「Loon」を開発した理由:絶えず変化し続けるAIデータのためのストレージエンジン。
このブログ記事はもともとzilliz.comに掲載されたもので、許可を得て再掲載されています。
主なポイント
これは長文で詳細なエンジニアリング解説ですので、本題に入る前に重要なポイントをまとめておきます。
- AIデータセットは静的なテーブルではありません。チームが埋め込みモデルを置き換えたり、スパースベクトルを追加したり、キャプションを修正したり、ラベルをバックフィルしたり、インデックスを再構築したり、オフライン分析を実行したりするにつれて、同じ行の内容も絶えず変化し続けます。
- 従来のストレージレイアウトには、3つの問題点があります。長いベクトル列によりバックフィル処理のコストが高くなること、単一のファイル形式ではスキャンとポイントリードの両方に十分に対応できないこと、そしてプライベートデータベースストレージでは、外部パイプラインが「真実」の余分なコピーを作成せざるを得なくなることです。
- Loonは、MilvusおよびZilliz Vector Lakebase向けの新しいストレージエンジンです。これは、ハイブリッドファイル形式、行IDのアラインメント、およびデータセットのバージョン管理された状態を定義するマニフェストを中核として構築されています。
- その目的は、データの絶え間ないコピー、書き換え、再インポートを行うことなく、単一のベクトルデータセットでオンライン検索、オフライン分析、バックフィル、コンパクション、および外部計算をサポートできるようにすることです。
はじめに
かつて、ベクトルデータベースに対する「もっともらしい」反論が一つありました。
従来のデータベースはすでに整数、文字列、JSON、BLOB、インデックスを格納しています。そこで、 _vector_ 型を追加し 、その横にANNインデックスを構築して、それで済ませればよいのではないか、というものです。
初期のセマンティック検索においては、その方法でも十分に機能します。ベクトル列とインデックスがあれば、デモや小規模なRAGアプリケーション、あるいは社内検索機能を実現できます。問題は、データセットがテーブルというよりAIデータシステムのような振る舞いを見せ始めた段階で顕在化します。
本番環境のベクトルデータセットには、行、主キー、スカラーフィールド、およびクエリ可能なカラムがあります。その意味では、データベースのテーブルのように見えます。 しかし、データレイクのような規模とワークフローの形態も併せ持っています。数億件ものレコードが含まれている可能性もあります。Spark、Ray、DuckDB、トレーニングパイプライン、評価ジョブ、データ品質管理システムによって、繰り返し読み込まれ、書き換えられます。
また、オブジェクトストレージにも依存しています。ソースオブジェクトは、多くの場合、S3、GCS、OSS、またはその他のオブジェクトストアに残された動画、画像、PDF、音声ファイル、Webドキュメントなどです。 データベースには、参照情報、メタデータ、派生特徴量、インデックスが格納されます。さらに、従来のストレージモデルでは管理するよう設計されていなかった要素を、第一級のオブジェクトとして追加します。具体的には、高密度埋め込み、疎ベクトル、キャプション、ベクトルインデックス、テキストインデックス、削除ログ、統計情報、モデルバージョン、パーサーバージョン、外部BLOBへの参照、そしてこれらすべて間のバージョン関係などです。
ここで、「単にベクトル列を追加する」というアプローチが通用しなくなってきます。問題は、データベースがベクトルバイトを格納できるかどうかではありません。多くのシステムでそれは可能です。より難しい問題は、そのストレージモデルが、ベクトルデータの変更方法、クエリの実行方法、そしてAIデータスタック全体での共有方法を適切に処理できるかどうかです。
これが、Milvusおよび Zilliz Vector Lakebase (Zilliz Cloudの次世代版)向けの新しいストレージエンジン「Loon」を開発した理由です 。
Loonは、以下の3つの考え方を基に設計されています:
- 列の種類に応じて異なる物理フォーマットを使用する。
- 共有の行ID空間を通じて、それらのカラムを整合させる。
- マニフェストを使用して、データセットのバージョン管理された状態を定義する。
これらの要素がなぜ重要なのかを理解するために、一般的なマルチモーダルワークフローから見ていきましょう。
ベクトルデータセットは、決して「完成」することはありません。
マルチモーダル学習用の動画データセットを構築している AI チームを想像してみてください。
長い動画がオブジェクトストレージにアップロードされます。パイプラインが、シーンの変化、ショットの境界、または時間ウィンドウに基づいて、その動画をクリップに分割します。長すぎたり短すぎたり、ぼやけていたり、重複していたり、画質が低すぎるクリップは除外されます。 残ったクリップは、審美性モデルによって評価され、別のモデルによってキャプションが付けられ、ビジョン・言語モデルによって埋め込みが行われ、検索、重複排除、およびトレーニングデータのフィルタリングのためにベクトルデータベースに保存されます。
大まかに言えば、このワークフローは単純に見えます:
video
→ clips
→ metadata
→ aesthetic_score
→ caption
→ embedding
→ search / dedup / training data filtering
しかし、データセットは最初から完全な形で届くわけではありません。
- 最初の週には、テーブルには
clip_id、video_id、start_offset、durationしか含まれていないかもしれません。 - 2週目には、チームが
aesthetic_scoreを追加します。 - 第3週には、キャプション生成モデルが実行され、各クリップに
captionが割り当てられます。 - 第4週には、最初の埋め込みモデルがオンラインになり、各クリップに768次元のCLIP埋め込みが割り当てられます。
- 1か月後、チームはモデルを切り替え、
embedding_v2(この時点で1024次元)をバックフィルします。 - 2 か月後、ハイブリッド検索が必須となったため、チームはスパースベクトル列を追加しました。
- 3ヶ月後、キャプションは人間によるレビューを受け、その場で修正が必要となりました。
このデータセットは完成することはありませんでした。同じ基となる行に対して、新たな解釈が絶えず蓄積され続けたのです。
これこそが、ベクトルデータと従来のビジネスデータとの根本的な違いの一つである。同じ行が何度も再処理されるのだ。そして、その規模の大きさゆえに、これは単なる不便さからストレージの問題へと発展する。マルチモーダルデータセットは、多くの場合、数百万件のレコードではなく、数億件あるいは数十億件に及ぶからだ。 LAION-5Bはその構成の参考例として有用だ――数十億組の画像とテキストのペアがあり、それぞれにメタデータ、キャプション、埋め込みベクトルが付随している。したがって、難しいのは最初の挿入ではない。難しいのは、データセットが進化し始めてから起こるすべての事象である。その進化によって、3つの問題が浮き彫りになる。
最初の問題:長い列は書き込み増幅のコストを高める
Parquetのようなカラム型フォーマットは、多くの分析ワークロードにおいて優れています。これらは、スキーマが比較的安定しており、データの読み取りが書き換えよりも頻繁に行われ、スキャンがカラムのサブセットのみに及ぶ場合、そして圧縮が重要となる場合にうまく機能します。多くの分析用フォーマットが最適化されてきたのは、まさにそのような環境です。
ベクトル行は、分析用行よりもはるかに幅が広い
TPC-H(lineitem )は良いベンチマークとなります。これには16の列があり、整数キー、小数値、日付、短い文字列、および小さなコメントフィールドが含まれます。 非圧縮の1行はおよそ150バイトです。圧縮後は、さらに大幅に小さくなる可能性があります。64 MBの行グループがあれば、ストレージシステムは数十万行を1つのグループに詰め込むことができます。
ベクトルデータセットは、そのような構造ではありません。
LAION形式の画像・テキストデータセットは、今日の多くのAIパイプラインが生成するデータに非常に近いものです。各行には依然として、URL、キャプション、幅、高さ、品質スコア、ラベルといった通常のメタデータが含まれています。しかし、埋め込みベクトルが追加されると、行の物理的な形状は変化します。
768次元のCLIPベクトルは、fp16で約1.5 KB、fp32で約3 KBの容量を占めます。この1列だけで、TPC-Hのlineitem 行全体よりもはるかに大きなサイズになる可能性があります。
しかも、768次元という規模は、今日の基準からすれば珍しくもなければ、大きいわけでもありません。マルチモーダルパイプラインでは、1024次元や2048次元の埋め込みが一般的です。OpenAIのtext-embedding-3-large は最大3072次元まで対応しており、これはfp32でベクトルあたり約12 KBに相当します。
その違いは歴然としています:
| データセットの形状 | おおよその行サイズ | 行の主な構成要素 |
|---|---|---|
| TPC-H ラインアイテム | 非圧縮で約150バイト | スカラーおよび短い文字列フィールド |
| 768次元のfp16ベクトルを含むLAION形式の行 | 約1.5 KB以上 | 埋め込み |
| 768次元のfp32ベクトルを含むLAION形式の行 | 約3 KB+ | 埋め込み |
| 3072次元のfp32ベクトルを含む行 | ベクトル単体で約12 KB+ | 埋め込み |
多くのAIデータセットにおいて、ベクトル列は単なるフィールドの一つではありません。物理的には、行の大部分を占めています。これにより、スキーマの進化にかかるコストが変わってきます。
ベクトル列を1つ追加するだけで、数百ギガバイトのデータ量になる可能性があります
あるデータセットに1億本の動画クリップがあると仮定します。新しい1024次元のfp32埋め込みカラムを追加すると、約400 GBの生ベクトルデータを書き込むことになります。これには、統計情報、インデックス、メタデータの更新、オブジェクトストレージのオーバーヘッド、検証、またはサービングパスとの統合は含まれていません。

チームが毎月、embedding_v2 、sparse_vector 、あるいは再ランク付け用特徴量といったベクトル型の列を1つまたは2つ追加する場合、スキーマの進化は、数百ギガバイトあるいはテラバイト規模の、繰り返し行われるデータエンジニアリング作業となります。
小さな論理的な更新が、大規模な物理的な書き換えを引き起こす可能性があります
更新も同様に重要です。
列指向システムでは、通常、古いデータはその場で更新されることはありません。削除ログに変更内容が記録され、その後、コンパクションによってライブ行が新しいファイルに書き換えられます。このモデルは、行が小さい場合には管理可能です。
ベクトルデータの場合、わずかな論理的な更新でも大規模な物理的な書き換えを引き起こす可能性があります。
人間によるレビュー作業では、キャプションのわずか数百バイトを修正するだけかもしれません。しかし、キャプション、密ベクトル、疎ベクトル、およびその他の派生特徴量が同じ物理ファイルのライフサイクルを共有している場合、システムはベクトルも書き換えてしまう可能性があります。論理的な変更は小さいのに、物理的なI/Oは膨大になる可能性があります。
これが、ベクトルストレージにおける「書き込み増幅」の問題です。コストがかかる要因は、単にベクトルが大きいということだけではありません。大きな派生フィールドと小さな可変フィールドが、ストレージのレイアウトによって1つの単位として扱われ、しばしば結びつけられてしまう点にあります。
AIデータセットにおいて、バックフィルは日常的なワークロードである
従来の分析用テーブルでは、スキーマの進化はたまにしか起こりません。しかし、AIデータセットでは、これは日常茶飯事です。キャプションモデルがアップグレードされます。埋め込みモデルが置き換えられます。スパースベクトルが後から追加されます。再ランク付け用の特徴量が現れます。人間によるラベルが修正されます。ガバナンスタグがバックフィルされます。インデックスが再構築されます。
これらの操作は単なる追加処理ではありません。多くの場合、既存の行を変更または拡張するものです。
そのため、ベクトルストレージはスキャンスループットの最適化だけでは不十分です。バックフィルや部分更新のコストも低減しなければなりません。
2つ目の問題:同一のデータがスキャンとポイント読み取りの両方をサポートしなければならない
データの書き込み後、読み取りパスは分岐します。同じベクトルデータセットには通常、分析用スキャンとポイント読み取りという2つの異なるアクセスパターンが存在します。
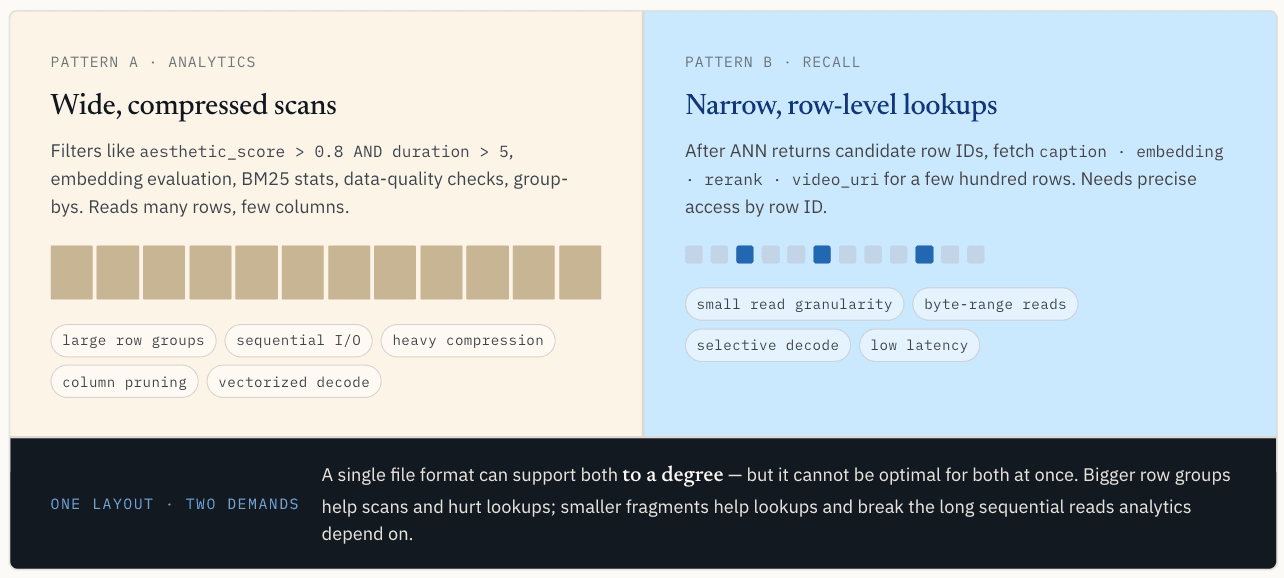
分析ワークロードでは、広範囲かつ圧縮されたスキャンが求められます
パイプラインでは、次のようなフィルタが実行される場合があります:
WHERE aesthetic_score > 0.8 AND duration > 5
あるいは、オフライン分析、完全な埋め込み評価、BM25統計、ビットマップ構築、データ品質チェック、カウント、グループ化などを実行する場合もあります。
このパターンでは、多くの行を読み込む一方で、読み込む列はわずかです。このパターンでは、シーケンシャルI/O、大きな行グループ、圧縮、列の剪定、バッチデコード、およびベクトル化された実行が適しています。
ここでは、行グループを大きくすることが有効です。これにより、1回のI/Oリクエストで大量の有用なデータを取得でき、圧縮効率が向上し、実行エンジンにオーバーヘッドを償却するのに十分な連続したデータを提供できます。複数の列をまとめて読み込む場合、スキャンスループットのためにそれらを整理しておくことは、ベクトル化実行中のキャッシュミスを減らすのにも役立ちます。
Parquetはこの点で優れています。
ANNの結果には、行レベルの狭い範囲の検索が必要
ANN検索によって候補となる行IDが返された後、システムは次のようなフィールドを取得する必要がある場合がしばしばあります:
caption
embedding
rerank feature
video_uri
metadata
このパターンでは、読み込まれる行数は少なく(多くの場合、数百行から数千行程度)、行IDによる正確なアクセスが必要です。特定の行と列を特定し、必要なバイト範囲のみを取得し、わずかなレコードを取得するためだけに 行グループ全体を読み込むことを避けたいのです。
ポイント検索では、スキャンに対する優先順位がほぼ正反対になります。読み取りの粒度を小さくすることが求められます。理想的には、ストレージ層が行IDによって関連するセグメントやバイト範囲を特定し、その範囲のみを読み取り、結果に必要なデータのみをデコードできるようにすることです。
圧縮についても、異なるトレードオフが存在します。スキャンでは、システムが大量のデータを読み込み、I/Oを節約できるため、より強力な圧縮を行う価値があることがよくあります。一方、ポイント検索では、1行を取得するために、はるかに大きな圧縮ブロックのデコードが必要になる場合があり、圧縮が逆効果になる可能性があります。
1つのレイアウトで両方の処理経路を最適化することはできない
これが根本的な矛盾です。スカラーフィルタリングや分析には、幅広で圧縮され、スキャンに適したレイアウトが求められます。一方、ベクトル検索には、幅が狭く、正確で、行単位でアドレス指定可能なレイアウトが求められます。
単一のファイル形式は、ある程度は両方をサポートできますが、同時に両方に最適であることはできません。
すべての列がParquetに格納されている場合、スカラースキャンは快適に実行できます。しかし、リコール後のANNルックアップは困難になります。システムが必要とするのは数百個のベクトル、キャプション、またはメタデータレコードだけであるのに対し、ストレージ層は、ほとんどが関係のない行を含む大規模な行グループを読み取らなければならない場合があります。
ローカルのSSD上では、キャッシュやmmapによってこのコストの一部を隠蔽できます。しかし、データがオブジェクトストレージに格納されると、そのコストがより顕在化します。キャッシュミスが発生するたびに、リモート範囲読み取りが発生する可能性があります。候補行が多くの行グループに散在している場合、1つのクエリが複数の読み取りをトリガーし、それぞれがクエリに必要な量以上のデータを読み込んでしまうことがあります。 レイアウトが不適切な場合、1,000件の候補行を取得するだけで、数十~数百メガバイトの不要なI/Oが発生しやすく、極端なケースではそれ以上の量になることもあります。
行グループを小さくするとポイント検索には役立ちますが、スキャンには悪影響を及ぼします。小さな断片が多すぎると、圧縮効率が低下し、メタデータのオーバーヘッドが増加し、分析エンジンが依存する長い連続読み取りが妨げられます。
したがって、問題は「魔法のような最適な行グループサイズ」を1つ見つけ出すことではありません。問題は、同じデータセットに対して、2つの異なるストレージシステムのような振る舞いが求められている点にあります。
ハイブリッド検索は、これら2つの処理パスを1つのクエリに統合します
ハイブリッド検索は、この矛盾を無視しにくくします。単一のクエリでは、まずスカラーフィルタが適用される場合があります:
aesthetic_score > 0.8 AND duration > 5
その後、ANN検索を実行します。
続いて、行IDに基づいてキャプション、ベクトル、メタデータを取得します。
ユーザーにとっては、これは1つの検索リクエストです。しかし、ストレージ層にとっては、これは分析スキャンであると同時に、低遅延のランダム検索でもあります。
だからこそ、ベクトルストレージには、Parquetの設定を改善するだけでは不十分です。実際に読み込まれる方法に応じて、異なる列を配置する仕組みが必要です。
3つ目の問題:データセットが単一のエンジン内に存在しないこと
最初の2つの問題はデータベース内部で発生します。3つ目の問題は、システム間の境界で発生します。

AIデータパイプラインは多くのシステムにまたがっている
動画ワークフローにおいて、ベクトルデータベース自体で行われる処理はごくわずかです。
生の動画データはオブジェクトストレージに格納されています。クリップの生成はSparkやRayで実行されるかもしれません。美的評価はGPUサービスで実行されるかもしれません。キャプション生成はLLM推論パイプラインで実行されるかもしれません。埋め込みベクトルは別のGPUジョブによって生成されるかもしれません。スパースベクトルはSPLADEサービスから提供されるかもしれません。 オフライン評価、トレーニングデータのフィルタリング、人間によるレビュー、ガバナンス関連のジョブは、すべて別の場所で実行される可能性があります。
ベクトルデータベースはオンライン検索を提供しますが、データセットの作成、修正、評価、拡張は多くのシステムによって行われます。
独自のストレージ形式は「真実」の複数のコピーを生み出す
データベースが、それ自体でしか読み書きできない独自の物理フォーマットを使用している場合、外部のジョブごとにエクスポート、変換、コピー、インポートが必要になります。同じコレクションが、データベース内、Sparkの一時ディレクトリ、評価出力、ローカルのバックフィルディレクトリに存在することがあります。そこで、真の問題は次のようになります:
- どのコピーが「真実の源」なのか?
- どのコピーに先月のキャプションモデルが含まれているのか?
- どの行がすでに人的レビューによって修正済みなのか?
- どのスパースベクトル列が、どのモデルによって生成されたのか?
- バックフィル後も有効なベクトルインデックスはどれか?
- この行はどの元の動画オブジェクトを指しているのか?
小規模な環境であれば、命名規則や手動チェックだけでチームが何とかやりくりできる場合もあります。しかし、数億行のデータとテラバイト規模の埋め込みデータとなると、これは一貫性の問題となります。
ベクトルデータセットには、バージョン管理された共有状態が必要です
レイクハウス・システムは、構造化データにおけるこの問題の一形態に対処しました。Iceberg、Delta Lake、Hudiは、単にファイルを保存するだけのものではありません。それらの核心的な貢献は、複数のエンジンが同じテーブルの状態を基に連携できるようにすることです。
ベクトルデータベースにも同様の機能が必要ですが、その状態はより複雑です。テーブルファイルやパーティションだけでなく、ベクトルインデックス、テキストインデックス、スパース特徴量、削除ログ、統計情報、行IDの範囲、外部BLOBへの参照なども含める必要があります。
問題は単に「SparkはMilvusファイルを読み込めるか?」というだけではありません。
真の問いは、Sparkがスパースベクトル列をバックフィルした後、Milvusが「その列がどのバージョンに属するか」「どの行をカバーしているか」「どのモデルによって生成されたか」、そして「オンラインクエリがいつ安全にそれを利用できるか」を、どのように把握するかということです。
その答えは、ストレージモデルの中に存在しなければならない。
なぜパッチだけでは不十分なのか
これらを3つの別々の技術的課題として扱いたくなるかもしれません。
- 書き込み増幅? バッチ処理を追加すればよい。
- ポイント読み取り? キャッシュを追加する。
- 外部システム? エクスポートおよびインポートツールを追加すればよい。
こうしたパッチは役立つかもしれませんが、根本的な問題、すなわちベクトルデータセットが物理的に異種であるという事実には対処していません。

ビデオの例(clip_id )では、video_id 、duration 、およびaesthetic_score は短いスカラーフィールドです。これらはフィルタリングや分析に役立ちます。
captionはテキストです。BM25、レビュー、修正、およびバックフィルに使用される可能性があります。embeddingは、長くて密なベクトルです。ANNのリコールに使用され、その後、行レベルの検索や再ランク付けに使用されます。embedding_v2は新しいモデル出力であり、多くの場合、元のデータが挿入されてからかなり時間が経過した後にバックフィルされます。sparse_vectorハイブリッド検索をサポートしており、独自のアクセスパターンを持っています。- 生の動画データはオブジェクトストレージに保存しておくべきです。データベースには、参照、チェックサム、MIMEタイプ、パーサーのバージョン、および行レベルの関連性を格納する必要があります。
- ベクトルインデックス、テキストインデックス、統計情報、および削除ログは、独自のバージョンセマンティクスを持つ派生オブジェクトです。
これらのオブジェクトは論理行を共有しますが、すべてが同じ物理レイアウトやライフサイクルを共有する必要はありません。
- これらを 1 つの通常のテーブルレイアウトに強制的に収めると、更新のコストが高くなります。
- これらを 1 つの列指向ファイル形式に強制的に収めると、ポイント読み取りのコストが高くなります。
- これらを無関係なオブジェクトファイルとして扱うと、バージョン管理が不安定になります。
したがって、ストレージモデルは、データセットが異種であるという事実に基づいて構築されなければなりません。
そこから、3つの設計要件が導き出されます。
- 第一に、異なるカラムグループは、それぞれ異なる物理フォーマットで格納されるべきです。
- 第二に、それらの列グループには共有の行ID空間が必要であり、それによって単一の論理テーブルとして動作し続けられるようにする。
- 第三に、データセットには、どのファイル、インデックス、ログ、統計情報、およびオブジェクト参照が現在のビューに属するかを宣言する、バージョン管理されたマニフェストが必要です。
これが、MilvusおよびZilliz Cloudを支える当社の新しいストレージエンジン「Loon」の設計思想です。
Loon:進化するベクトルデータセットのための、MilvusおよびZilliz Cloudを支えるストレージエンジン
上記のすべての問題を解決するため、我々は、進化するベクトルデータセット向けに設計された、MilvusおよびZilliz Vector Lakebase(Zilliz Cloudの次なる進化形)用の新しいストレージエンジン「Loon」を開発しました。
この名前は、Zillizの「鳥にちなむ命名」の伝統に則ったものです。ルーン(loon)は湖に生息する潜水性の鳥であり、これはシステムの目標とよく符合しています。つまり、ベクトルデータベースは、クエリを実行したり、カラムをバックフィルしたり、インデックスを構築したりするたびに、データという「湖」全体を移動、スキャン、または書き換える必要があってはならないのです。 まず、列、インデックス、統計情報、削除ログ、オブジェクト参照など、現在のデータセットのバージョンを把握し、実際に必要な部分のみを読み込むべきです。
ハイブリッドファイル形式、行IDのアラインメント、およびマニフェストは、3つの別々の機能ではありません。これらはすべて、ベクトルデータセットは本質的に異種混在であるという同じ設計上の前提に由来しています。
3つの要素、1つのストレージモデル
ハイブリッドファイル形式は、列ごとにアクセスパターンが異なることを認識しています。スカラーフィールドはスキャンやフィルタリングに適しています。ベクトルフィールドには、効率的な行レベルの検索が必要です。動画、PDF、画像、音声ファイルなどの生データは、データベースのデータファイル内ではなく、オブジェクトストレージに格納されるべきものです。
行IDの整合性は、これらの列が物理的には分離されているものの、依然として同じ論理行を表していることを認識しています。キャプション、埋め込みデータ、スパースベクトル、動画URIは、異なるファイルや形式で保存されているかもしれませんが、単一の結果として統合される必要があります。
マニフェストは、データセットが一度書き込まれたらそのまま放置されるものではないことを認識しています。データセットは、複数のシステムによって、複数のバージョンにわたり、複数のタスクのために変更されます。インデックス、統計情報、削除ログ、外部オブジェクトへの参照、およびカラムグループは、すべて同じバージョン管理されたビューに表示される必要があります。
これが、Loonが単なる高速なベクトルファイル形式ではない理由です。高速な形式はポイント検索には役立ちますが、スキーマの進化やマルチエンジンの連携の問題を解決するものではありません。行IDの整合性により、分割された列を単一のテーブルとして扱うことは可能ですが、どのファイルが現在のバージョンに属するかを指定するものではありません。 マニフェストはデータセットの状態を記述できますが、カラムグループと行IDの整合性がなければ、1つの論理コレクション内の異なる物理レイアウトを明確に表現することはできません。
ストレージモデルには、これら3つの要素すべてが必要です。すなわち、列グループごとに異なるフォーマット、行を再構築するための共有行ID空間、そしてすべての読み取り側および書き込み側にデータセットの現在の状態を伝えるバージョン管理されたマニフェストです。
LoonがMilvusおよびZilliz Vector Lakebaseにおいて果たす役割
Milvusでは、従来のセグメント・ビンログ・ストレージ層を、マニフェスト、ColumnGroup、ファイル形式、およびファイルシステムの抽象化を中核とするモデルに置き換えています。Zilliz Vector Lakebase(Zilliz Cloudの次期バージョン)においても、Vector Lakebaseアーキテクチャには同様の方向性が適用されます。つまり、ベクトルデータベースのサービス提供経路を高速に保ちつつ、基盤となるデータの進化、分析、および外部システムとの連携を容易にするというものです。
上位レベルのMilvusコンポーネントは、従来通りの役割を維持しています。Proxyがルーティングを処理し、QueryCoordとDataCoordがスケジューリングを処理し、IndexNodeがインデックスを構築します。コレクション、挿入、検索、ハイブリッド検索のためのアプリケーション向けAPIは、ManifestファイルやColumnGroupを公開する必要はありません。
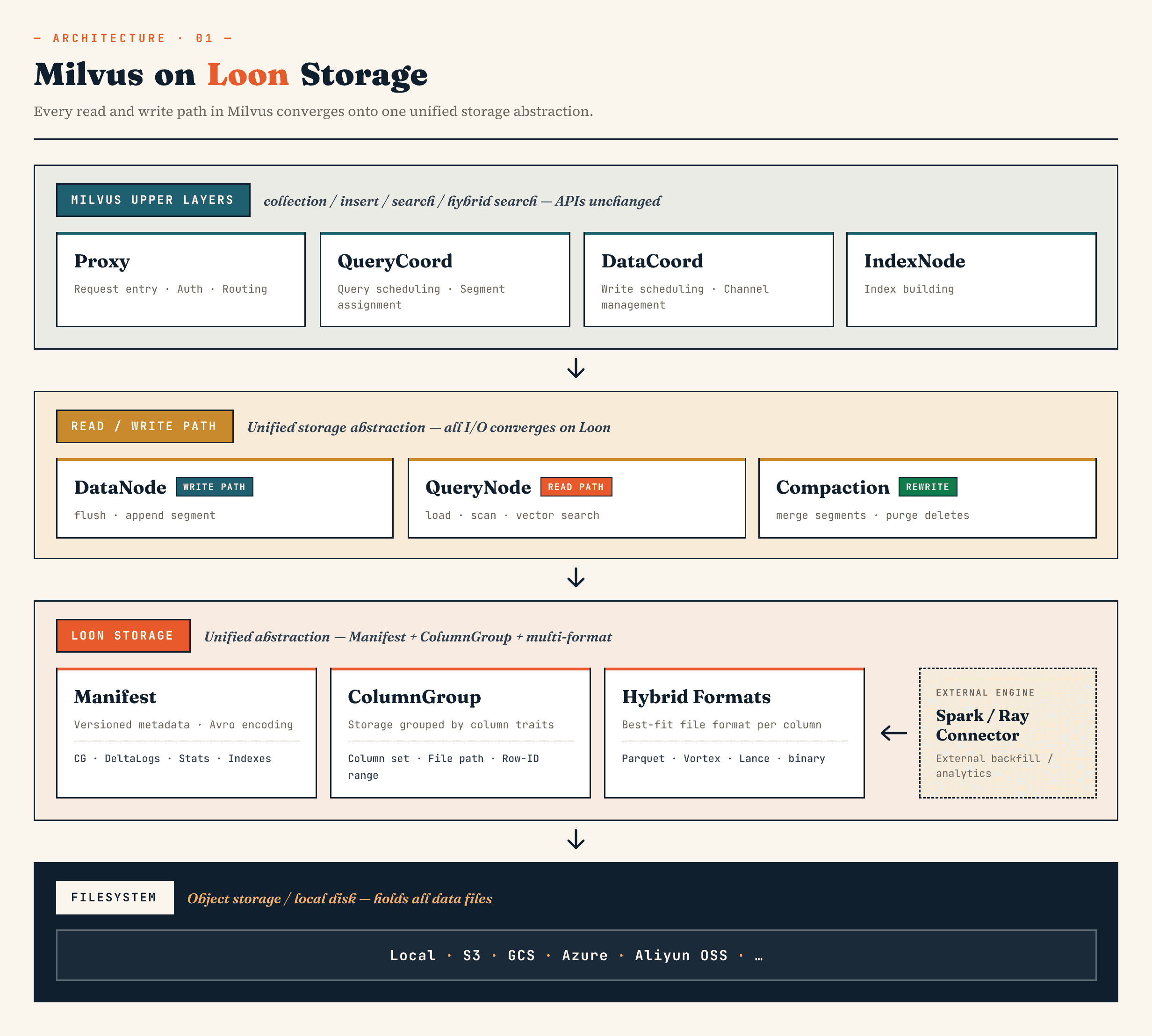
変更点は内部構造にあります。
DataNode、QueryNode、segcore、コンパクション、および外部コネクタは、同じストレージ抽象化を通じて動作できます。これは、データセットがもはやデータベースによってのみ書き込まれ、読み込まれるわけではないため重要です。データセットは、外部のコンピューティングシステムによって拡張されると同時に、オンライン検索によって利用される可能性があります。
大まかに言えば、各レイヤーの構成は次のようになります:
Manifest
→ ColumnGroup
→ file format layer
→ filesystem abstraction
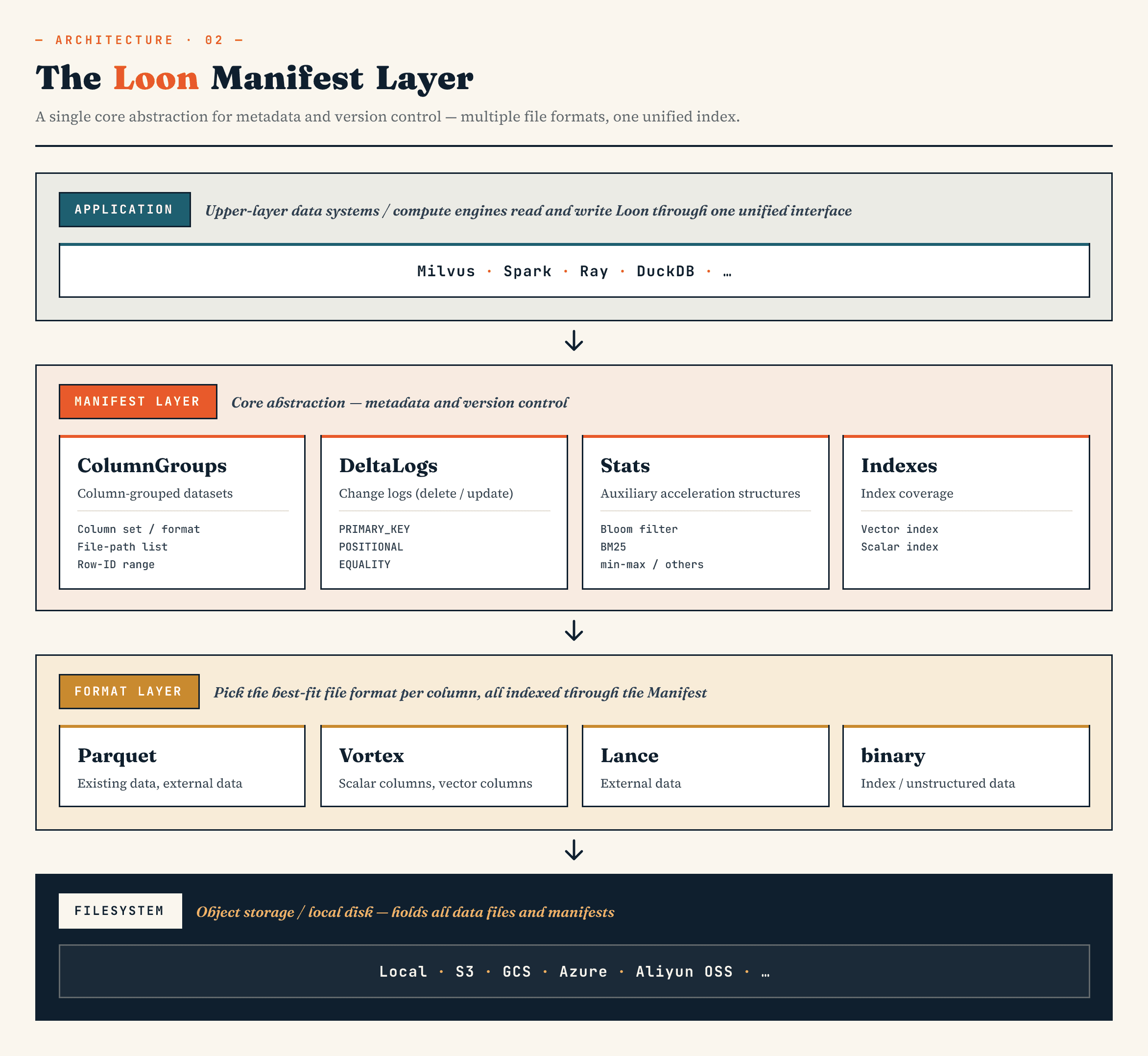
マニフェストは、データセットのバージョン管理された状態を記述します。ColumnGroupsは、論理的なコレクションを物理的なカラムグループにマッピングします。ファイル形式レイヤーにより、各ColumnGroupは適切な形式を選択できます。ファイルシステム抽象化は、オブジェクトストレージとローカルストレージの両方で機能します。
重要な点は、ハイブリッドファイル形式、行IDのアラインメント、およびマニフェストが独立した機能ではないということです。これらが一体となって、ストレージモデルを定義しています。
このモデルを前提として、3つの設計上の選択事項を1つずつ検討することができます。すなわち、Loonが異なるColumnGroupsをどのように保存するか、それらを行に再配置するか、そしてマニフェストがそれらのファイルをどのようにバージョン管理されたデータセットに変換するか、という3点です。
設計 1: 適切な ColumnGroup に適切なファイル形式を使用する
列ごとにアクセスパターンは異なります。それらを無理に同じファイル形式に統一すべきではありません。
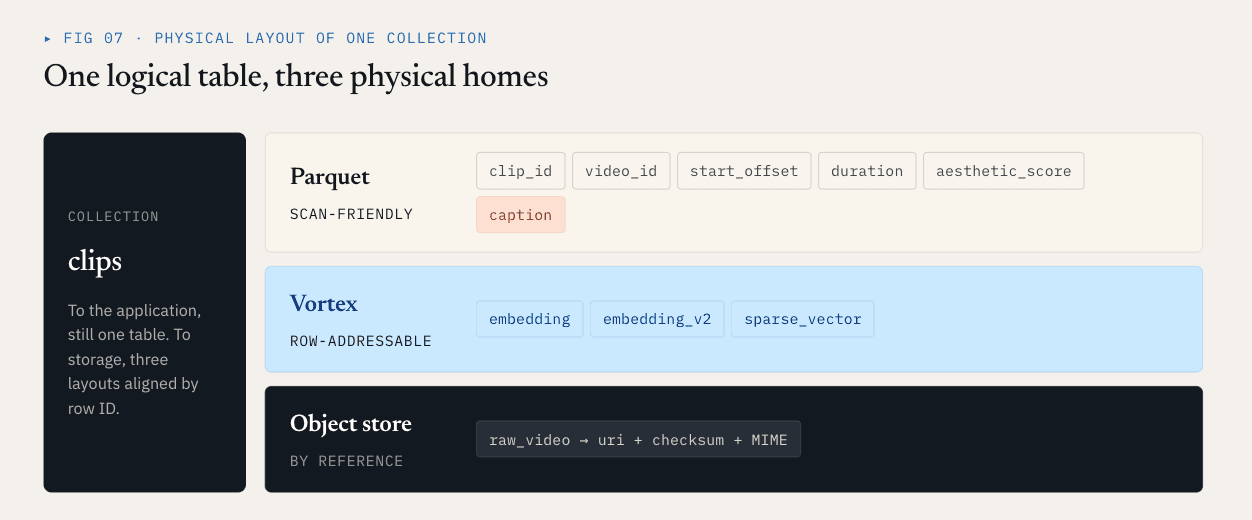
Loonは、論理的なコレクションをColumnGroupsに分割します。
- スカラーフィールド、フィルターフィールド、ビジネスキー、統計フィールドは、スキャン、フィルタリング、集計、またはクエリプランニングに頻繁に使用されます。これらは、圧縮、カラムプルーニング、およびエコシステムとの互換性の恩恵を受けます。Parquetは、これらのカラムに適しています。
- 密ベクトル、疎ベクトル、およびリランク特徴量は、多くの場合、ANNによる行IDでのリコール後に読み込まれます。これらには、低遅延のランダムアクセス、正確なバイト範囲読み取り、および選択的デコードが必要です。セグメント指向のレイアウトの方が適しています。Loonはこの目的でVortexを使用しています。
- 動画、PDF、画像、音声ファイルなどの生データオブジェクトは、ベクトルデータベースのデータファイルに埋め込むべきではありません。これらはオブジェクトストレージに残しておく必要があります。データベースは、参照情報、チェックサム、MIMEタイプ、パーサーのバージョン、および行レベルの関連性を記録します。
動画の例の場合、物理的なレイアウトは次のようになるでしょう:
Parquet ColumnGroup:
clip_id / video_id / start_offset / duration / aesthetic_score / caption
Vortex ColumnGroups:
embedding
embedding_v2
sparse_vector
Object storage:
raw video objects
アプリケーションにとっては、これは依然として単一のコレクションです。ストレージ層にとっては、そのコレクションの異なる部分が異なる物理フォーマットを使用しています。これにより、不要な書き換えが直接削減されます。embedding_v2 を追加することは、新しいベクトルColumnGroupとマニフェストのコミットで済みます。キャプション列、スカラーメタデータ、または既存の埋め込み列を書き換える必要はありません。
この考え方は、スパースベクトル、リランク特徴量、その他の派生フィールドにも適用されます。新しいカラムが物理的に独立しており、行IDによってアラインメントが取れる場合、無関係なカラムを同じ書き換えパスに巻き込む必要はありません。
Loonはファイル形式の活用方法も適応させています。
Parquetの場合、ベクトルが大量に含まれるデータに対して、デフォルト設定が常に最適とは限りません。64 MBの行グループは、ポイント検索には大きすぎる場合があります。なぜなら、小さなランダム読み取りでも、必要以上のデータが読み込まれてしまう可能性があるからです。Loonは、関連するパスにおいて行グループを1 MBに縮小し、ランダムなベクトルデータの検索に役立たない場合は、ベクトル列の辞書エンコーディングなどのエンコーディングを無効にします。
Vortex の場合、より重要なのはレイアウトです。Loon は、スキャン効率とポイント検索のバランスをとったレイアウトを採用しています。行グループ内では、スキャンを効率化するために、関連する列のセグメントを互いに近くに配置することができます。操作を実行する際、サブセグメント読み取りにより、システムはセグメント全体を取得するのではなく、関連するバイトのみを取得することができます。
また、Loonは読み取り専用のLance統合もサポートしているため、互換性が重要な場合には、既存のLanceデータセットをColumnGroupsとしてマウントできます。
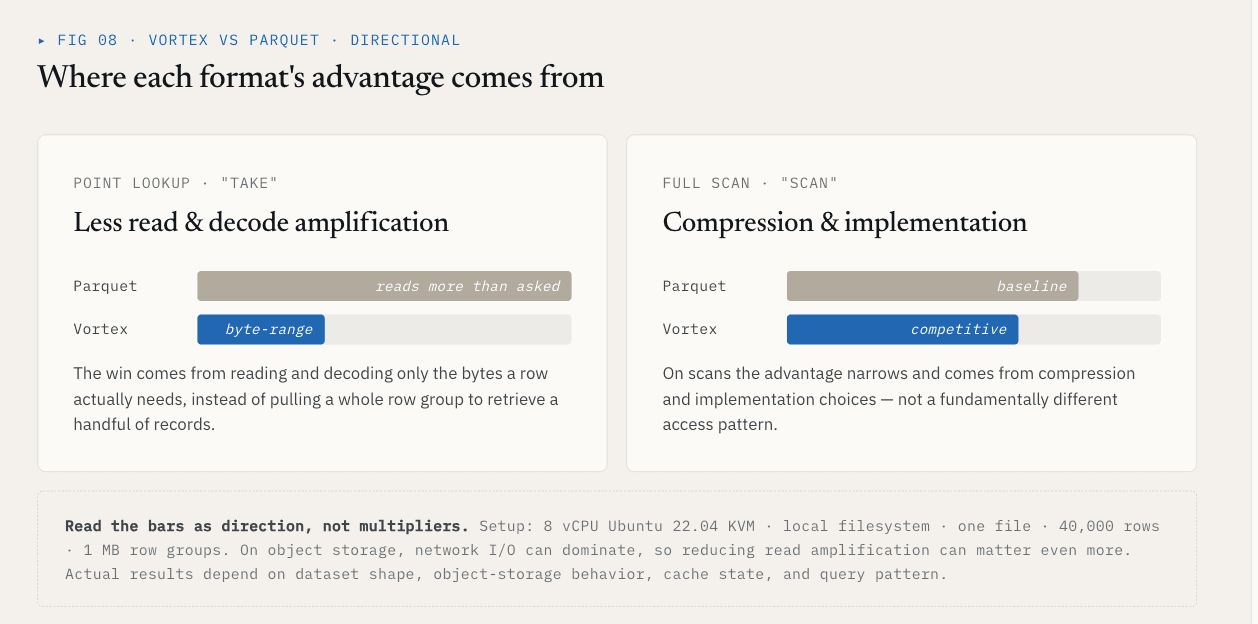
ベンチマークが示すもの
あるローカルテストでは、40,000行の単一ファイルとスキーマ{id: int64, name: utf8, value: float64, vector: list<float32>[128]} を使用し、Vortexが1 MBの行グループを持つParquetと比較して以下の結果を示しました:
| 操作 | Vortex | Parquet | 差 |
|---|---|---|---|
| 取得(K=1,000行のランダムな行) | 5.8 ms | 144 ms | 25倍速い |
| ベクトル・カラムスキャン全体 | 21 ms | 142 ms | 6.76倍高速 |
| ファイルサイズ、生データ約21 MB | 6.62 MB | 7.16 MB | 7% 縮小 |
take の結果は、読み込みおよびデコードが必要な無関係なデータの量を削減したことによるものです。スキャン結果は、圧縮および実装の選択によるものです。
これらの数値は、以下の設定に紐づいたものであることに留意してください:8 vCPU、Ubuntu 22.04 KVM、ローカルファイルシステム、1つのファイル、40,000行、1 MBの行グループ、および上記のスキーマ。 オブジェクトストレージでは、ネットワークI/Oが大きな割合を占める可能性があるため、読み取り増幅の低減はさらに重要になる場合があります。実際の結果は、データセットの形状、オブジェクトストレージの挙動、キャッシュの状態、およびクエリパターンによって異なります。
より広い観点で言えば、すべてのカラムでVortexを使用すべきだというわけではありません。
重要なのは、ベクトルデータセットには ColumnGroup レベルでのファイル形式の選択が必要だということです。
設計 2: 行 ID を通じて物理ファイルを整合させる
ハイブリッドファイル形式は、ある問題を解決します。つまり、異なる列を、それぞれに最適な形式で格納できるようになるということです。
しかし、それによって 2 つ目の問題が生じます。スカラーフィールドが Parquet に、ベクトルが Vortex に、生オブジェクトがオブジェクトストレージに格納されている場合、システムはそれらをどのようにして 1 つのコレクションとして扱うのでしょうか?
Loonは、行IDの整合によってこの問題を解決します。
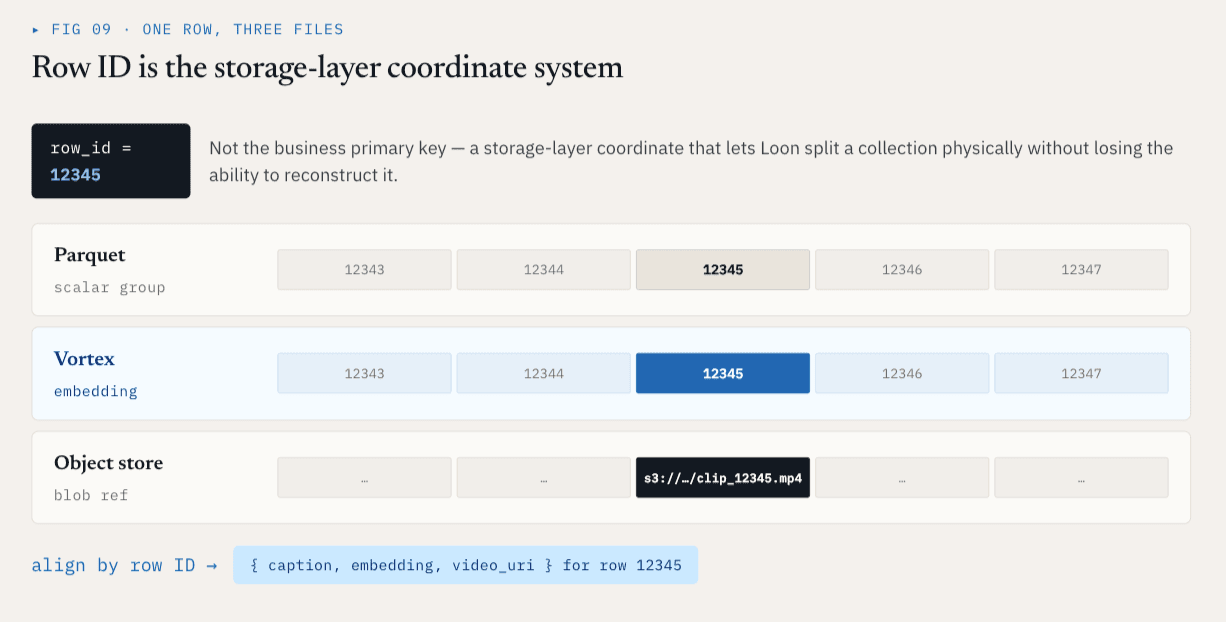
行IDはストレージ層の座標系です
各物理 ColumnGroupFile は、ファイルパスと、それがカバーする行 ID の範囲を記録します:
path
start_index
end_index
異なるColumnGroupであっても、たとえ異なるファイルやフォーマットに格納されていても、同じ行IDの範囲をカバーすることが可能です。
行ID12345 の場合、スカラーメタデータはParquetのColumnGroupに、エンベディングはVortexのColumnGroupに、生の動画データはオブジェクトストレージへの参照として格納されている可能性があります。論理的には、これらは依然として1つの行です。これにより、ストレージ層に安定した座標系が提供されます。
行IDはビジネス上の主キーではありません。これは、Loonがコレクションを物理的に分割しても、論理的に再構築する能力を失わないようにするための、ストレージ層の座標系です。
新しいカラムを追加しても、既存のカラムを書き換える必要はありません
embedding_v2 を追加する場合、元のキャプション、メタデータ、またはembedding_v1 のColumnGroupを書き換える必要はありません。Loonは新しいベクトルColumnGroupを書き込み、それがカバーする行IDの範囲を記録し、マニフェストを通じてその変更をコミットできます。
これは、スパースベクトル、再ランク付けされた特徴量、または後で追加されるその他の派生フィールドについても同様です。
新しい ColumnGroup が正しい行 ID 範囲をカバーしている限り、無関係なデータの移動を強制することなく、同じ論理コレクションに結合することができます。
削除や圧縮をより的を絞って実行可能
行 ID の整列は、削除にも役立ちます。
削除は、まず削除ログを通じて表現されます。その行は論理レベルでは見えなくなりますが、物理的なクリーンアップはコンパクションまで延期されます。最終的にコンパクションが実行される際、影響を受ける行に関連付けられたすべての ColumnGroup を書き換える必要は必ずしもありません。クリーンアップが必要な ColumnGroup に焦点を当てることができます。
これは、すべての列が同じコストプロファイルを持つわけではないため重要です。短いスカラーColumnGroupの書き換えは、数百ギガバイトに及ぶ高密度ベクトルの書き換えとは大きく異なります。
ハイブリッド検索は、必要な列のみを取得できます
行IDのアライメントもまた、ハイブリッドファイル形式上でハイブリッド検索を実用的なものにしている要因です。
ANN検索が候補となる行IDを返した後、システムは最終結果に必要なフィールド(キャプション、メタデータ、ベクトル、再ランク付け用特徴量、またはオブジェクト参照)のみを取得できます。
たとえば、クエリでは以下のフィールドが必要になる場合があります:
caption
embedding
video_uri
これらのフィールドは、異なるColumnGroupに存在する場合があります。Loonは、行IDの範囲に基づいて関連するファイルを特定し、必要なバイト範囲を読み取り、結果を組み立てることができます。
行IDの整合性がなければ、ハイブリッド形式は単に並列に配置された個別のファイルに過ぎません。行IDの整合性があることで、それらは単一の論理コレクションとして振る舞います。
Packed Readerは、上位層に対して分割を隠蔽します
これを実現するランタイムコンポーネントが「Packed Reader」です。
上位層からは、統一されたArrow RecordBatchストリームとして認識されます。その下層では、データは異なるファイル形式の複数のColumnGroupから取得される場合があります。Packed Readerはこれらの違いを隠蔽し、行IDの範囲ごとにデータを整列させ、メモリ使用量を制御しながらマルチファイルI/Oをスケジューリングします。
また、行IDによる直接的なtake もサポートしています。行IDのセットが与えられると、関連するColumnGroupFilesを特定し、範囲読み取りを実行して、要求されたフィールドを返します。
動画ワークフローの場合、ANNクエリではcaption 、embedding 、およびvideo_uri が必要になることがあります。Packed Readerは、無関係な列に触れることなく、スカラーColumnGroupおよびベクトルColumnGroupを取得できます。
これが、「個別のファイル」と「複数の物理レイアウトを持つテーブル」の違いです。
設計 3: マニフェストを「真実の源」とする
ハイブリッドファイル形式は、データが物理的にどのように格納されるかを定義します。行IDのアライメントによって、分離されたColumnGroupがどのようにして単一の論理テーブルを形成するかが決まります。しかし、システムにはさらに大きな問いへの答えが求められます。それは、どのファイル、ログ、統計情報、インデックス、およびオブジェクト参照が、データセットの現在のバージョンに属しているのか、ということです。それがマニフェストの役割です。

オブジェクトストレージのディレクトリだけでは不十分
オブジェクトストレージはデータベースカタログではありません。ディレクトリには、古いファイル、新しいファイル、失敗したジョブの出力、一時ファイル、削除ログ、古いスナップショットからまだ参照されているファイル、クリーンアップ待ちのファイルなどが含まれている可能性があります。ファイルが存在するという事実だけでは、それが現在のデータセットのバージョンに属しているとは限りません。
Loonデータセットは、次のようなディレクトリ構造で整理されている場合があります:
_metadata/
_data/
_delta/
_stats/
_index/
しかし、ディレクトリ構造は「真実の源」ではありません。「マニフェスト」こそが真実の源です。読者はディレクトリを列挙し、たまたま存在するファイルから状態を推測すべきではありません。現在のマニフェストを読み、そこに宣言されているバージョン管理されたビューに従うべきです。
マニフェストは、データセットのバージョン管理されたビューを定義します
マニフェストは、特定のバージョンにおけるデータセットを定義します。そこには以下が記録されています:
- どのColumnGroupが存在するか
- それらがどの行IDの範囲をカバーしているか
- 各ColumnGroupが使用する物理フォーマット
- ファイルの保存場所
- どの削除ログが有効か
- 利用可能な統計情報
- どのインデックスが存在するか
- どの外部BLOBが参照されているか
- それらの統計情報やインデックスがどの列および行範囲をカバーしているか
更新が行われるたびに、新しいマニフェストバージョンが書き込まれます。バージョン N を開いた読み取りユーザーは、バージョン N 時点でのデータセットの安定したビューを確認できます。書き込みユーザーは、まだバージョン N を使用している読み取りユーザーに支障をきたすことなく、バージョン N+1 を準備することができます。
マニフェストはテーブルファイル以上の情報を追跡します
Loonでは、マニフェストの本文はApache Avroでエンコードされ、4つの主要なセクションで構成されています。
- ColumnGroupsは、列、フォーマット、ファイル、および行IDの範囲を記述します。
- DeltaLogs は削除を記述します。削除の種類によって、変更の原因が異なります。たとえば、クライアントからの主キーによる削除、内部コンパクションによる位置指定削除、外部エンジンからの等価性による削除などです。
- Statsには、ブルームフィルタ、BM25統計、最小値/最大値などの計画用メタデータが含まれます。
- Indexes は、インデックスのタイプ、パラメータ、対象となる列、および行 ID の範囲を記述します。これには、HNSW や IVF などのベクトルインデックス、テキストインデックス、逆インデックス、ビットマップインデックス、および関連する構造体が含まれます。
この点が、Loonが従来のテーブルマニフェストと異なる点です。
ベクトルデータセットでは、データファイルやパーティションだけでなく、ベクトルインデックス、テキストインデックス、スパースフィーチャー、削除ログ、統計情報、外部オブジェクトへの参照、およびそれらを結びつける行 ID の範囲も追跡する必要があります。
マニフェストは、データベース以外の主体からも書き込み可能でなければなりません
最も重要な点は、マニフェストに何が含まれているかだけではありません。誰が書き込みできるか、という点です。
- もしデータベースだけがマニフェストに書き込み可能であれば、それは内部メタデータに留まります。メタデータは整理されますが、依然として単一のエンジンに限定されたプライベートなものです。
- 外部エンジンが新しいColumnGroup、統計情報、およびマニフェストエントリを生成できる場合、マニフェストは調整インターフェースとなります。
- たとえば、Sparkジョブはスパースベクトルカラムのバックフィルを行うことができます。新しいColumnGroupを書き込み、行のカバレッジと統計情報を記録し、新しいマニフェストをコミットします。オンラインクエリは、ジョブ実行中も引き続き古いバージョンを読み続けることができます。コミットが成功すると、新しいバージョンが可視化されます。
これはIcebergやDelta Lakeと精神的に似ていますが、オブジェクトモデルはより広範です。ベクトルデータセットは、テーブルファイルやパーティションだけでなく、ベクトルインデックス、テキストインデックス、スパース特徴量、削除ログ、統計情報、BLOB参照、および行IDの範囲を追跡する必要があります。
楽観的コミットにより、バージョンの更新が簡素化される
各コミットでは、新しいマニフェストバージョンが書き込まれます。ライターはバージョンNに基づいて新しいコンテンツを構築し、manifest-{N+1}.avro への書き込みを試みることができます。オブジェクトストレージの条件付き書き込みや世代一致のセマンティクスにより、そのバージョンがすでに存在する場合、コミットは失敗します。その場合、ライターは新しいバージョンに対して再試行できます。
これにより、Loonは、すべての更新を負荷が高く強一貫性のある調整パスを経由させることなく、楽観的並行性を実現できます。マニフェストがなければ、マルチフォーマットおよびマルチエンジンのストレージは、最終的には命名規則や手動による調整に頼ることになります。これは小規模なデータセットでは機能するかもしれませんが、TB規模のベクトルデータでは機能しません。
マニフェストこそが、異種混在のファイルを、複数のシステムが安全に読み取り・更新できるデータセットへと変えるものです。
ストレージがバージョン管理されるようになった際、ユーザーにとって何が変わるのか
アプリケーション開発者にとって、Loonは新たなAPIの負担になってはなりません。
ユーザーは、コレクション、挿入、検索、ハイブリッド検索といった、慣れ親しんだMilvusの概念を引き続き利用できます。通常のアプリケーション開発において、マニフェストファイル、ColumnGroups、行IDの範囲、ファイルレイアウトについて考慮する必要はありません。
変更は裏側で行われます。ストレージは、AI データセットが実際にどのように進化していくかをより深く認識するようになります。
新しいエンベディングを追加しても、古いデータが移動されるべきではありません
以前は、既存のコレクションにembedding_v2 を追加する場合、多くの場合、データのエクスポート、新しいモデルのトレーニング、ベクトルの生成、そしてSDKを介したコレクションの再インポートまたは一括更新が必要でした。このプロセスには、バージョンの追跡、ジョブ失敗時の再試行、インデックスの再構築、サービスへの影響、一貫性チェックなど、多くの運用作業が発生します。
Loon を使用すれば、これはスキーマの進化と新しい ColumnGroup のコミットだけで済むようになります。新しい埋め込みカラムは、独自の物理的な ColumnGroup として記述され、行 ID に基づいて整列され、マニフェストを通じて可視化されます。古いキャプションカラム、スカラーメタデータカラム、および元の埋め込みカラムを移動する必要はありません。
バックフィルには、クライアント側の更新ループは不要であるべきです
AIデータの更新の多くはバックフィルです。ハイブリッド検索が重要になった後に、チームがスパースベクトルを追加する場合があります。新しいモデルの学習後に、再ランク付け用の特徴量を追加する場合もあります。人間によるレビュー後にキャプションを修正する場合もあります。ポリシーの更新後にガバナンスタグを追加する場合もあります。
従来のレイアウトでは、データがSpark、Ray、またはその他の外部エンジンによって生成された場合でも、こうした変更はクライアントSDKの更新やデータベースのみの書き込み経路を通じて行われることがよくあります。
Loon を使用すれば、外部のコンピューティングシステムが新しい ColumnGroups を生成し、マニフェストを通じてコミットできます。データベースが、すべての書き換えにおける唯一のエントリポイントである必要はなくなりました。
オフライン分析に「真実」の別のコピーは必要ない
以前は、チームがオフラインでの評価や分析のために、オンラインコレクションをParquetにダンプすることがよくありました。これにより、同じデータセットの2つのバージョン(オンラインコレクションと分析用コピー)が生成されてしまいます。キャプションの修正、埋め込みの再生成、削除ログの適用、またはインデックスの再構築が行われた後、チームはどちらのコピーが最新のものかを確認しなければなりません。
マニフェストベースのストレージモデルでは、分析エンジンはサービングシステムと同じバージョン管理されたデータセットビューを読み取ることができます。必要な列のみを抽出したり、関連する行範囲のみをスキャンしたり、手動でエクスポートされたスナップショットではなく、宣言されたデータセットのバージョンに対して処理を行うことが可能です。
削除や修正は、変更された部分のみを対象とすべき
削除、キャプションの修正、ラベルの修正、ガバナンスの更新は、AIデータセットでは日常的に行われる作業です。それらが、すべての長いベクトル列に対して同じ書き換え処理を強制してはなりません。
Loon を使用すれば、ログの削除はまず論理削除として処理できます。その後のコンパクションにより、無関係なデータを書き換えることなく、影響を受けた ColumnGroups をクリーンアップできます。短いテキストフィールドが変更された場合、同じ論理行を共有しているという理由だけで、ストレージ層が数百ギガバイトもの高密度ベクトルを書き換える必要はありません。
外部エンジンはワークフローの一部となり、逃げ道ではなくなります
より大きな変化は、外部エンジンがもはやベクトルデータベースの外にあるシステムとして扱われなくなったことです。
Spark、Ray、評価ジョブ、ラベリングシステム、ガバナンスパイプラインは、すでにデータの多くを生成・変更しています。ストレージ層は、これらに対して、絶えずエクスポート、コピー、再インポートを繰り返すのではなく、単一の「真実の源(single source of truth)」を中心に連携できるようにすべきです。
これこそが、Manifestのバージョンによって可能になることです。これにより、オンライン配信、オフライン分析、バックフィルジョブ、およびコンパクションが、データセットに対する共通のビューを共有できるようになります。
これらは内部的なストレージの詳細に聞こえるかもしれませんが、チームがAIデータセットに対してどれほど迅速に反復処理を行えるかに影響を与えます。モデルの変更、特徴量のバックフィル、キャプションの修正、品質フィルター、インデックスの再構築のすべては、「システムは、移動する必要のないデータを移動させることなく、データセットを更新できるか?」という同じ問いに依存しています。
これこそが、このストレージモデルの実用的な価値です。
LoonはMilvus 3.0ベータ版およびZilliz Vector Lakebaseで利用可能です
LoonはMilvus 3.0ベータ版で利用可能であり、Zilliz Cloudの次なる進化形であるZilliz Vector Lakebaseのストレージ層の一部でもあります。また、今回のリリースでは以下の3つの主要分野に焦点を当てています:
- マニフェスト。その目的は、書き込み、バックフィル、削除、統計情報、およびインデックスの更新によって、読み取り側が一貫性を持って開くことができるバージョン管理されたデータセットビューを生成することです。 読み取り側にとっては、クエリによって特定のManifestバージョンを開き、データセットの安定したビューを確認できることを意味します。書き込み側にとっては、新しいデータファイル、削除ログ、統計情報、またはインデックスファイルを事前に準備し、バージョン管理されたコミットを通じて可視化できることを意味します。
- ColumnGroupおよびフォーマットのサポート。Parquetはスカラーおよびエコシステムに優しいカラムをサポートします。Vortexはベクトル中心のアクセスパターンをサポートします。Lanceは、既存のLanceデータセットとの互換性を確保するため、読み取り専用モードで統合可能です。
- Lake上のインデックス。スカラー統計、フィルタリングインデックス、およびテキスト逆引きインデックスは、行範囲単位のマニフェストベースのプランニングに参加できます。Lakeネイティブのベクトルインデックスは、より複雑な処理を要します。 HNSWとIVFはオブジェクトストレージ上での挙動が異なり、特にHNSWはランダムアクセスやキャッシュの局所性に敏感です。ローカルSSD向けに設計されたレイアウトを単純に再利用しても、同じ結果が得られるとは限りません。
まだ取り組むべき課題が残っています
- 外部書き込みパスが重要なのは、SparkやRayが、すべてのバックフィルをクライアントSDKループを経由させることなく、ColumnGroupsやマニフェストのコミットを生成できるようにすべきだからです。
- Lakehouseの相互運用性が重要なのは、多くのチームがすでにIceberg、Delta Lake、Trino、DuckDB、Athenaなどのカタログやクエリエンジンを使用しているためです。ベクトルデータは、ベクトル検索のパフォーマンスを損なうことなく、そのエコシステムに参加できる必要があります。
- インデックスレイアウトが重要なのは、グラフインデックスと反転インデックスが、オブジェクトストレージ上で異なるアクセスパターンを示すためです。
- 大容量オブジェクトのセマンティクスが重要なのは、生の動画、PDF、画像、音声ファイルには、派生したベクトルデータセットと整合する参照管理、バージョン管理、および削除動作が必要だからです。
具体的なリリース動作、デフォルト設定、および移行パスについては、関連するMilvusおよびZilliz Cloudのリリースノートを参照してください。ただし、ストレージの方向性は明確です。ベクトルデータベースには、サービング層の下に、バージョン管理されたレイクネイティブな基盤が必要です。
Zilliz Vector Lakebase上でLoonをお試しください
現在のスタックで、オンラインサービング、オフライン分析、バックフィル、外部データレイクのワークフローが別々のシステムに分離されている場合は、Zilliz Vector Lakebaseを検討する価値があります。Zilliz Cloudで試すことができます。新しい仕事用メールアドレスで登録すると、100ドルの無料クレジットがもらえます。また、ユースケースについてお気軽にご相談ください。
また、Milvus 3.0のリリースを追うことで、オープンソースエンジンにおけるLoonの進化を確認することもできます。
Zilliz Vector Lakebaseには以下の機能が統合されています:
- リアルタイムのパフォーマンスとコストのトレードオフに応じた階層型サービング
- 常時稼働のコンピューティングリソースを必要としない、大規模または探索的なワークロード向けのオンデマンド検索
- 外部データレイク検索:既存のレイクデータに対して直接インデックス作成や検索が可能
- ベクトル、テキスト、JSON、地理空間データにわたるフルスペクトル検索。ハイブリッド検索と再ランク付け機能を搭載
- ベクトルデータが豊富なデータに対するランダム読み取りを高速かつ低コストで実現するよう設計されたオープンフォーマット「Vortex」を基盤とした、レイクネイティブの統合ストレージ
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word