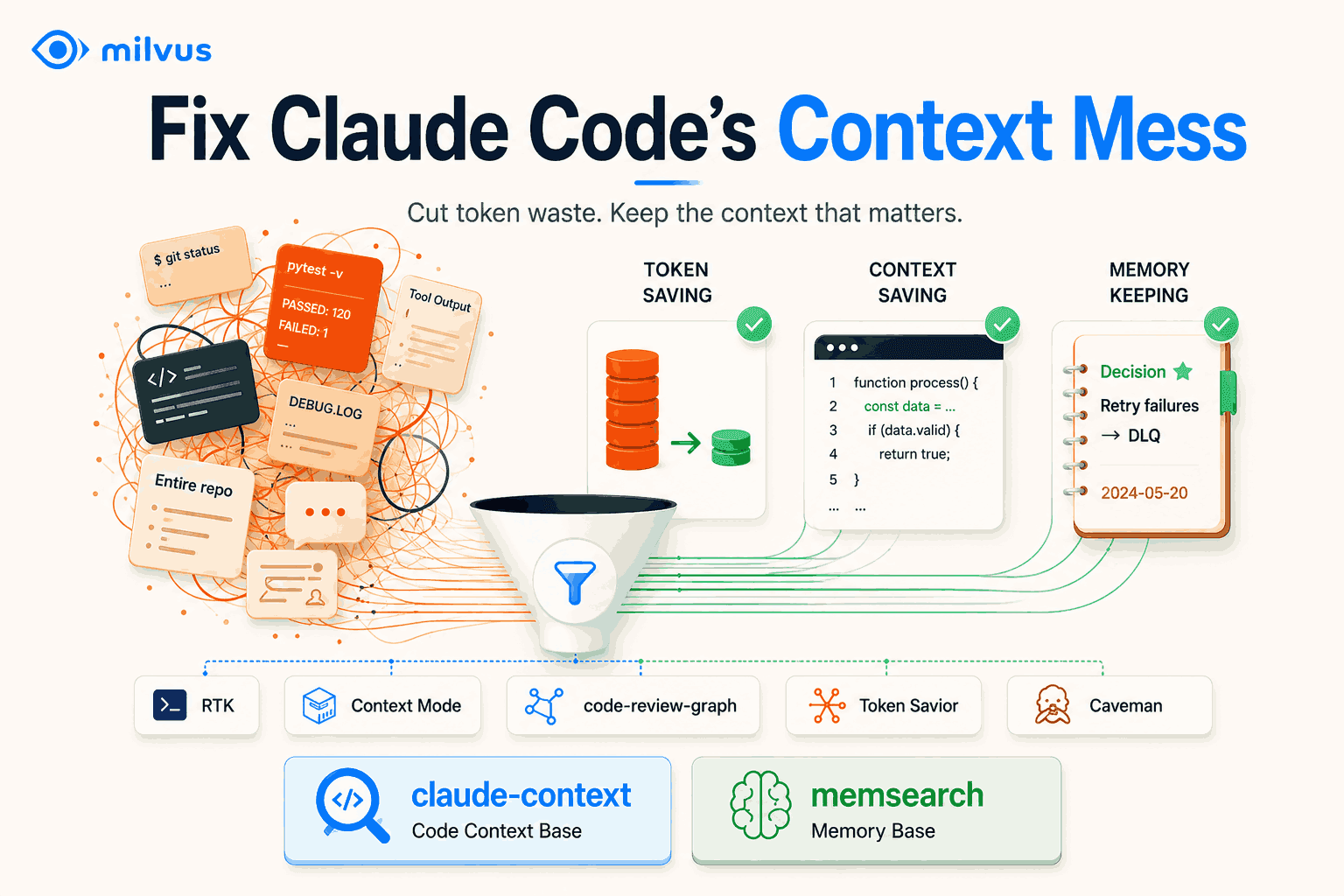
7 лучших инструментов с открытым исходным кодом для управления контекстом кода в Claude
Вы можете предоставить Claude Code контекстное окно объемом 1 млн токенов, но со временем ответы всё равно будут ухудшаться. Дело не только в размере контекста. Дело в его качестве.
Качество сеансов работы с Claude Code ухудшается, когда за внимание модели борются терминальные логи, необработанные выводы инструментов, повторное чтение файлов, развернутые ответы и забытая история проекта. В длительных рабочих процессах агентов этот «шум» превращается в замкнутый круг: модель теряет нить разговора, вы добавляете дополнительные ходы, чтобы исправить ответ, а эти дополнительные ходы добавляют еще больше шума.
Это и есть «размывание контекста»: у модели достаточно места для хранения информации, но важная информация зарыта под контекстом с низким сигналом. Более крупные окна могут облегчить игнорирование этой проблемы, поскольку разработчики перестают тщательно обдумывать, что именно вводить в промпт.
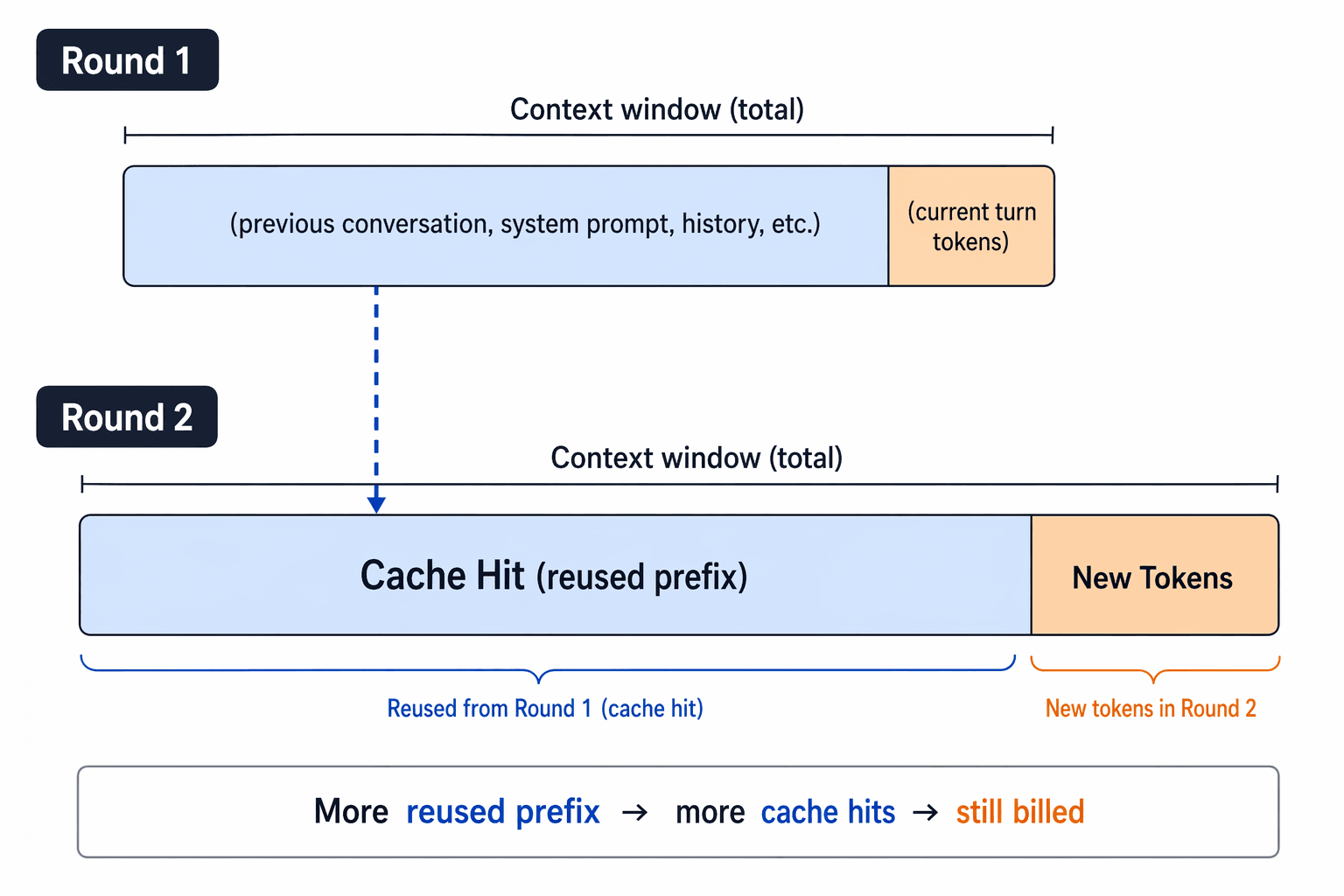 Схема кэширования подсказок, демонстрирующая, как повторно используемые префиксы всё равно могут увеличивать объём контекста, за который взимается плата, на протяжении ходов
Схема кэширования подсказок, демонстрирующая, как повторно используемые префиксы всё равно могут увеличивать объём контекста, за который взимается плата, на протяжении ходов
Кэширование подсказок может снизить затраты, связанные с повторяющимися префиксами, но оно не превращает контекстное окно в «ящик для хлама». Вы по-прежнему платите за новые токены, и вам по-прежнему нужно, чтобы модель рассуждала на основе правильной информации.
В этой статье рассматриваются семь инструментов с открытым исходным кодом, которые решают проблему потери фокуса контекста на разных уровнях: вывод терминала, вывод инструментов, навигация по кодовой базе, чтение файлов, подробность модели, семантический поиск кода и межсессионная память. В ней также объясняется, как эти идеи соотносятся с проектированием векторных баз данных, векторным поиском по сходству и системами поиска, такими как Milvus.
Что вызывает потерю контекста в Claude Code?
Потеря контекста в Claude Code обычно возникает из-за пяти типов сбоев: избыток необработанного текста инструкций, зашумленный вывод инструментов, повторное сканирование кодовой базы, длинные ответы модели и пробелы в памяти между сессиями или агентами.
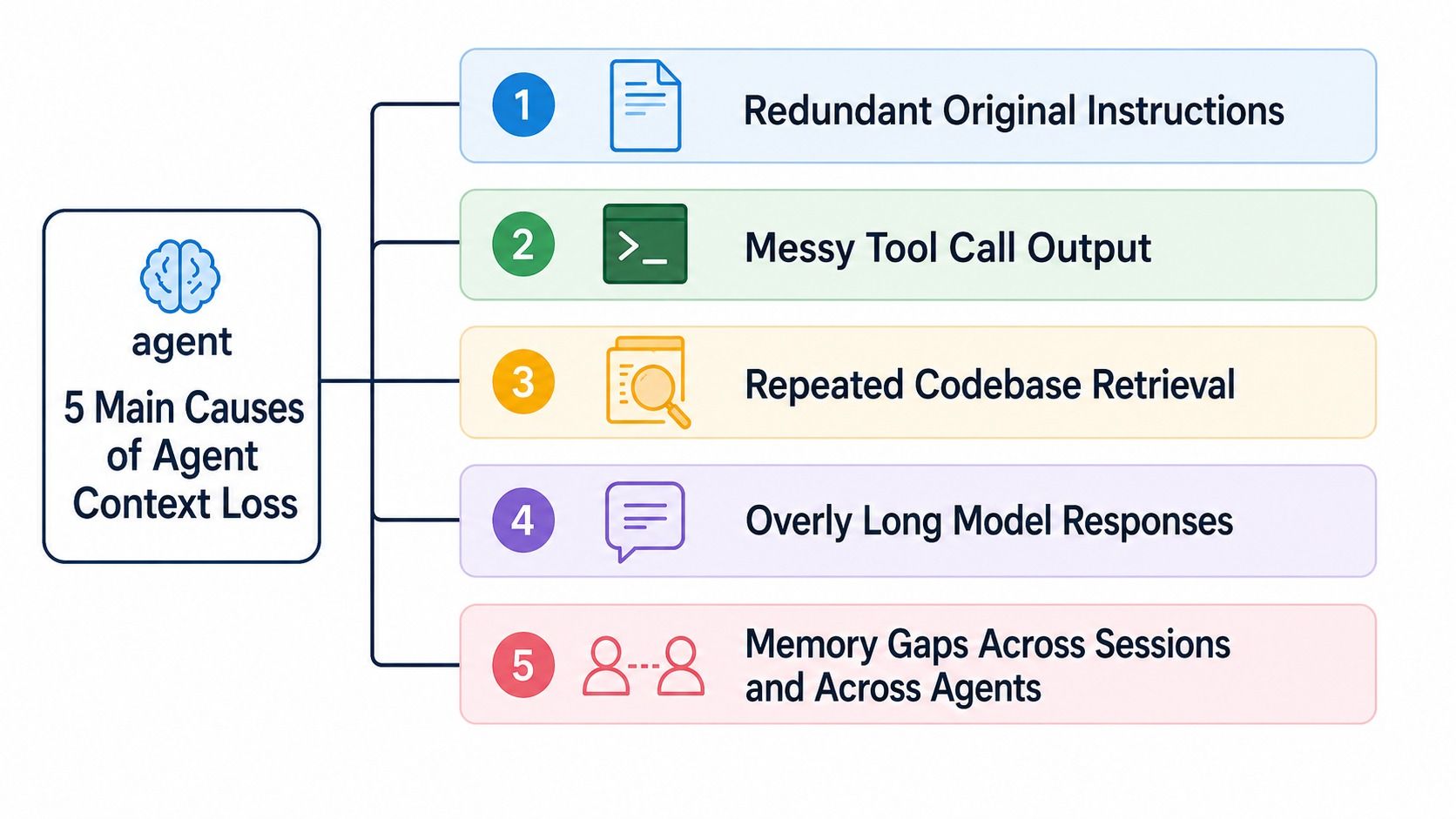 Пять причин потери контекста в Claude Code: избыточные инструкции, неструктурированные выводы инструментов, повторный поиск в кодовой базе, длинные ответы и пробелы в памяти
Пять причин потери контекста в Claude Code: избыточные инструкции, неструктурированные выводы инструментов, повторный поиск в кодовой базе, длинные ответы и пробелы в памяти
| Тип сбоя контекста | Как это выглядит в Claude Code | Категория инструментов, которые могут помочь |
|---|---|---|
| Журналы терминала перегружены | git: pytest, gh, а облачные CLI выводят больше текста, чем требуется модели. | Сжатие вывода CLI |
| Вывод данных инструментов переполняет окно | Логи тестов, дампы DOM и вывод MCP поступают в чат в виде огромных необработанных блоков. | Изоляция вывода инструментов |
| Повторяющаяся навигация по кодовой базе | Claude перечисляет каталоги, использует grep, читает файлы и повторяет одно и то же исследование в каждой сессии. | График кода или семантический поиск |
| Чтение файлов слишком обширно | Модель считывает весь файл, хотя ей нужен лишь один символ или краткое содержание. | Постепенное чтение кода |
| Клод говорит слишком много | Сам ответ добавляет ненужный контекст для последующих ходов. | Сжатие ответа |
| Память не сохраняется | Вы заново объясняете решения по проекту каждый раз, когда начинаете новую сессию. | Память, ориентированная на Markdown |
Хороший стек управления контекстом должен выполнять три задачи: не допускать ненужной информации, извлекать нужные знания о проекте по запросу и сохранять устойчивые решения между сессиями.
Какой инструмент управления контекстом Claude Code следует использовать в первую очередь?
Начните с того уровня, который создаёт больше всего помех в вашем рабочем процессе. Если проблема заключается в выводе терминала, начните с RTK. Если Claude постоянно блуждает по большому репозиторию, начните с claude-context или code-review-graph. Если ваша настоящая проблема заключается в том, что вам приходится каждый день заново объяснять одни и те же решения, начните с memsearch.
| Инструмент | Основная проблема, которую он решает | Наилучшее применение |
|---|---|---|
| RTK | Шумовой вывод терминала от типичных команд разработчиков. | Разработчики, которые запускают множество команд CLI внутри Claude Code. |
| Режим контекста | Огромный объем необработанных выводов инструментов, попадающих в основной диалог. | Активные пользователи Playwright, GitHub, систем ведения журналов или инструментов MCP. |
| code-review-graph | Исследование кодовой базы в больших репозиториях без предварительного ознакомления с кодом. | Рецензии, анализ зависимостей и вопросы о радиусе воздействия. |
| Token Savior | Полное чтение файлов, когда достаточно было бы сводки символов. | Крупные файлы, повторяющиеся поиски символов и инкрементное чтение кода. |
| Caveman | Склонность Клода к подробным ответам. | Пользователи, которым нужен лаконичный вывод и меньший контекст на будущее. |
| claude-context | Повторное изучение кодовой базы при каждом сеансе. | Семантический поиск кода через MCP. |
| memsearch | Потеря информации о проекте при смене сеансов, агентов и моделей. | Долгосрочные проекты с устойчивыми решениями и извлеченными уроками. |
Первые пять инструментов сокращают объем информации, поступающей в контекст или остающейся в нём. Последние два упрощают извлечение полезного контекста.
RTK сжимает необработанный вывод команд, прежде чем он попадает в Claude
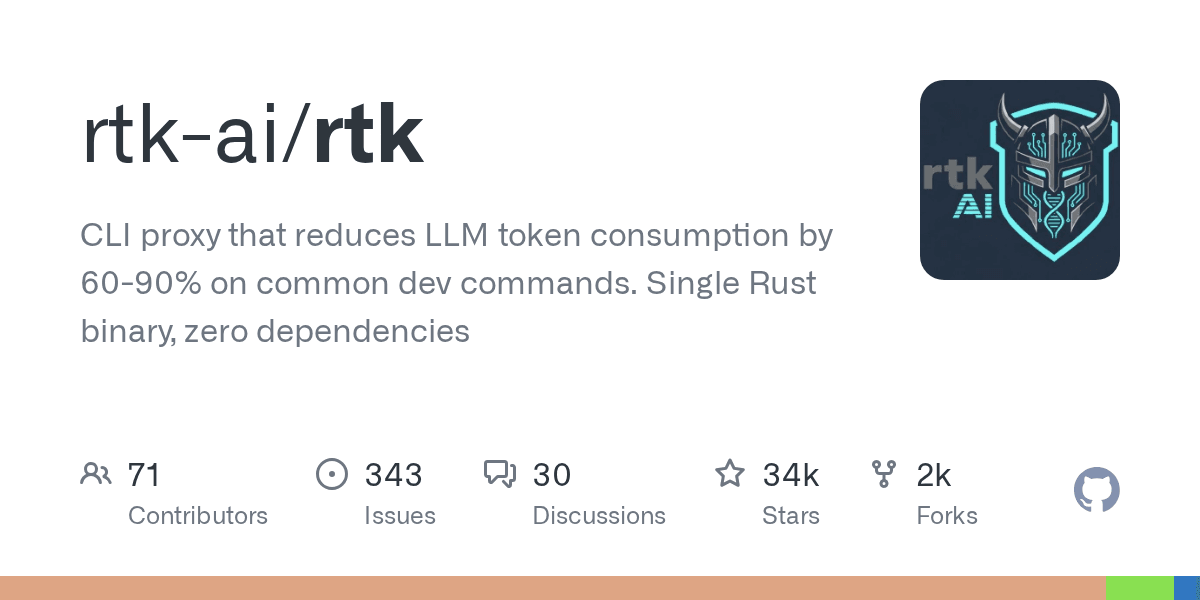
RTK — это прокси для командной строки, предназначенный для сокращения использования токенов в типичных командах разработчиков. Согласно описанию на GitHub, он сокращает потребление токенов LLM на 60–90 % при выполнении типичных команд разработчиков и поставляется в виде единого бинарного файла на языке Rust.
При повседневном использовании Claude Code такие команды, как ` git status`, ` pytest` и команды вывода списка файлов в каталоге, часто выводят в окно контекста полную информацию об окружении и описания состояния. Модели обычно требуется лишь краткий ответ: какие файлы изменились, какой тест завершился сбоем, на каком этапе застрял PR или какие ключевые файлы находятся в каталоге.
RTK находится между оболочкой и Claude. Он может переписывать команды с помощью хуков Claude Code и возвращать сжатый вывод.
Исходный вывод команды ` git status `:
On branch feat/payment-retry
Your branch is up to date with 'origin/feat/payment-retry'.
Changes not staged for commit:
modified: src/webhook/handler.ts
modified: src/queue/dlq.ts
modified: tests/webhook.test.ts
Untracked files:
docs/notes.md
no changes added to commit
Что действительно важно:
3 modified, 1 untracked
- src/webhook/handler.ts
- src/queue/dlq.ts
- tests/webhook.test.ts
То же самое и с ` pytest`. Необработанный вывод переполнен успешными тестами и «шумом» среды:
============================= test session starts =============================
platform darwin -- Python 3.12.4, pytest-8.4.1
collected 128 items
tests/test_auth.py …
tests/test_webhook.py …F…
tests/test_queue.py …
================================== FAILURES ==================================
________________ test_retry_to_dlq __________________
E AssertionError: expected status code 202, got 500
В сжатом виде сигнал становится понятным сразу:
128 tests collected, 1 failed
FAIL tests/test_webhook.py::test_retry_to_dlq
AssertionError: expected status code 202, got 500
RTK — это самая простая отправная точка, когда раздувание контекста происходит из-за команд оболочки, а не из-за извлечения кода.
Режим «Context Mode» изолирует огромные выводы инструментов за пределами основного чата
Режим контекста создан для необработанных блоков данных, которые возвращают инструменты: журналы тестирования, снимки DOM браузера, данные GitHub, вывод инструментов MCP и соскобленные страницы. В описании на GitHub подчеркивается оптимизация контекстного окна для агентов искусственного интеллекта, занимающихся программированием, и сообщается о сокращении объёма вывода инструментов на 98%.
 Карточка репозитория «Context Mode» на GitHub, демонстрирующая изолированные в «песочнице» выводы инструментов и позиционирование оптимизации контекста
Карточка репозитория «Context Mode» на GitHub, демонстрирующая изолированные в «песочнице» выводы инструментов и позиционирование оптимизации контекста
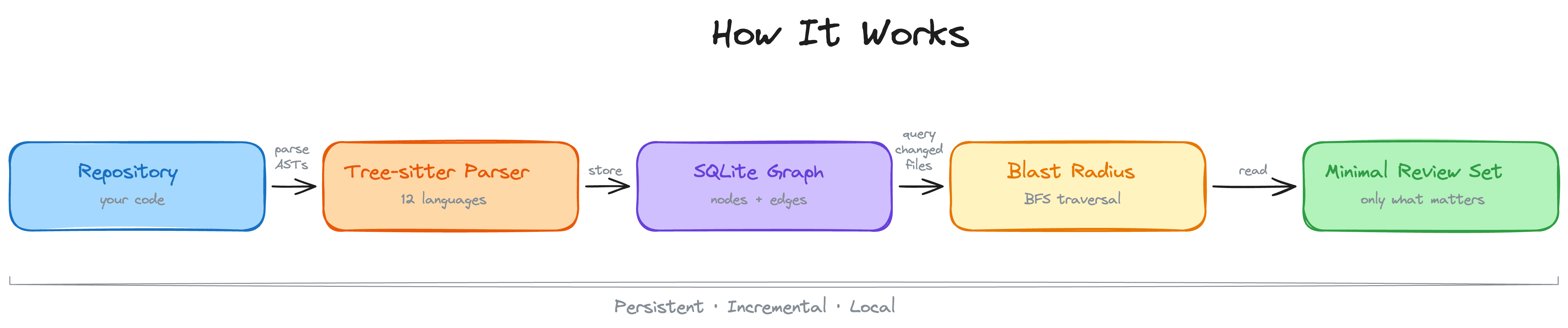
Его подход заключается в изоляции больших выводов инструментов в локальной изолированной среде и индексировании, а затем передаче в диалог с Claude только сводок и дескрипторов для поиска.
 Схема работы Context Mode, демонстрирующая прохождение больших выводов инструментов через выполнение в песочнице, индексы SQLite или FTS, сводки и результаты поиска
Схема работы Context Mode, демонстрирующая прохождение больших выводов инструментов через выполнение в песочнице, индексы SQLite или FTS, сводки и результаты поиска
Такой поток полезен, поскольку агенту-программисту часто нужен именно узел, в котором произошел сбой, неработающий селектор или соответствующий трассировка стека, а не весь DOM или каждая строка прошедшего теста. Context Mode сохраняет полный вывод доступным локально, не позволяя ему доминировать в основном диалоге.
Это похоже на то, как гибридные поисковые системы в производственной среде отделяют хранение от извлечения. Вы храните исходные данные где-нибудь в надежном месте, а затем извлекаете только тот фрагмент, который имеет значение.
code-review-graph отображает структуру кода до того, как Claude начнёт в ней ориентироваться
code-review-graph решает другую проблему: Claude не всегда нужен дополнительный текст; ему нужна более качественная карта.
 Изображение логотипа code-review-graph, использованное в оригинальной статье
Изображение логотипа code-review-graph, использованное в оригинальной статье
В большом репозитории простой вопрос может вызвать ресурсоемкое исследование:
После изменения этой логики входа в систему, какие файлы и тесты будут затронуты?
Без графа кода Claude обычно действует следующим образом:
read auth.ts
grep login
read middleware
read tests
keep guessing
code-review-graph заранее строит структурную карту кодовой базы. Он использует Tree-sitter для анализа функций, классов, импортов, отношений вызовов, наследования и тестовых зависимостей, а затем записывает граф в SQLite.
Это делает его полезным для ревью кода и анализа радиуса воздействия. Вместо того чтобы просить Claude заново выявлять граф зависимостей посредством многократного чтения, вы позволяете ему сначала запросить структуру.
Это похоже на семантический поиск, но не то же самое. Структурный граф отвечает на вопрос «что от чего зависит?», а семантический поиск — на вопрос «какой код концептуально связан с этим вопросом?». В реальных рабочих процессах с использованием помощников по коду часто требуются оба подхода.
Token Savior предоставляет Claude сводки символов до отправки полных файлов
Основная идея Token Savior проста: по умолчанию не отправлять полный файл. Сначала отправлять индекс или сводку символов, а затем расширять данные только тогда, когда для выполнения задачи требуются более подробные сведения.
 Карточка репозитория Token Savior на GitHub с описанием сервера MCP и статистикой проекта
Карточка репозитория Token Savior на GitHub с описанием сервера MCP и статистикой проекта
Если вы спросите, где обрабатывается вебхук оплаты, модели зачастую не нужна каждая строка каждого связанного файла. Сначала ей нужно узнать, имеет ли файл или символ отношение к запросу.
Token Savior предоставляет код по слоям:
| Уровень | Что получает Claude | При развертывании |
|---|---|---|
| Краткое описание | Индекс, названия символов и краткие описания. | Первый ответ по умолчанию. |
| Фрагмент | Небольшой фрагмент кода, содержащий соответствующий символ. | Когда краткое описание, вероятно, уместно. |
| Полный файл | Полное содержимое файла. | Только в тех случаях, когда это необходимо для редактирования или глубокого анализа. |
Это отражает то, как разработчики на самом деле читают код. Вы просматриваете, проверяете релевантность, а затем открываете полный файл только при необходимости. Это также напоминает модель постепенного извлечения, используемую в приложениях RAG: сначала извлекается достаточно широкий контекст для ориентации, а затем он сужается перед генерацией.
Caveman сокращает объем ответов самого Claude
Большинство инструментов для работы с контекстом сосредоточены на том, что поступает в модель. Caveman нацелен на то, что выдает Claude.
Caveman — это навык/плагин для Claude Code, который удаляет наполнители, любезности, вводные предложения, излишние пояснения и повторяющиеся структуры. Цель не в том, чтобы удалить знания, а в том, чтобы сделать ответ более плотным.
Без Caveman:
Причина, по которой ваш компонент React перерисовывается, вероятно, заключается в том, что…
С Caveman:
При каждом рендеринге создаётся новая ссылка на объект. Встроенный проп object = новая ссылка = повторный рендеринг. Оберните в useMemo.
Это важно, потому что собственные ответы Claude становятся контекстом для будущих ответов. Если каждый ответ содержит длинное объяснение, следующий ход начинается с большего объёма текста, чем необходимо. Более краткие ответы могут улучшить следующий ход в той же степени, в какой они улучшают текущий.
Для команд, занимающихся разработкой контекста для ИИ-агентов, Caveman служит напоминанием о том, что политика вывода является частью политики контекста.
claude-context добавляет семантический поиск кода через MCP
claude-context решает проблему повторного исследования кодовой базы с помощью семантического поиска. Он индексирует репозиторий, хранит фрагменты кода в векторной базе данных и предоставляет возможность поиска через Model Context Protocol.
 Репозиторий Claude Context, представленный на GitHub, попал в тренды в оригинальной статье
Репозиторий Claude Context, представленный на GitHub, попал в тренды в оригинальной статье
В большом кодовом базе вы постоянно задаете Claude вопросы типа:
«Помоги мне выяснить, какие части кода могут быть связаны с этой ошибкой».
Без уровня поиска стандартный подход Claude часто заключается в следующем:
list the directory
grep around
read a bunch of files
keep guessing
claude-context переносит эту работу в уровень поиска. Он разбивает репозиторий на фрагменты, генерирует вложения, хранит их в индексе кода на базе Milvus и извлекает релевантные фрагменты кода до того, как модель начнёт «вслепую» читать файлы.
 Схема работы claude-context, демонстрирующая разбиение кодовой базы на фрагменты, вложения, векторную базу данных и гибридный поиск, извлечение релевантного кода и вставку контекста в Claude
Схема работы claude-context, демонстрирующая разбиение кодовой базы на фрагменты, вложения, векторную базу данных и гибридный поиск, извлечение релевантного кода и вставку контекста в Claude
Именно здесь инструменты программирования на базе ИИ начинают напоминать поисковые системы. Необходимы фрагментация, вложения, метаданные, лексическое сопоставление, ранжирование и актуальность. Это те же самые строительные блоки, лежащие в основе производственного поиска RAG, гибридной маршрутизации поиска и выбора модели вложений.
memsearch сохраняет полезную информацию между сессиями и агентами
memsearch решает обратную сторону проблемы: не что забыть, а как вспомнить то, что важно.
 Изображение логотипа memsearch из оригинальной статьи
Изображение логотипа memsearch из оригинальной статьи
Представьте, что в понедельник вы говорите Claude:
Наш веб-хук не может повторять попытку при сбое — события с ошибками должны попадать в очередь «мертвых писем».
В среду вы открываете новую сессию и спрашиваете:
Что ещё можно оптимизировать на уровне веб-хуков?
Без постоянной памяти Клод будет рассматривать решение, принятое в понедельник, как будто его и не было. Вы объясняете это заново.
memsearch хранит память в виде локальных, удобочитаемых для человека файлов в формате Markdown и использует Milvus в качестве восстанавливаемого индекса поиска. Такая архитектура позволяет людям редактировать память, при этом оставляя её доступной для поиска агентами.
При извлечении memsearch использует прогрессивный поиск: сначала выполняется поиск, затем, при необходимости, происходит расширение результатов, а только в случае необходимости происходит детализация до исходной стенограммы.
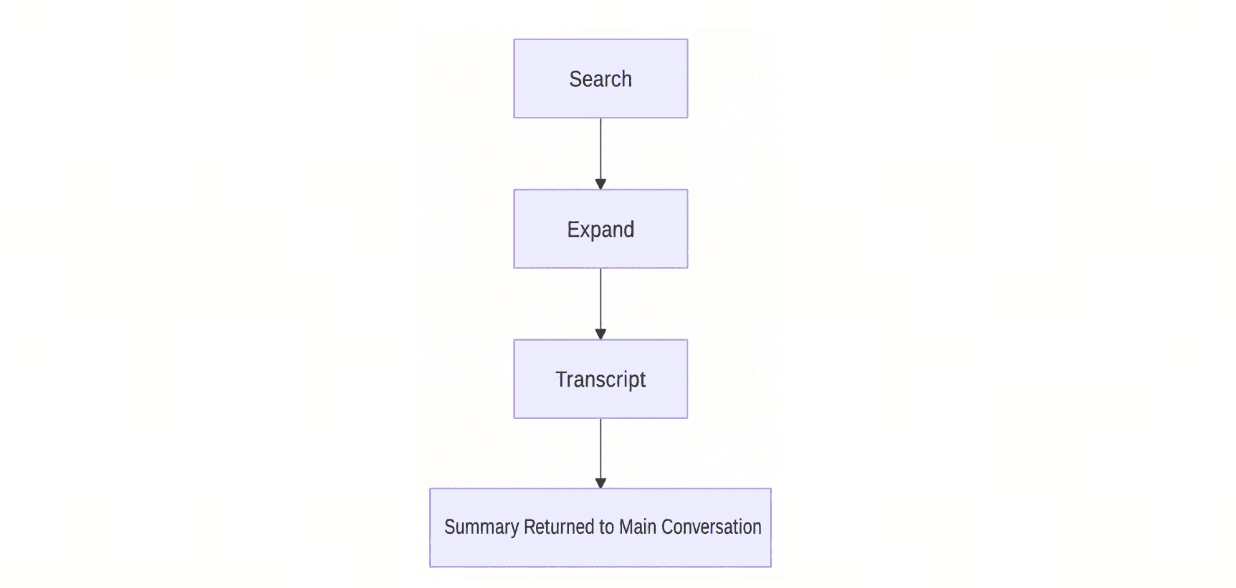 Поток прогрессивного извлечения memsearch, демонстрирующий поиск, расширение, транскрипт и возвращение к основному разговору с кратким резюме
Поток прогрессивного извлечения memsearch, демонстрирующий поиск, расширение, транскрипт и возвращение к основному разговору с кратким резюме
Этот подход, ориентированный в первую очередь на Markdown, полезен для команд, работающих с разными сессиями, моделями и агентами. Он также естественным образом сочетается с долгосрочной памятью ИИ-агентов, общей памятью нескольких агентов и решением более широкой задачи предотвращения потери контекста в системах агентов.
Как эти инструменты взаимодействуют друг с другом?
Эти семь инструментов дополняют друг друга, но не являются взаимозаменяемыми. Используйте их как слои.
| Уровень | Используйте эти инструменты | Почему |
|---|---|---|
| Удаление помех от команд | RTK | Сжимайте объемные выводы терминала до того, как они поступят в Claude. |
| Песочница для необработанных данных инструментов | Режим контекста | Храните большие журналы, DOM и полезные нагрузки инструментов вне основного диалога. |
| Создание карты структуры кода | code-review-graph | Отвечайте на вопросы о зависимостях и радиусе воздействия без слепого чтения файлов. |
| Постепенное чтение кода | Token Savior | Начинайте с сводок по символам, а затем расширяйте их только по мере необходимости. |
| Сжимайте ответы Claude | Caveman | Не допускайте, чтобы собственные выводы модели перегружали будущий контекст. |
| Извлечение релевантного кода | claude-context | Используйте семантический и гибридный поиск кода вместо повторяющихся циклов grep. |
| Повторно используйте надежные решения | memsearch | Восстанавливайте историю проекта при смене сеансов, агентов и моделей. |
Практический порядок внедрения:
- Сначала устраните явный шум. Добавьте RTK или Context Mode, если в вашем контексте преобладают вывод командной оболочки и данные инструментов.
- Исправьте навигацию по репозиторию. Добавьте code-review-graph для структуры или claude-context для семантического поиска кода.
- Контролируйте то, что остаётся. Используйте Token Savior и Caveman, чтобы свести к минимуму чтение файлов и ответы модели.
- Сохраняйте устойчивые знания. Используйте memsearch, когда повторяющиеся объяснения становятся узким местом.
Оставайтесь на связи
- Присоединяйтесь к сообществу Milvus в Discord, чтобы задавать вопросы и обмениваться опытом по управлению контекстом с другими разработчиками.
- Запишитесь на бесплатную сессию Milvus Office Hours, если вам нужна помощь в проектировании уровня извлечения для кода, памяти или рабочих нагрузок RAG.
- Если вы предпочитаете обойтись без настройки инфраструктуры, Zilliz Cloud (управляемый сервис Milvus) предлагает бесплатный тариф для начала работы.
Часто задаваемые вопросы
Как уменьшить количество токенов Claude Code, не теряя при этом полезного контекста?
Начните с сжатия самых «шумных» входных данных: вывода терминала, необработанных данных инструментов и повторяющихся чтений кода. Затем добавьте инструменты извлечения, такие как claude-context или code-review-graph, чтобы Claude мог извлекать релевантный код вместо того, чтобы исследовать репозиторий с нуля.
Стоит ли использовать claude-context или code-review-graph для большого репозитория?
Используйте claude-context, когда вам нужен семантический поиск кода, особенно если вы не знаете точного имени файла или символа. Используйте code-review-graph, когда вам нужны структурные ответы, такие как отношения вызовов, импорты, тестовые зависимости и радиус воздействия ревью.
Отличается ли поиск по памяти от поиска по коду в Claude Code?
Да. Поиск кода находит соответствующие файлы проекта или символы. Поиск в памяти восстанавливает сохраненные решения, пользовательские настройки, историю отладки и уроки, полученные в разных сессиях. memsearch ориентирован на поиск в памяти; claude-context — на поиск кода.
Заменяют ли эти инструменты кэширование промтов или более широкое контекстное окно?
Нет. Кэширование подсказок и большие окна контекста помогают с точки зрения емкости и затрат, но они не определяют, какая информация заслуживает внимания. Инструменты управления контекстом улучшают качество и плотность информации, поступающей в модель в первую очередь.
 cccm 11zon
cccm 11zon
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word