファイル全体を読み込んでしまう。 | 大容量ファイル、シンボルの繰り返し検索、およびコードの増分読み込み。 |
| Caveman | Claude自身の冗長な応答癖。 | 簡潔な出力と、将来的なコンテキストの縮小を望むユーザー。 |
| claude-context | セッションごとにコードベースを再探索すること。 | MCPによる意味論的なコード検索。 |
| memsearch | セッション、エージェント、モデルの切り替えをまたいでプロジェクトの記憶が失われる。 | 持続的な意思決定と教訓を含む、長期にわたるプロジェクト。 |
最初の5つのツールは、コンテキストに入ったり残ったりする情報を削減します。最後の2つは、有用なコンテキストをより簡単に呼び出せるようにします。
RTKは、Claudeがコマンドの出力を認識する前に、生のコマンド出力を圧縮します
RTKは、一般的な開発者向けコマンドのトークン使用量を削減するためのCLIプロキシです。GitHubの説明によると、一般的な開発コマンドにおけるLLMのトークン消費量を60~90%削減し、単一のRustバイナリとして提供されています。
日常的なClaude Codeの使用において、git status 、pytest 、ディレクトリ一覧表示などのコマンドは、しばしば完全な環境情報やステータス説明をコンテキストウィンドウに書き出します。モデルが必要とするのは通常、どのファイルが変更されたか、どのテストが失敗したか、プルリクエストがどこで滞っているか、あるいはディレクトリ内にどのような重要なファイルが存在するかといった、より簡潔な回答だけです。
RTKはシェルとClaudeの間に位置します。Claude Codeのフックを通じてコマンドを書き換え、圧縮された出力を返すことが可能です。
git status の生の出力:
On branch feat/payment-retry
Your branch is up to date with 'origin/feat/payment-retry'.
Changes not staged for commit:
modified: src/webhook/handler.ts
modified: src/queue/dlq.ts
modified: tests/webhook.test.ts
Untracked files:
docs/notes.md
no changes added to commit
実際に重要な情報:
3 modified, 1 untracked
- src/webhook/handler.ts
- src/queue/dlq.ts
- tests/webhook.test.ts
pytest でも状況は同じです。生の出力には、成功したケースや環境ノイズが大量に含まれています:
============================= test session starts =============================
platform darwin -- Python 3.12.4, pytest-8.4.1
collected 128 items
tests/test_auth.py …
tests/test_webhook.py …F…
tests/test_queue.py …
================================== FAILURES ==================================
________________ test_retry_to_dlq __________________
E AssertionError: expected status code 202, got 500
圧縮されると、メッセージは一目で理解できます:
128 tests collected, 1 failed
FAIL tests/test_webhook.py::test_retry_to_dlq
AssertionError: expected status code 202, got 500
コンテキストの肥大化がコードの取得ではなくシェルコマンドに起因している場合、RTKは最も手軽な出発点となります。
コンテキストモードは、メインチャットの外で巨大なツール出力をサンドボックス化します
Context Modeは、ツールが返す生のデータブロック(テストログ、ブラウザのDOMスナップショット、GitHubのペイロード、MCPツールの出力、スクレイピングされたページなど)を処理するために設計されています。GitHubの説明文では、AIコーディングエージェント向けのコンテキストウィンドウの最適化が強調されており、ツール出力が98%削減されたと報告されています。
 サンドボックス化されたツール出力とコンテキスト最適化の位置付けを示す、Context ModeのGitHubリポジトリカード
サンドボックス化されたツール出力とコンテキスト最適化の位置付けを示す、Context ModeのGitHubリポジトリカード
そのアプローチは、大規模なツール出力をローカルのサンドボックスとインデックスに隔離し、要約と検索ハンドルのみをClaudeの会話に渡すというものです。
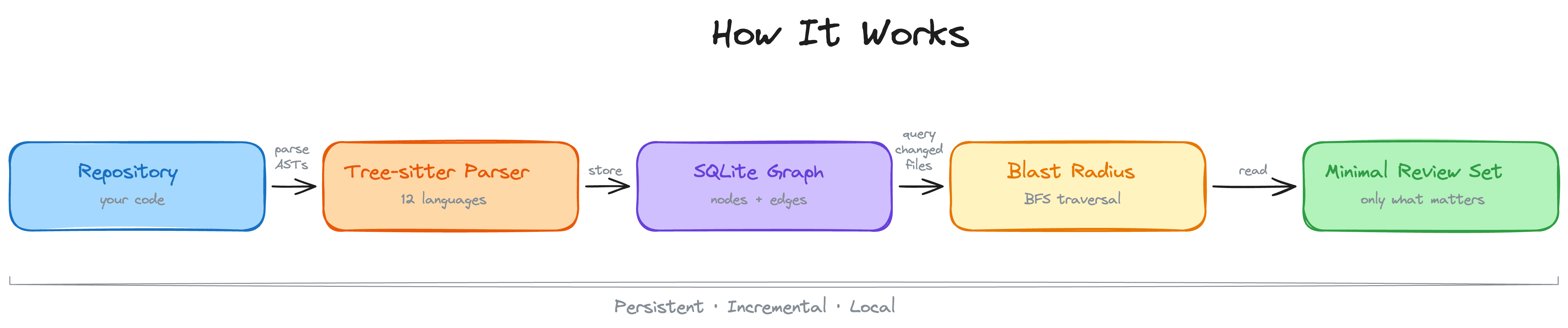
 Context Modeのフロー:大規模なツール出力が、サンドボックス実行、SQLiteまたはFTSインデックス、要約、検索結果を経て処理される様子
Context Modeのフロー:大規模なツール出力が、サンドボックス実行、SQLiteまたはFTSインデックス、要約、検索結果を経て処理される様子
このフローが有用なのは、コーディングエージェントが、DOM全体やすべてのテスト通過行ではなく、失敗したノード、破損したセレクタ、または関連するスタックトレースを必要とすることが多いためです。Context Modeは、完全な出力をローカルで利用可能な状態に保ちつつ、それがメインの会話の主導権を握ることを防ぎます。
これは、実稼働中のハイブリッド検索システムが保存と検索を分離している仕組みに似ています。生データを耐久性のある場所に保存しておき、必要な部分のみを取り出すのです。
code-review-graphは、Claudeがコード構造を探索する前にその構造をマッピングします
code-review-graphは別の問題に対処しています。Claudeには必ずしもより多くのテキストが必要なのではなく、より優れたマップが必要なのです。
 元の記事で使用された code-review-graph のロゴ画像
元の記事で使用された code-review-graph のロゴ画像
大規模なリポジトリでは、単純な質問がコストのかかる探索を引き起こす可能性があります:
このログインロジックを変更した後、どのファイルやテストに影響が出るでしょうか?
コードグラフがなければ、Claudeの典型的な動作は次のようになります:
read auth.ts
grep login
read middleware
read tests
keep guessing
code-review-graphは、コードベースの構造マップを事前に構築します。Tree-sitterを使用して関数、クラス、インポート、呼び出し関係、継承、テストの依存関係を解析し、そのグラフをSQLiteに書き込みます。
これにより、コードレビューや影響範囲の分析に役立ちます。Claudeに繰り返し読み込みを行わせて依存関係グラフを再発見させる代わりに、まず構造をクエリさせることができます。
これはセマンティック検索と類似していますが、同一ではありません。構造グラフは「何が何に依存しているか?」という問いに答え、セマンティック検索は「この質問と概念的に関連するコードは何か?」という問いに答えます。実際のコードアシスタントのワークフローでは、多くの場合、その両方が求められます。
Token Saviorは、ファイル全体を送る前にClaudeにシンボル要約を提供します
Token Saviorの核心となる考え方は単純です。デフォルトではファイル全体を送信せず、まずインデックスやシンボル要約を送信し、タスクでより詳細な情報が必要になった場合にのみ展開するというものです。
 Token SaviorのGitHubリポジトリカード。MCPサーバーの説明とプロジェクト統計が表示されています
Token SaviorのGitHubリポジトリカード。MCPサーバーの説明とプロジェクト統計が表示されています
支払いウェブフックがどこで処理されているかを尋ねた場合、モデルは通常、関連するすべてのファイルのすべての行を必要としません。まず、そのファイルやシンボルが関連しているかどうかを知る必要があります。
Token Saviorはコードを階層的に提供します:
| レイヤー | Claudeが受け取る内容 | 展開されると |
|---|---|---|
| 概要 | インデックス、シンボル名、および簡単な説明。 | デフォルトの最初の応答。 |
| スニペット | 関連するシンボルを中心とした、より小規模なコードセクション。 | 要約が関連性が高いと思われる場合。 |
| ファイル全体 | ファイルの内容全体。 | 編集や詳細な推論が必要な場合にのみ表示されます。 |
これは、開発者が実際にコードを読む方法と一致しています。まずざっと目を通し、関連性を確認してから、必要な場合にのみファイル全体を開きます。また、RAGアプリケーションで使用される「段階的な情報取得」のパターンにも似ています。つまり、全体像を把握するために広範囲に情報を取得し、生成前にコンテキストを絞り込むというものです。
CavemanはClaude自身の応答の肥大化を軽減します
ほとんどのコンテキストツールは、モデルに入力される内容に焦点を当てています。Cavemanは、Claudeが出力する内容に焦点を当てています。
Cavemanは、Claude Code用のスキル/プラグインであり、無駄な言葉、挨拶、前置きとなる文、過剰な説明、反復的な構造を取り除きます。その目的は知識を削除することではなく、回答をより凝縮させることにあります。
Cavemanを使用しない場合:
Reactコンポーネントが再レンダリングされる理由は、おそらく……
Caveman使用時:
レンダリングのたびに新しいオブジェクト参照が生成されるためです。インラインのオブジェクトプロパティ = 新しい参照 = 再レンダリング。useMemoでラップしてください。
これが重要なのは、Claude自身の回答が将来のコンテキストとなるからです。すべての回答に長い説明が含まれていると、次のターンが必要以上に多くのテキストから始まってしまいます。回答を短くすることは、現在のターンを改善するのと同じくらい、次のターンを改善することにもつながります。
AIエージェントのコンテキストエンジニアリングを検討しているチームにとって、Cavemanは「出力ポリシーがコンテキストポリシーの一部である」ことを再認識させるものです。
claude-contextはMCPを通じてセマンティックなコード検索を追加します
claude-contextは、セマンティック検索を用いてコードベースの重複探索問題を解決します。リポジトリをインデックス化し、コードの断片をベクトルデータベースに格納し、Model Context Protocolを通じて検索機能を提供します。
 GitHubに公開されているClaude Contextリポジトリ(原文記事のトレンド欄に掲載
GitHubに公開されているClaude Contextリポジトリ(原文記事のトレンド欄に掲載
大規模なコードベースでは、次のような質問をClaudeに絶えず投げかけています:
「このバグに関連している可能性のあるコードの箇所を特定するのを手伝ってください。」
検索レイヤーがない場合、Claudeのデフォルトのアプローチは多くの場合次のようなものです:
list the directory
grep around
read a bunch of files
keep guessing
claude-contextは、その処理を検索レイヤーに移行させます。リポジトリをチャンクに分割し、埋め込みを生成してMilvusを基盤とするコードインデックスに格納し、モデルがやみくもにファイルを読み込む前に、関連するコードチャンクを検索します。
 claude-contextのフロー図:コードベースのチャンク化、埋め込みベクトル、ベクトルデータベースとハイブリッド検索、関連コードの検索、およびClaudeへのコンテキスト注入
claude-contextのフロー図:コードベースのチャンク化、埋め込みベクトル、ベクトルデータベースとハイブリッド検索、関連コードの検索、およびClaudeへのコンテキスト注入
ここで、AIコーディングツールは検索システムのような様相を帯びてきます。チャンク化、埋め込み、メタデータ、語彙マッチング、ランキング、そして最新性が求められます。これらは、本番環境におけるRAG検索、ハイブリッド検索ルーティング、および埋め込みモデル選択の背後にある構成要素と同じものです。
memsearchは、セッションやエージェントをまたいで有用な記憶を保持します
memsearchは、この問題の反対側、つまり「何を忘れるか」ではなく、「重要な情報をどのように呼び出すか」という課題に取り組んでいます。
 memsearchのロゴ画像(原文記事より
memsearchのロゴ画像(原文記事より
月曜日にClaudeに次のように指示したと想像してみてください:
「当社のWebhookは失敗時に再試行できません。失敗したイベントはデッドレターキューに入れる必要があります。」
水曜日に、新しいセッションを開いて次のように尋ねます:
「Webhookレイヤーで他に最適化できる点はありますか?」
永続的なメモリがないため、Claudeは月曜日の決定をまるでなかったことのように扱います。そこで、あなたは改めて説明します。
memsearchは、メモリをローカルの、人間が読めるMarkdownファイルとして保存し、再構築可能な検索インデックスとしてMilvusを使用します。この設計により、人間がメモリを編集できる状態を維持しつつ、エージェントによる検索も可能にしています。
検索時、memsearchは「プログレッシブ・リコール」を採用しています。まず検索を行い、必要に応じて展開し、必要な場合にのみ元のトランスクリプトまで掘り下げていきます。
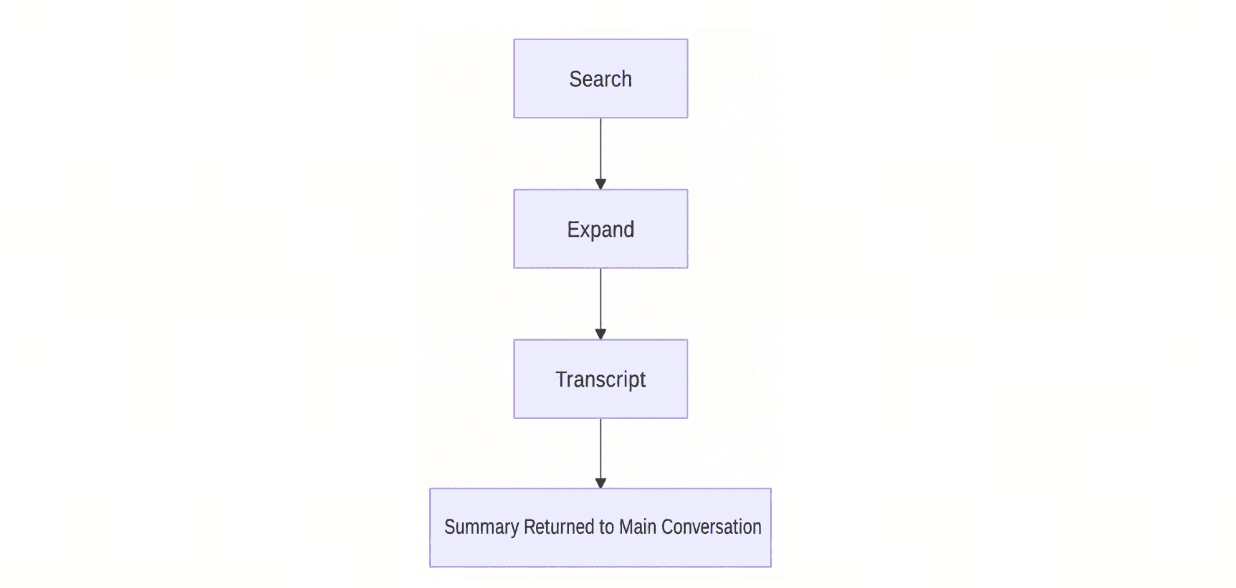 memsearchのプログレッシブ検索フロー:検索、展開、トランスクリプト、要約を経てメインの会話に戻る
memsearchのプログレッシブ検索フロー:検索、展開、トランスクリプト、要約を経てメインの会話に戻る
この「Markdownファースト」のパターンは、複数のセッション、モデル、エージェントをまたがって作業するチームにとって有用です。また、AIエージェントの長期記憶、共有マルチエージェント記憶、さらにはエージェントシステムにおけるコンテキストの劣化を防ぐというより広範な課題とも自然に連携します。
これらのツールはどのように連携するのでしょうか?
これら7つのツールは相互に補完し合うものであり、互いに置き換え可能なものではありません。それらを層として活用してください。
| レイヤー | これらのツールの活用方法 | 理由 |
|---|---|---|
| コマンドノイズを除去する | RTK | Claudeに送信される前に、大量のターミナル出力を圧縮します。 |
| サンドボックスへのツール生出力の出力 | コンテキストモード | 大規模なログ、DOM、およびツールのペイロードをメインの会話の外に保持する。 |
| コード構造のマッピング | code-review-graph | ファイルを盲目的に読み込むことなく、依存関係や影響範囲に関する質問に回答します。 |
| コードを段階的に読み込む | トークン・セイバー | シンボルの要約から始め、必要に応じてのみ展開する。 |
| Claudeの回答を圧縮する | Caveman | モデル自身の出力が将来のコンテキストを肥大化させないようにする。 |
| 関連するコードを取得する | claude-context | 繰り返しのgrepループの代わりに、セマンティック検索およびハイブリッドコード検索を使用する。 |
| 持続可能な決定を再利用する | memsearch | セッション、エージェント、モデルの切り替えをまたいでプロジェクトの履歴を呼び出す。 |
実用的な導入順序は以下の通りです:
- まず明らかなノイズを除去する。コンテキストがシェル出力やツールのペイロードで占められている場合は、RTKまたはコンテキストモードを追加する。
- リポジトリのナビゲーションを改善する。構造把握には code-review-graph を、意味的なコード検索には claude-context を追加する。
- 残す内容を制御します。Token SaviorやCavemanを使用して、ファイルの読み込みやモデルの応答をコンパクトに保ちます。
- 永続的な知識を保持する。繰り返しの説明がボトルネックになった場合は、memsearchを使用する。
連絡を取り合いましょう
- MilvusのDiscordコミュニティに参加して、質問をしたり、他の開発者とコンテキスト管理のパターンを比較したりしましょう。
- コード、メモリ、または RAG ワークロード向けの検索レイヤーの設計についてサポートが必要な場合は、無料の Milvus Office Hours セッションを予約してください。
- インフラのセットアップを省略したい場合は、Zilliz Cloud(マネージド版 Milvus)の無料プランを利用して、すぐに始められます。
よくある質問
有用なコンテキストを失わずに、Claude Codeのトークン使用量を削減するにはどうすればよいですか?
まず、ノイズの多い入力(ターミナル出力、生のツールペイロード、繰り返されるコードの読み取りなど)を圧縮することから始めましょう。次に、claude-context や code-review-graph などの検索ツールを追加し、Claude がリポジトリを一から探索するのではなく、関連するコードを直接取得できるようにします。
大規模なリポジトリでは、claude-contextとcode-review-graphのどちらを使うべきですか?
セマンティックなコード検索が必要な場合、特に正確なファイル名やシンボル名が分からない場合は、claude-contextを使用してください。呼び出し関係、インポート、テストの依存関係、レビューの波及範囲などの構造的な回答が必要な場合は、code-review-graphを使用してください。
Claude Codeにおける「メモリ検索」と「コード検索」は異なりますか?
はい。コード検索は、関連するプロジェクトファイルやシンボルを見つけ出します。記憶検索は、永続的な決定、ユーザー設定、デバッグ履歴、およびセッションをまたぐ教訓などを呼び出します。memsearchは記憶に焦点を当てており、claude-contextはコード検索に焦点を当てています。
これらのツールは、プロンプトのキャッシュやより大きなコンテキストウィンドウに取って代わるものですか?
いいえ。プロンプトのキャッシュや大きなコンテキストウィンドウは、処理能力やコストの面で役立ちますが、どの情報が注目に値するかを決定するものではありません。コンテキスト管理ツールは、そもそもモデルに入力される情報の質と密度を向上させます。
 cccm 11zon
cccm 11zon
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word