Почему мы создали Loon: механизм хранения данных для ИИ, которые постоянно меняются.
Эта статья изначально была опубликована на сайте zilliz.com и перепечатана с разрешения автора.
Основные выводы
Это длинное и подробное техническое исследование, поэтому прежде чем перейти к деталям, рассмотрим ключевые моменты.
- Наборы данных для ИИ — это не статические таблицы. Одни и те же строки постоянно меняются, поскольку команды заменяют модели встраивания, добавляют разреженные векторы, корректируют подписи, заполняют пропущенные метки, перестраивают индексы и проводят офлайн-анализ.
- Традиционные схемы хранения имеют три недостатка: длинные столбцы векторов делают заполнение пробелов ресурсоемким, единый формат файла не может одинаково хорошо обслуживать как сканирование, так и точечное чтение, а хранение в частной базе данных вынуждает внешние конвейеры создавать дополнительные копии исходных данных.
- Loon — это новый механизм хранения для Milvus и Zilliz Vector Lakebase. Он построен на основе гибридных форматов файлов, выравнивания идентификаторов строк и манифеста, который определяет версионированное состояние набора данных.
- Цель состоит в том, чтобы один векторный набор данных мог поддерживать онлайн-поиск, офлайн-анализ, заполнение пробелов, уплотнение и внешние вычисления без постоянного копирования, перезаписи или повторного импорта данных.
Введение
Некоторое время существовал один аргумент против векторных баз данных, который казался разумным.
Традиционные базы данных и так хранят целые числа, строки, JSON, BLOB-объекты и индексы. Почему бы не добавить тип « _vector_ », не построить рядом с ним индекс ANN и не считать дело сделаным?
Для ранних этапов семантического поиска это работает достаточно хорошо. Векторный столбец плюс индекс могут обеспечить работу демо-версии, небольшого приложения RAG или функции внутреннего поиска. Проблема возникает позже, когда набор данных начинает вести себя не столько как таблица, сколько как система данных для искусственного интеллекта.
Производственный векторный набор данных имеет строки, первичные ключи, скалярные поля и столбцы, доступные для запросов. В этом смысле он похож на таблицу базы данных. Но при этом он обладает масштабом и структурой рабочего процесса, характерными для озера данных. Он может содержать сотни миллионов записей. Его неоднократно считывают и перезаписывают Spark, Ray, DuckDB, конвейеры обучения, задания оценки и системы контроля качества данных.
Он также зависит от объектного хранилища. Исходными объектами часто являются видео, изображения, PDF-файлы, аудиофайлы или веб-документы, которые остаются в S3, GCS, OSS или другом объектном хранилище. База данных хранит ссылки, метаданные, производные признаки и индексы. Затем она добавляет элементы, для управления которыми традиционные модели хранения не были созданы, в качестве полноценных объектов: плотные вложения, разреженные векторы, подписи, векторные индексы, текстовые индексы, журналы удалений, статистику, версии моделей, версии парсеров, ссылки на внешние BLOB-объекты, а также отношения версий между всеми ними.
Именно здесь подход «просто добавь векторный столбец» начинает давать сбой. Вопрос не в том, может ли база данных хранить байты векторов. Многие системы могут это делать. Более сложный вопрос заключается в том, способна ли модель хранения обрабатывать изменения векторных данных, их запросы и совместное использование в рамках стека данных ИИ.
Именно поэтому мы создали Loon — новый механизм хранения для Milvus и Zilliz Vector Lakebase (следующего поколения Zilliz Cloud).
Loon разработан с учетом трех принципов:
- Использовать разные физические форматы для разных типов столбцов.
- Согласовывать эти столбцы с помощью общего пространства идентификаторов строк.
- Использование манифеста для определения версионного состояния набора данных.
Чтобы понять, почему эти компоненты важны, давайте начнём с типичного мультимодального рабочего процесса.
Векторный набор данных никогда не бывает окончательно завершен.
Представьте себе команду специалистов по искусственному интеллекту, создающую набор данных с видео для мультимодального обучения.
Длинное видео загружается в объектное хранилище. Конвейер разбивает его на клипы на основе смены сцен, границ кадров или временных окон. Клипы, которые слишком длинные или слишком короткие, размытые, дублирующиеся или низкого качества, отфильтровываются. Оставшиеся клипы оцениваются моделью эстетики, снабжаются подписями другой моделью, снабжаются встроенными описаниями с помощью модели «зрение-язык» и хранятся в векторной базе данных для поиска, дедупликации и фильтрации обучающих данных.
На высоком уровне рабочий процесс выглядит просто:
video
→ clips
→ metadata
→ aesthetic_score
→ caption
→ embedding
→ search / dedup / training data filtering
Однако набор данных поступает не в готовом виде.
- На первой неделе таблица может содержать только
clip_id,video_id,start_offsetиduration. - На второй неделе команда добавляет
aesthetic_score. - На третьей неделе запускается модель генерации подписей, и каждый клип получает
caption. - На четвёртой неделе запускается первая модель встраивания, и каждый клип получает 768-мерное встраивание CLIP.
- Через месяц команда меняет модели и заполняет пробелы в
embedding_v2, теперь с 1024 измерениями. - Через два месяца гибридный поиск становится обязательным, поэтому команда добавляет столбец с разреженным вектором.
- Через три месяца подписи проходят проверку людьми и должны быть исправлены на месте.
Набор данных так и не был завершен. В него продолжали накапливаться новые интерпретации одних и тех же базовых строк.
В этом заключается одно из основных отличий векторных данных от традиционных бизнес-данных. Одна и та же строка перерабатывается снова и снова. А масштаб превращает это из неудобства в проблему хранения: мультимодальные наборы данных часто состоят не из миллионов записей, а из сотен миллионов или миллиардов. LAION-5B — полезный ориентир по объему: миллиарды пар «изображение-текст», каждая из которых содержит метаданные, подписи и вложения. Таким образом, сложность заключается не в первоначальной вставке. Сложность заключается во всём, что происходит после того, как набор данных начинает развиваться. Эта эволюция выявляет три проблемы.
Первая проблема: длинные столбцы делают амплификацию записи дорогостоящей
Столбчатые форматы, такие как Parquet, отлично подходят для многих аналитических задач. Они хорошо работают, когда схемы достаточно стабильны, данные читаются чаще, чем перезаписываются, сканирование затрагивает только подмножество столбцов, а сжатие имеет значение. Именно для таких условий были оптимизированы многие аналитические форматы.
Векторные строки намного шире аналитических
TPC-H lineitem — хороший эталон. Он имеет 16 столбцов: целочисленные ключи, десятичные значения, даты, короткие строки и небольшое поле для комментариев. Одна несжатая строка занимает примерно 150 байт. После сжатия её размер может значительно уменьшиться. При размере группы строк в 64 МБ система хранения может сгруппировать сотни тысяч строк в одну группу.
Векторные наборы данных выглядят иначе.
Набор данных типа «изображение-текст» в стиле LAION гораздо ближе к тому, что сегодня генерируют многие конвейеры искусственного интеллекта. Каждая строка по-прежнему содержит обычные метаданные: URL, подпись, ширину, высоту, показатели качества, метки и так далее. Но как только добавляется вложение, физическая структура строки меняется.
768-мерный вектор CLIP занимает около 1,5 КБ в формате fp16 или 3 КБ в формате fp32. Этот один столбец может быть намного больше, чем целая строка TPC-H lineitem.
При этом 768 измерений не являются чем-то необычным или большим по современным меркам. В мультимодальных конвейерах часто используются вложения с 1024 или 2048 измерениями. В модели OpenAI « text-embedding-3-large » количество измерений достигает 3072, что составляет около 12 КБ на вектор в формате fp32.
Сравнение очевидно:
| Формат набора данных | Приблизительный размер строки | Что преобладает в строке |
|---|---|---|
| TPC-H lineitem | ~150 байт в несжатом виде | скалярные поля и поля коротких строк |
| Строка в стиле LAION с вектором fp16, имеющим 768 измерений | ~1,5 КБ+ | встраивание |
| строка в стиле LAION с вектором fp32 размером 768 | ~3 КБ+ | встраивание |
| Строка с вектором fp32 размерностью 3072 | ~12 КБ+ только для самого вектора | встраивание |
Во многих наборах данных для ИИ столбец с вектором — это не просто ещё одно поле. Физически он занимает большую часть строки. Это влияет на затраты, связанные с эволюцией схемы.
Добавление одного столбца с вектором может означать сотни гигабайт
Предположим, что набор данных содержит 100 миллионов видеороликов. Добавление нового столбца вложений fp32 с 1024 измерениями означает запись примерно 400 ГБ необработанных векторных данных. Это не включает статистику, индексы, обновления метаданных, накладные расходы на хранение объектов, валидацию или интеграцию с путями обслуживания.

Если команда каждый месяц добавляет один или два векторных столбца, таких как « embedding_v2 », « sparse_vector » или функции переранжирования, эволюция схемы становится повторяющейся задачей инженеров по данным, объём которой измеряется сотнями гигабайт или терабайт.
Небольшие логические обновления могут вызывать масштабные физические перезаписи
Обновления не менее важны.
В столбчатых системах старые данные обычно не обновляются на месте. Журнал удалений фиксирует изменения, а впоследствии в процессе уплотнения действующие строки перезаписываются в новые файлы. Эта модель удобна, когда строки небольшие.
В случае векторных данных небольшое логическое обновление может вызвать масштабную физическую перезапись.
Задача проверки человеком может исправить всего несколько сотен байтов в подписи. Но если подпись, плотный вектор, разреженный вектор и другие производные характеристики имеют общий жизненный цикл физического файла, система может в итоге переписать и векторы. Логическое изменение невелико. Физический ввод-вывод может быть огромным.
В этом и заключается проблема амплификации записи в векторных хранилищах. Проблема заключается не только в том, что векторы имеют большой размер. Дело в том, что большие производные поля и небольшие изменяемые поля часто связываются между собой из-за структуры хранения, которая рассматривает их как единое целое.
Для наборов данных ИИ заполнение пробелов является рутинной рабочей нагрузкой
Для традиционных аналитических таблиц эволюция схемы может происходить лишь изредка. Для наборов данных ИИ это рутинная задача. Модели подписей обновляются. Модели встраивания заменяются. Редкие векторы добавляются позже. Появляются признаки переранжирования. Метки, присвоенные людьми, корректируются. Теги управления заполняются задним числом. Индексы перестраиваются.
Эти операции — не простое добавление данных. Они часто изменяют или расширяют существующие строки.
Именно поэтому векторное хранилище не может оптимизироваться только под пропускную способность сканирования. Оно также должно снижать затраты на дозаполнение и частичные обновления.
Вторая проблема: одни и те же данные должны поддерживать как сканирование, так и точечное чтение
После записи данных путь чтения разветвляется. Один и тот же набор векторных данных обычно имеет две различные схемы доступа: аналитическое сканирование и точечное чтение.
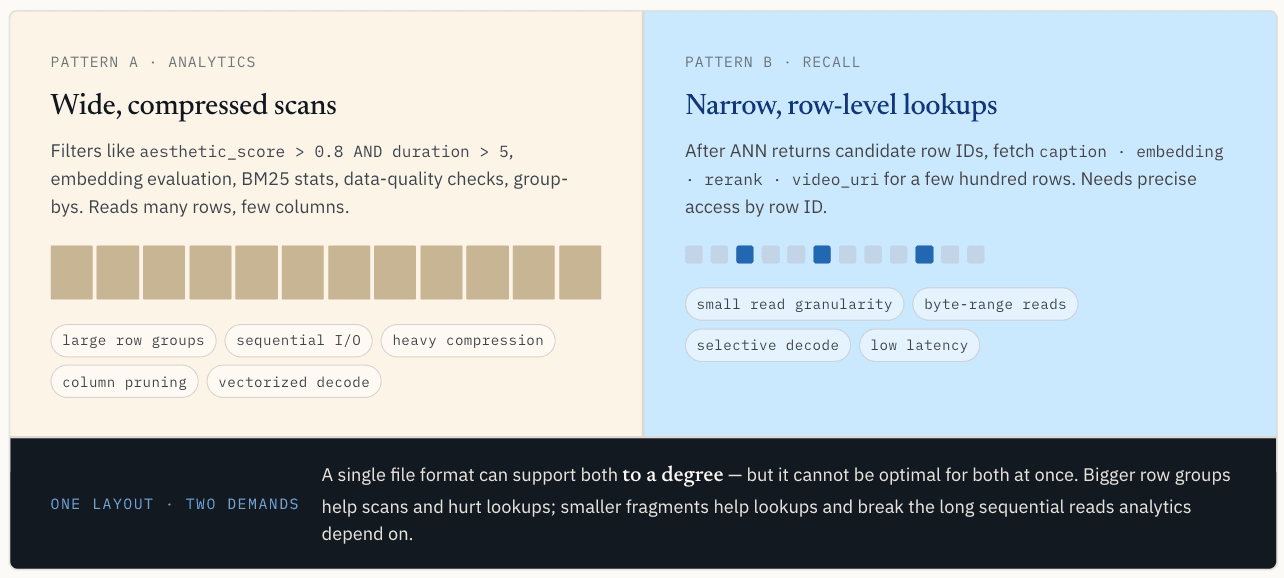
Аналитические рабочие нагрузки требуют широкого сканирования сжатых данных
Конвейер может запускать такие фильтры, как:
WHERE aesthetic_score > 0.8 AND duration > 5
Или он может выполнять автономный анализ, полную оценку вложений, статистику BM25, построение растровых изображений, проверки качества данных, подсчёты и группировку.
При таком сценарии считывается много строк, но только несколько столбцов. Для него предпочтительны последовательный ввод-вывод, большие группы строк, сжатие, прореживание столбцов, пакетное декодирование и векторизованное выполнение.
Здесь помогают большие группы строк. Они позволяют одному запросу ввода-вывода извлечь большой объем полезных данных, повышают эффективность сжатия и предоставляют механизму выполнения достаточное количество непрерывных данных для амортизации накладных расходов. Когда несколько столбцов считываются вместе, их упорядочивание для обеспечения пропускной способности сканирования также помогает сократить количество промахов кэша во время векторизованного выполнения.
Parquet демонстрирует высокую эффективность в этом направлении.
Результаты ANN требуют узких поисков на уровне строк
После того как поиск по ANN возвращает идентификаторы строк-кандидатов, системе часто требуется извлечь такие поля, как:
caption
embedding
rerank feature
video_uri
metadata
В этом сценарии считывается меньшее количество строк — часто сотни или тысячи, — но требуется точный доступ по идентификатору строки. Необходимо найти конкретную строку и столбец, извлечь только требуемый диапазон байтов и избежать извлечения всей группы строк только для получения нескольких записей.
Точечный поиск предъявляет почти противоположные требования к сканированию. Ему нужна меньшая степень детализации чтения. В идеале уровень хранения может найти соответствующий сегмент или диапазон байтов по идентификатору строки, прочитать только этот диапазон и декодировать только те данные, которые необходимы для получения результата.
Сжатие также предполагает иной компромисс. Для сканирования часто целесообразно использовать более сильное сжатие, поскольку система считывает большой объём данных и экономит операции ввода-вывода. Для точечного поиска сжатие может стать помехой, если для извлечения одной строки требуется декодировать гораздо более крупный сжатый блок.
Одна структура не может быть оптимизирована для обоих вариантов
В этом и заключается основной конфликт. Для скалярной фильтрации и аналитики требуются широкие, сжатые и удобные для сканирования схемы. Для векторного поиска нужны узкие, точные схемы с адресацией по строкам.
Один формат файла может в той или иной степени поддерживать оба подхода, но не может быть оптимальным для обоих одновременно.
Если все столбцы хранятся в формате Parquet, скалярные сканирования выполняются без проблем. Но поиск по ANN после повторного вызова становится сложнее. Системе может потребоваться всего несколько сотен векторов, подписей или записей метаданных, в то время как уровню хранения, возможно, придётся считывать большие группы строк, содержащие в основном нерелевантные строки.
На локальном SSD кэш и mmap могут скрыть часть этих затрат. Как только данные хранятся в объектном хранилище, затраты становятся более заметными. Каждый промах кэша может превратиться в удалённое чтение диапазона. Если строки-кандидаты разбросаны по многим группам строк, один запрос может вызвать несколько чтений, каждое из которых извлекает больше данных, чем требуется для запроса. При неэффективной организации хранилища извлечение 1 000 подходящих строк может легко привести к десяткам или сотням мегабайт ненужных операций ввода-вывода, а в крайних случаях — к гораздо большему объему.
Уменьшение размера групп строк облегчает точечный поиск, но ухудшает сканирование. Слишком много мелких фрагментов снижает эффективность сжатия, увеличивает накладные расходы на метаданные и нарушает длительные последовательные чтения, от которых зависят аналитические движки.
Поэтому проблема заключается не в поиске единственного «идеального» размера группы строк. Проблема в том, что от одного и того же набора данных требуют вести себя как две разные системы хранения.
Гибридный поиск объединяет оба пути в один запрос
Гибридный поиск делает этот конфликт более заметным. Один запрос может сначала применить скалярные фильтры:
aesthetic_score > 0.8 AND duration > 5
Затем выполняется поиск с использованием нейронной сети (ANN).
Затем он извлекает подписи, векторы и метаданные по идентификатору строки.
Для пользователя это один поисковый запрос. Для уровня хранения это и аналитическое сканирование, и произвольный поиск с низкой задержкой.
Именно поэтому векторному хранилищу требуется нечто большее, чем просто улучшенные настройки Parquet. Ему нужен способ размещать различные столбцы в соответствии с тем, как они фактически считываются.
Третья проблема: набор данных не находится внутри одного движка
Первые две проблемы возникают внутри базы данных. Третья возникает на границе между системами.

Конвейеры данных ИИ охватывают множество систем
В видео-рабочем процессе в самой векторной базе данных происходит очень мало.
Исходные видео хранятся в объектном хранилище. Генерация клипов может выполняться в Spark или Ray. Оценка эстетических характеристик может выполняться в сервисе на GPU. Создание субтитров может выполняться в конвейере инференции LLM. Вложения могут генерироваться другим заданием на GPU. Редкие векторы могут поступать из сервиса SPLADE. Офлайн-оценка, фильтрация обучающих данных, проверка людьми и задачи управления могут выполняться в других местах.
Векторная база данных обслуживает онлайн-поиск, но набор данных формируется, корректируется, оценивается и расширяется множеством систем.
Частные форматы хранения создают множество копий «истинного» набора данных
Если база данных использует собственный физический формат, который только она сама может читать и записывать, каждому внешнему заданию требуется экспорт, преобразование, копирование и импорт. Один и тот же набор данных может существовать в базе данных, во временном каталоге Spark, в результатах оценки и в локальном каталоге для заполнения данных. Тогда возникает реальный вопрос:
- Какая копия является источником достоверной информации?
- В какой из них содержится модель подписей за прошлый месяц?
- Какие строки уже были исправлены в результате проверки специалистом?
- Какой столбец разреженного вектора был сгенерирован какой моделью?
- Какой векторный индекс остаётся действительным после заполнения?
- На какой исходный видеообъект ссылается эта строка?
В небольших масштабах команды иногда могут обходиться конвенциями именования и ручными проверками. Однако при наличии сотен миллионов строк и терабайтов вложений это становится проблемой согласованности.
Векторные наборы данных нуждаются в общем состоянии с управлением версиями
Системы Lakehouse решили одну из версий этой проблемы для структурированных данных. Iceberg, Delta Lake и Hudi — это не просто хранилища файлов. Их основной вклад заключается в том, что они позволяют нескольким движкам координировать работу на основе одного и того же состояния таблицы.
Векторным базам данных теперь нужна аналогичная возможность, но их состояние более сложное. Оно должно включать не только файлы таблиц и разбиения, но также векторные индексы, текстовые индексы, разреженные признаки, журналы удалений, статистику, диапазоны идентификаторов строк и ссылки на внешние BLOB-объекты.
Вопрос заключается не просто в том, «может ли Spark читать файлы Milvus?»
Вопрос заключается в том, как, после того как Spark заполнит разреженный векторный столбец, Milvus узнает, к какой версии относится этот столбец, какие строки он охватывает, какая модель его сгенерировала и когда его можно безопасно использовать в онлайн-запросах?
Ответ должен быть заложен в модели хранения.
Почему исправлений недостаточно
Заманчиво рассматривать их как три отдельные инженерные задачи.
- Амплификация записи? Добавьте пакетную обработку.
- Точечное чтение? Добавьте кэш.
- Внешние системы? Добавьте инструменты экспорта и импорта.
Эти исправления могут помочь, но они не решают основную проблему: векторный набор данных физически неоднороден.

В примере из видео clip_id, video_id, duration и aesthetic_score представляют собой короткие скалярные поля. Они полезны для фильтрации и анализа.
caption— это текст. Его можно использовать для BM25, проверки, исправления и заполнения пробелов.embedding— длинный плотный вектор. Он используется для расчета реколла в нейронной сети (ANN), а впоследствии — для поиска на уровне строк или переранжирования.embedding_v2— это новый результат модели, часто заполняемый значительно позже после вставки исходных данных.sparse_vectorподдерживает гибридный поиск и имеет собственную схему доступа.- Исходное видео должно оставаться в объектном хранилище. База данных должна хранить ссылку, контрольную сумму, тип MIME, версию парсера и связь на уровне строк.
- Векторные индексы, текстовые индексы, статистические данные и журналы удаления являются производными объектами со своей собственной семантикой версий.
Эти объекты используют одну логическую строку, но не должны иметь одинаковую физическую структуру или жизненный цикл.
- Если их принудительно поместить в одну обычную таблицу, обновления станут ресурсоемкими.
- Если их принудительно объединить в один столбцовый формат файла, точка чтения станет дорогостоящей.
- Если к ним относиться как к несвязанным объектным файлам, управление версиями становится неустойчивым.
Поэтому модель хранения должна исходить из того, что набор данных является гетерогенным.
Это приводит к трем требованиям к проектированию:
- Во-первых, разные группы столбцов должны храниться в разных физических форматах.
- Во-вторых, этим группам столбцов требуется общее пространство идентификаторов строк, чтобы они по-прежнему могли вести себя как единая логическая таблица.
- В-третьих, набору данных требуется манифест с версиями, в котором указывается, какие файлы, индексы, журналы, статистические данные и ссылки на объекты относятся к текущему представлению.
Именно на этом принципе построен Loon — наш новый механизм хранения, лежащий в основе Milvus и Zilliz Cloud.
Loon: механизм хранения, лежащий в основе Milvus и Zilliz Cloud, предназначенный для развивающихся векторных наборов данных
Чтобы решить все вышеперечисленные проблемы, мы создали Loon — новый механизм хранения для Milvus и Zilliz Vector Lakebase (следующего поколения Zilliz Cloud), разработанный специально для развивающихся векторных наборов данных.
Название следует традиции Zilliz называть свои продукты именами птиц. «Loon» — это ныряющая птица, обитающая на озёрах, что хорошо соотносится с целью системы: векторная база данных не должна перемещать, сканировать или перезаписывать целое «озеро» данных каждый раз, когда она выполняет запрос, заполняет столбец или создаёт индекс. Сначала она должна понять текущую версию набора данных, включая его столбцы, индексы, статистику, журналы удаления и ссылки на объекты, а затем считывать только ту часть, которая ей действительно нужна.
Гибридные форматы файлов, выравнивание идентификаторов строк и Manifest — это не три отдельных функции. Все они вытекают из одного и того же проектного допущения: векторный набор данных по своей сути является гетерогенным.
Три компонента — одна модель хранения
Гибридные форматы файлов учитывают, что разные столбцы имеют разные схемы доступа. Скалярные поля подходят для сканирования и фильтрации. Векторные поля требуют эффективного поиска на уровне строк. Необработанные объекты, такие как видео, PDF-файлы, изображения и аудиофайлы, должны храниться в объектном хранилище, а не внутри файлов данных базы данных.
Выравнивание идентификаторов строк учитывает, что эти столбцы могут быть физически разделены, но по-прежнему описывают одни и те же логические строки. Подпись, вложение, разреженный вектор и URI видео могут находиться в разных файлах и форматах, но их все равно необходимо объединить в один результат.
Манифест учитывает, что набор данных не записывается один раз и не остается неизменным. Он будет модифицироваться множеством систем, в рамках нескольких версий, для выполнения различных задач. Индексы, статистические данные, журналы удаления, ссылки на внешние объекты и группы столбцов должны отображаться в одном и том же версионированном представлении.
Именно поэтому Loon — это не просто более быстрый формат векторных файлов. Более быстрый формат облегчает поиск по индексу, но не решает проблемы эволюции схемы или координации между несколькими движками. Согласование идентификаторов строк позволяет разделённым столбцам вести себя как единая таблица, но не указывает, какие файлы относятся к текущей версии. Манифест может описывать состояние набора данных, но без групп столбцов и выравнивания идентификаторов строк он не может четко представлять различные физические схемы внутри одной логической коллекции.
Модель хранения нуждается во всех трёх компонентах: различных форматах для разных групп столбцов, общем пространстве идентификаторов строк для реконструкции строк и версионированном манифесте, который сообщает каждому читателю и записывающему устройству, каким является набор данных в данный момент.
Место Loon в Milvus и Zilliz Vector Lakebase
В Milvus он заменяет старый уровень хранения сегментов бинарного журнала (binlog) на модель, построенную вокруг абстракций Manifest, ColumnGroup, формата файлов и файловой системы. В Zilliz Vector Lakebase (следующем этапе развития Zilliz Cloud) тот же подход применяется к архитектуре Vector Lakebase: обеспечить высокую скорость работы векторной базы данных, одновременно упростив эволюцию, анализ и координацию базовых данных с внешними системами.
Компоненты Milvus верхнего уровня по-прежнему выполняют привычные для них роли. Proxy отвечает за маршрутизацию. QueryCoord и DataCoord отвечают за планирование. IndexNode создает индексы. API, ориентированные на приложения, для сбора данных, вставки, поиска и гибридного поиска не требуют раскрытия файлов Manifest или ColumnGroups.
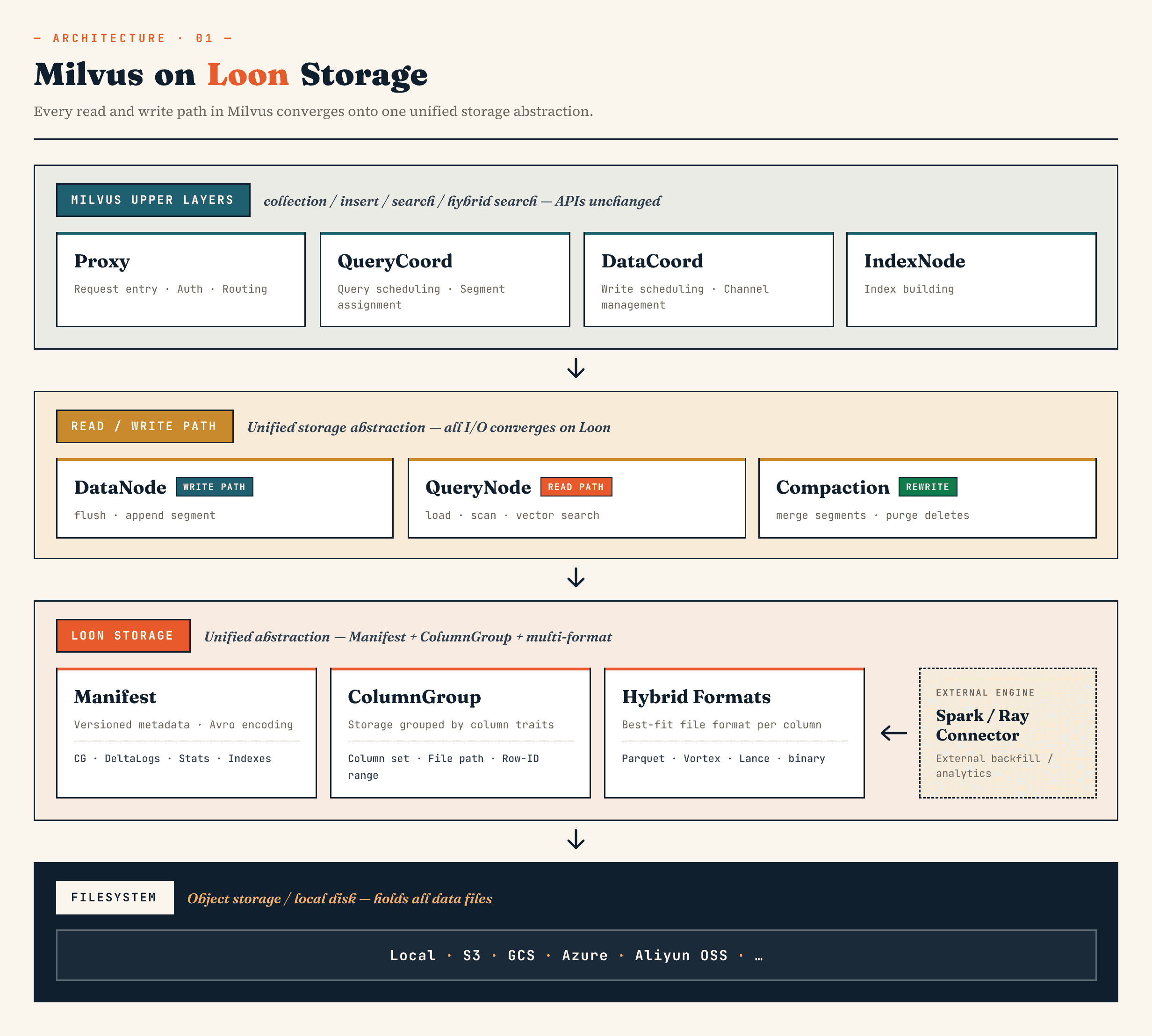
Изменения происходят на нижнем уровне.
DataNode, QueryNode, segcore, уплотнение и внешние коннекторы могут работать через одну и ту же абстракцию хранилища. Это важно, поскольку набор данных больше не записывается и не считывается исключительно базой данных. Он может одновременно расширяться внешними вычислительными системами и использоваться для онлайн-поиска.
На высоком уровне уровни выглядят следующим образом:
Manifest
→ ColumnGroup
→ file format layer
→ filesystem abstraction
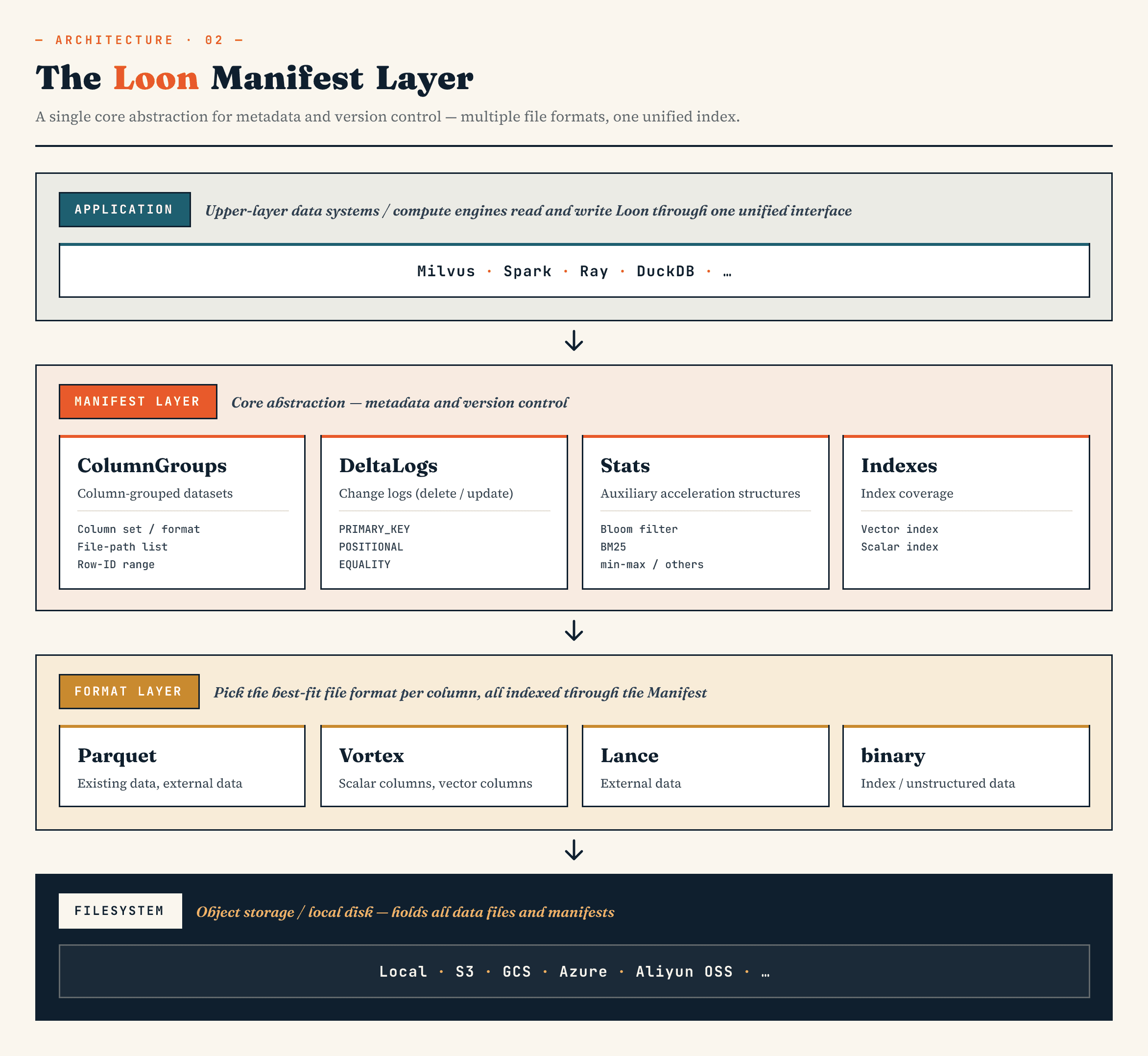
Manifest описывает версионированное состояние набора данных. ColumnGroups сопоставляют логическую коллекцию физическим группам столбцов. Уровень формата файлов позволяет каждой ColumnGroup выбирать подходящий формат. Абстракция файловой системы работает как с объектным хранилищем, так и с локальным хранилищем.
Важно отметить, что гибридные форматы файлов, выравнивание идентификаторов строк и Manifest не являются отдельными функциями. Вместе они определяют модель хранения.
Имея эту модель, мы можем рассмотреть три варианта проектирования по очереди: как Loon хранит различные ColumnGroups, как он выравнивает их обратно в строки и как Manifest превращает эти файлы в набор данных с версиями.
Вариант 1: использование подходящего формата файла для конкретной группы столбцов
Различные столбцы имеют разные схемы доступа. Их не следует принудительно помещать в один и тот же формат файла.
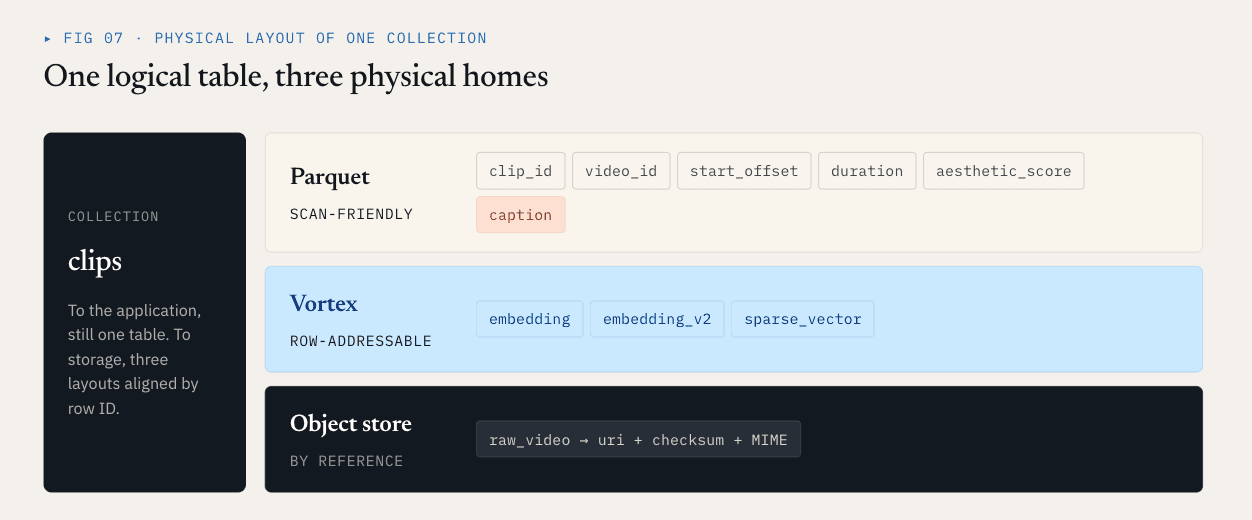
Loon разделяет логическое собрание на ColumnGroups.
- Скалярные поля, поля фильтрации, бизнес-ключи и статистические поля часто сканируются, фильтруются, агрегируются или используются для планирования запросов. Для них полезны сжатие, обрезка столбцов и совместимость с экосистемой. Parquet хорошо подходит для этих столбцов.
- Плотные векторы, разреженные векторы и признаки для переранжирования часто считываются после вызова ANN по идентификатору строки. Им требуется произвольный доступ с низкой задержкой, точное чтение диапазонов байтов и выборочное декодирование. В этом случае лучше подходит сегментная организация данных. Loon использует Vortex для этих целей.
- Необработанные объекты, такие как видео, PDF-файлы, изображения и аудиофайлы, не должны встраиваться в файлы данных векторной базы данных. Они должны оставаться в объектном хранилище. База данных фиксирует ссылки, контрольные суммы, типы MIME, версии парсеров и связи на уровне строк.
На примере видео физическая организация может выглядеть следующим образом:
Parquet ColumnGroup:
clip_id / video_id / start_offset / duration / aesthetic_score / caption
Vortex ColumnGroups:
embedding
embedding_v2
sparse_vector
Object storage:
raw video objects
Для приложения это по-прежнему одна коллекция. С точки зрения уровня хранения, разные части этой коллекции используют разные физические форматы. Это напрямую сокращает количество ненужных перезаписей. Добавление « embedding_v2 » может превратиться в новую векторную ColumnGroup плюс фиксацию манифеста. Это не требует перезаписи столбца с подписями, скалярных метаданных или существующего столбца вложений.
Та же идея применима к разреженным векторам, переранжированным признакам или другим производным полям. Если новый столбец может быть физически независимым и выравниваться по идентификатору строки, ему не нужно затягивать несвязанные столбцы в тот же путь перезаписи.
Loon также адаптирует использование форматов файлов.
Для Parquet настройки по умолчанию не всегда идеальны для данных с большим количеством векторов. Группа строк размером 64 МБ может оказаться слишком большой для точечного поиска, поскольку небольшой случайный чтение может привести к извлечению гораздо большего объема данных, чем требуется. Loon сжимает группы строк до 1 МБ в соответствующих путях и отключает кодировки, такие как словарная кодировка векторных столбцов, когда они не способствуют поиску по случайным векторным данным.
Для Vortex более важную роль играет организация массива. Loon использует организацию, которая обеспечивает баланс между эффективностью сканирования и точечным поиском. В пределах группы строк сегменты из связанных столбцов могут размещаться близко друг к другу для оптимизации сканирования. При выполнении операций чтение подсегментов позволяет системе извлекать только нужные байты, а не загружать весь сегмент целиком.
Loon также поддерживает интеграцию с Lance в режиме «только для чтения», поэтому существующие наборы данных Lance можно монтировать в качестве ColumnGroups, когда важна совместимость.
Что показывают результаты тестирования
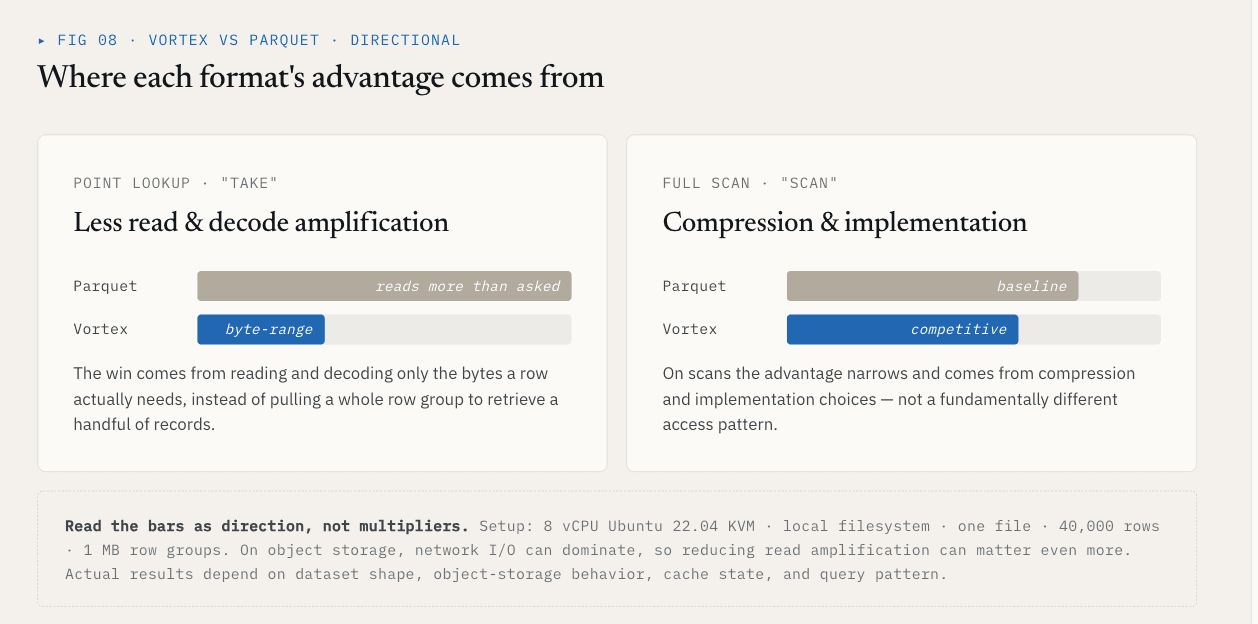
В одном локальном тесте с использованием одного файла, содержащего 40 000 строк, и схемы {id: int64, name: utf8, value: float64, vector: list<float32>[128]} Vortex продемонстрировал следующие результаты по сравнению с Parquet с группами строк размером 1 МБ:
| Операция | Vortex | Parquet | Разница |
|---|---|---|---|
| Извлечение, K = 1000 случайных строк | 5,8 мс | 144 мс | В 25 раз быстрее |
| Полное сканирование векторных столбцов | 21 мс | 142 мс | в 6,76 раз быстрее |
| Размер файла: ~21 МБ необработанных данных | 6,62 МБ | 7,16 МБ | на 7 % меньше |
Результат « take » достигается за счет сокращения объема нерелевантных данных, которые необходимо прочитать и декодировать. Результат сканирования обусловлен выбором методов сжатия и реализации.
Эти цифры следует рассматривать в контексте конкретной конфигурации: 8 виртуальных процессоров (vCPU) на Ubuntu 22.04 с KVM, локальная файловая система, один файл, 40 000 строк, группы строк по 1 МБ и приведенная выше схема. В объектном хранилище сетевой ввод-вывод может играть доминирующую роль, поэтому снижение коэффициента усиления чтения может иметь ещё большее значение. Фактические результаты зависят от формы набора данных, поведения объектного хранилища, состояния кэша и шаблона запросов.
Более общий вывод заключается не в том, что для каждого столбца следует использовать Vortex.
Суть в том, что для векторных наборов данных необходимо выбрать формат файла на уровне ColumnGroup.
Вариант 2: выравнивание физических файлов по идентификаторам строк
Гибридные форматы файлов решают одну проблему: теперь разные столбцы могут храниться в тех форматах, которые им лучше всего подходят.
Но это порождает вторую проблему. Если скалярные поля хранятся в Parquet, векторы — в Vortex, а необработанные объекты — в объектном хранилище, как система может по-прежнему рассматривать их как единую коллекцию?
Loon решает эту проблему с помощью выравнивания по идентификаторам строк.
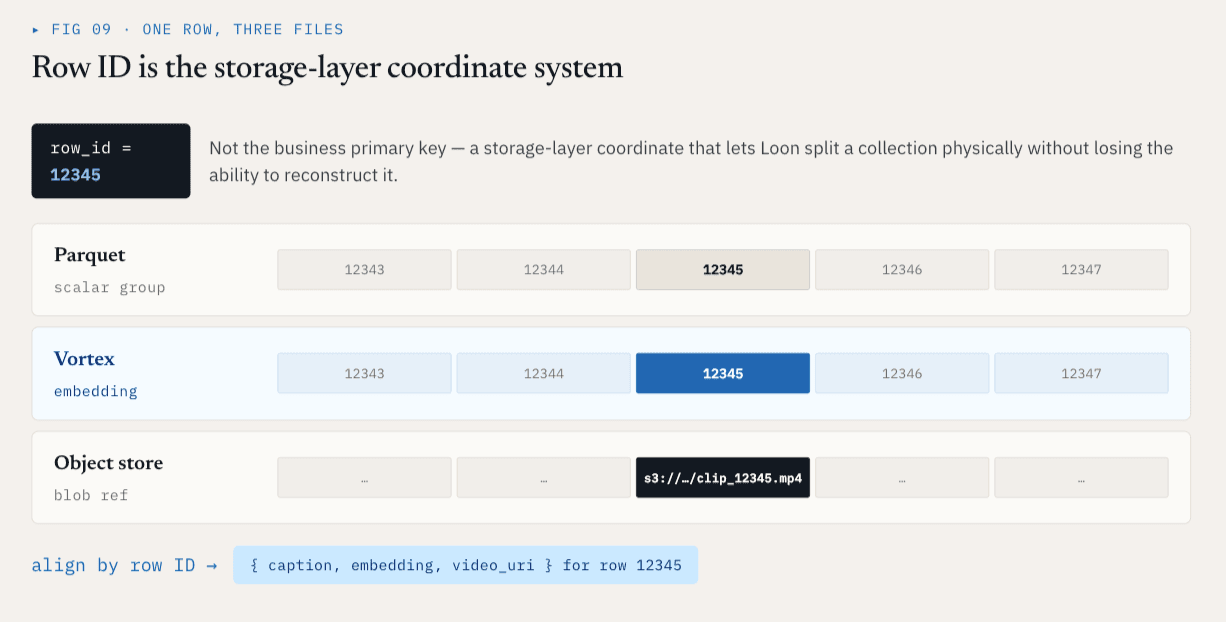
Идентификатор строки — это система координат на уровне хранилища
Каждый физический файл ColumnGroupFile фиксирует путь к файлу и диапазон идентификаторов строк, который он охватывает:
path
start_index
end_index
Различные ColumnGroups могут охватывать одно и то же пространство идентификаторов строк, даже если они находятся в разных файлах и форматах.
Для идентификатора строки 12345 скалярные метаданные могут находиться в ColumnGroup формата Parquet, встроенные данные — в ColumnGroup формата Vortex, а исходное видео может быть представлено ссылкой на объектное хранилище. С логической точки зрения они по-прежнему составляют одну строку. Это обеспечивает уровню хранения стабильную систему координат.
Идентификатор строки не является первичным ключом бизнес-модели. Это система координат уровня хранения, которая позволяет Loon физически разбивать коллекцию, не теряя при этом возможности логически ее реконструировать.
Новые столбцы не требуют перезаписи старых
Добавление векторных групп столбцов ( embedding_v2 ) не требует перезаписи исходных групп столбцов «caption», «metadata» или « embedding_v1 ». Loon может записать новую векторную группу столбцов, зафиксировать охватываемый ею диапазон идентификаторов строк и зафиксировать это изменение через манифест.
То же самое относится к разреженным векторам, переранжированным признакам или другим производным полям, которые поступают позже.
Если новая ColumnGroup охватывает нужный диапазон идентификаторов строк, она может присоединиться к той же логической коллекции, не вынуждая перемещать несвязанные данные.
Удаления и уплотнение могут быть более целенаправленными
Выравнивание идентификаторов строк также помогает при удалении.
Удаление сначала можно зафиксировать в журнале удалений. Строка становится невидимой на логическом уровне, а физическая очистка откладывается до момента уплотнения. Когда уплотнение в конечном итоге запускается, ему не всегда требуется перезаписывать каждую ColumnGroup, связанную с затронутыми строками. Оно может сосредоточиться на тех ColumnGroups, которые нуждаются в очистке.
Это важно, поскольку не все столбцы имеют одинаковую стоимость. Перезапись короткой скалярной ColumnGroup сильно отличается от перезаписи сотен гигабайт плотных векторов.
Гибридный поиск может извлекать только те столбцы, которые ему нужны
Выравнивание идентификаторов строк также делает гибридный поиск практичным в сочетании с гибридными форматами файлов.
После того как поиск ANN возвращает идентификаторы строк-кандидатов, система может извлечь только те поля, которые необходимы для окончательного результата: заголовки, метаданные, векторы, признаки для повторного ранжирования или ссылки на объекты.
Например, для запроса могут потребоваться:
caption
embedding
video_uri
Эти поля могут находиться в разных ColumnGroups. Loon может найти соответствующие файлы по диапазону идентификаторов строк, прочитать необходимые диапазоны байтов и сформировать результат.
Без выравнивания по идентификаторам строк гибридные форматы представляли бы собой просто отдельные файлы, расположенные рядом друг с другом. Благодаря выравниванию по идентификаторам строк они ведут себя как единая логическая коллекция.
Packed Reader скрывает это разделение от верхнего уровня
Компонентом среды выполнения, обеспечивающим эту функциональность, является Packed Reader.
Верхний уровень видит единый поток Arrow RecordBatch. На нижнем уровне данные могут поступать из нескольких ColumnGroups в разных форматах файлов. Packed Reader скрывает эти различия, выравнивает данные по диапазонам идентификаторов строк и планирует многофайловый ввод-вывод с контролируемым использованием памяти.
Он также поддерживает прямой запрос « take » по идентификатору строки. По заданному набору идентификаторов строк он находит соответствующие ColumnGroupFiles, запускает чтение диапазонов и возвращает запрошенные поля.
Для видео-рабочего процесса запрос ANN может потребовать операции « caption », « embedding » и « video_uri ». Packed Reader может извлекать скалярную ColumnGroup и векторную ColumnGroup, не затрагивая несвязанные столбцы.
В этом заключается разница между «отдельными файлами» и «таблицей с несколькими физическими структурами».
Вариант 3: сделать манифест единственным источником достоверной информации
Гибридные форматы файлов определяют, как данные хранятся физически. Выравнивание идентификаторов строк определяет, как разделённые ColumnGroups всё же образуют единую логическую таблицу. Но системе всё ещё нужно ответить на более важный вопрос: какие файлы, журналы, статистические данные, индексы и ссылки на объекты относятся к текущей версии набора данных? Это задача манифеста.

Каталогов объектного хранилища недостаточно
Объектное хранилище — это не каталог базы данных. Каталог может содержать старые файлы, новые файлы, результаты неудачных заданий, временные файлы, журналы удаления, файлы, на которые по-прежнему ссылаются старые моментальные снимки, и файлы, ожидающие очистки. Сам факт существования файла не означает, что он принадлежит текущей версии набора данных.
Набор данных Loon может быть организован в такие каталоги:
_metadata/
_data/
_delta/
_stats/
_index/
Однако структура каталогов не является источником достоверной информации. Им является манифест. Читатели не должны перечислять каталоги и делать выводы о состоянии на основе тех файлов, которые случайно там находятся. Им следует читать текущий манифест и руководствоваться объявленным в нём версионированным представлением.
Манифест определяет одно версионированное представление набора данных
Манифест определяет набор данных в данной версии. В нём фиксируется:
- какие ColumnGroups существуют
- какие диапазоны идентификаторов строк они охватывают
- какой физический формат использует каждая ColumnGroup
- где находятся файлы
- какие журналы удаления активны
- какие статистические данные доступны
- какие индексы существуют
- на какие внешние BLOB-объекты есть ссылки
- какие столбцы и диапазоны строк охватывают эти статистические данные или индексы
При каждом обновлении записывается новая версия манифеста. Читатель, открывающий версию N, видит стабильное представление набора данных в версии N. Записывающий пользователь может подготовить версию N+1, не мешая читателям, которые все еще используют версию N.
Манифест отслеживает не только файлы таблиц
В Loon тело манифеста кодируется с помощью Apache Avro и состоит из четырёх основных разделов.
- ColumnGroups описывают столбцы, форматы, файлы и диапазоны идентификаторов строк.
- DeltaLogs описывают удаления. Различные типы удалений охватывают разные источники изменений, такие как удаления по первичному ключу со стороны клиентов, позиционные удаления в результате внутренней компактизации или удаления по равенству из внешних движков.
- Stats включают метаданные планирования, такие как фильтры Блума, статистику BM25 и минимальные/максимальные значения.
- Indexes описывают тип индекса, параметры, охватываемые столбцы и диапазоны идентификаторов строк. Сюда могут входить векторные индексы, такие как HNSW или IVF, текстовые индексы, инвертированные индексы, растровые индексы и связанные структуры.
Именно в этом Loon отличается от традиционного манифеста таблиц.
Векторный набор данных должен отслеживать не только файлы данных и разбиения. Он также должен отслеживать векторные индексы, текстовые индексы, разреженные характеристики, журналы удалений, статистику, ссылки на внешние объекты и диапазоны идентификаторов строк, которые их связывают.
Манифест должен быть доступен для записи не только из базы данных
Самое важное — не только то, что содержит манифест, но и то, кто может в него записывать.
- Если запись в манифест может осуществлять только база данных, он остаётся внутренними метаданными. Более «чистые» метаданные, но всё равно доступные только одному движку.
- Если внешние движки могут генерировать новые ColumnGroups, статистику и записи в манифесте, манифест становится интерфейсом координации.
- Например, задание Spark может заполнить разреженный векторный столбец. Оно записывает новую ColumnGroup, фиксирует охват строк и статистику, а также фиксирует новый манифест. Онлайн-запросы могут продолжать считывать старую версию во время выполнения задания. Как только фиксация завершится успешно, новая версия становится видимой.
По сути это похоже на Iceberg и Delta Lake, но объектная модель шире. Набор данных векторного типа должен отслеживать векторные индексы, текстовые индексы, разреженные признаки, журналы удалений, статистику, ссылки на BLOB и диапазоны идентификаторов строк, а не только файлы таблиц и партиции.
Оптимистические фиксации упрощают обновление версий
Каждая фиксация записывает новую версию манифеста. Записывающий модуль может создать новое содержимое на основе версии N, а затем попытаться записать его в версию N ( manifest-{N+1}.avro). Семантика условной записи в объектном хранилище или сопоставления поколений может привести к сбою фиксации, если данная версия уже существует. Затем записывающий модуль может повторить попытку с более новой версией.
Это обеспечивает Loon оптимистическую параллельность, не заставляя каждое обновление проходить через тяжелый путь координации с жесткой согласованностью. Без Manifest многоформатное и многодвижковое хранилище в конечном итоге сводится к соглашениям об именовании и ручной синхронизации. Это может работать для небольших наборов данных. Но не работает для векторных данных масштаба ТБ.
Именно манифест превращает разнородные файлы в набор данных, который несколько систем могут безопасно читать и обновлять.
Что меняется для пользователей при переходе к версионированию хранилища
Для разработчиков приложений Loon не должен стать новым бременем в виде API.
Пользователи по-прежнему должны работать с привычными концепциями Milvus: коллекциями, вставками, поиском и гибридным поиском. Им не должно быть необходимости думать о файлах Manifest, ColumnGroups, диапазонах идентификаторов строк или структуре файлов в ходе обычной разработки приложений.
Изменения происходят на более глубоком уровне. Система хранения становится более адаптированной к тому, как наборы данных для ИИ фактически развиваются.
Добавление нового вложения не должно приводить к перемещению старых данных
Раньше добавление встроенного представления ( embedding_v2 ) в существующую коллекцию часто требовало экспорта данных, обучения новой модели, генерации векторов, а затем повторного импорта или массового обновления коллекции через SDK. Такой подход создает значительный объем операционной работы: отслеживание версий, повторные попытки выполнения сбойных заданий, перестроение индексов, влияние на обслуживание и проверки согласованности.
С помощью Loon это можно реализовать как эволюцию схемы плюс новую фиксацию ColumnGroup. Новый столбец вложения можно записать как отдельную физическую ColumnGroup, выровненную по ID строки, и сделать видимым через Manifest. Старый столбец заголовка, столбец скалярных метаданных и исходный столбец вложения перемещать не нужно.
Заполнение пробелов не должно требовать цикла обновлений на стороне клиента
Многие обновления данных ИИ представляют собой заполнение пробелов. Команда может добавлять разреженные векторы после того, как гибридный поиск станет важным. Она может добавлять признаки для переранжирования после обучения новой модели. Она может исправлять подписи после проверки человеком. Она может добавлять теги управления после обновления политики.
В традиционной архитектуре эти изменения часто происходят посредством обновлений клиентского SDK или путей записи исключительно в базу данных, даже если данные генерируются Spark, Ray или другим внешним движком.
С помощью Loon внешние вычислительные системы могут генерировать новые ColumnGroups и фиксировать их через Manifest. База данных больше не должна быть единственной точкой входа для каждой перезаписи.
Для офлайн-анализа не должна требоваться дополнительная копия исходных данных
Раньше команды часто экспортировали онлайн-коллекцию в формат Parquet для офлайн-оценки или анализа. Это приводило к появлению двух версий одного и того же набора данных: онлайн-коллекции и копии для анализа. После исправления подписей, повторного генерации вложений, применения журналов удаления или перестроения индексов команде приходилось выяснять, какая копия является актуальной.
Благодаря модели хранения на основе Manifest аналитические движки могут считывать ту же версионированную представление набора данных, что и система обслуживания. Они могут проецировать только те столбцы, которые им нужны, сканировать только соответствующие диапазоны строк и работать с объявленной версией набора данных вместо вручную экспортированного моментального снимка.
Удаления и исправления должны затрагивать только то, что изменилось
Удаления, исправления подписей, корректировки меток и обновления правил управления являются рутинными операциями в наборах данных ИИ. Они не должны заставлять каждый столбец с длинным вектором проходить через один и тот же путь перезаписи.
С помощью Loon удаление журналов сначала можно рассматривать как логическое удаление. Позже, в ходе уплотнения, можно очистить затронутые ColumnGroups без перезаписи несвязанных данных. Если изменяется короткое текстовое поле, уровень хранения не должен перезаписывать сотни гигабайт плотных векторов только потому, что они находятся в одной логической строке.
Внешние движки становятся частью рабочего процесса, а не «запасным выходом»
Более значительным изменением является то, что внешние движки больше не рассматриваются как системы, находящиеся вне векторной базы данных.
Spark, Ray, задания оценки, системы маркировки и конвейеры управления уже генерируют и модифицируют значительную часть данных. Уровень хранения должен позволять им взаимодействовать на основе единого достоверного источника данных, а не постоянно заниматься экспортом, копированием и повторным импортом.
Именно это и делает возможным одна из версий Manifest. Она предоставляет онлайн-обслуживанию, офлайн-анализу, заданиям по заполнению пробелов и уплотнению общий вид на набор данных.
Это может показаться деталью внутреннего хранения, но на самом деле влияет на то, насколько быстро команды могут проводить итерации над наборами данных для ИИ. Каждое изменение модели, доработка признаков, исправление подписей, фильтрация по качеству и перестроение индекса зависят от одного и того же вопроса:«Может ли система обновить набор данных, не перемещая те данные, которые перемещать не нужно?»
В этом и заключается практическая ценность модели хранения.
Loon доступен в бета-версии Milvus 3.0 и Zilliz Vector Lakebase
Loon доступен в бета-версии Milvus 3.0, а также входит в состав уровня хранения в Zilliz Vector Lakebase — следующем этапе развития Zilliz Cloud. В этом выпуске основное внимание уделяется трем ключевым направлениям:
- Манифест. Цель состоит в том, чтобы операции записи, дозаполнения, удаления, сбора статистики и обновления индексов создавали версионированные представления наборов данных, которые читатели могут открывать с гарантированной согласованностью. Для читателей это означает, что запрос может открыть конкретную версию Manifest и получить стабильное представление набора данных. Для записывающих это означает, что новые файлы данных, журналы удаления, статистику или файлы индексов можно сначала подготовить, а затем сделать видимыми посредством фиксации с версионностью.
- Поддержка ColumnGroup и форматов. Parquet поддерживает скалярные столбцы и столбцы, совместимые с экосистемой. Vortex поддерживает модели доступа с интенсивным использованием векторных данных. Lance можно интегрировать в режиме «только для чтения» для обеспечения совместимости с существующими наборами данных Lance.
- Индекс в Lake. Скалярные статистические данные, фильтрующие индексы и инвертированные текстовые индексы могут участвовать в планировании на основе Manifest по диапазону строк. Векторные индексы, встроенные в Lake, задействованы в большей степени. HNSW и IVF по-разному ведут себя в объектном хранилище, причём HNSW особенно чувствителен к произвольному доступу и локальности кэша. Нельзя просто повторно использовать макет, разработанный для локального SSD, и ожидать того же результата.
Впереди ещё много работы
- Внешние пути записи имеют значение, поскольку Spark и Ray должны иметь возможность генерировать ColumnGroups и фиксации Manifest, не заставляя каждую операцию заполнения проходить через цикл клиентского SDK.
- Важнасовместимость с Lakehouse, поскольку многие команды уже используют каталоги и механизмы запросов , такие как Iceberg, Delta Lake, Trino, DuckDB и Athena. Векторные данные должны иметь возможность участвовать в этой экосистеме без потери производительности векторного поиска.
- Расположение индекса имеет значение, поскольку графовые индексы и инвертированные структуры имеют разные схемы доступа в объектном хранилище.
- Семантика больших объектов важна, поскольку необработанные видео, PDF-файлы, изображения и аудиофайлы требуют управления ссылками, управления версиями и поведения при удалении, согласованного с производным векторным набором данных.
Точное поведение релиза, настройки по умолчанию и путь миграции должны соответствовать соответствующим примечаниям к релизам Milvus и Zilliz Cloud. Однако направление развития хранилищ ясно: векторным базам данных нужна версионируемая, встроенная в «озеро» основа под уровнем обслуживания.
Попробуйте Loon на базе Zilliz Vector Lakebase
Если ваш текущий стек разделяет рабочие процессы онлайн-обслуживания, офлайн-анализа, заполнения данных и работы с внешними озерами данных на разные системы, стоит обратить внимание на Zilliz Vector Lakebase. Вы можете опробовать его в Zilliz Cloud. При регистрации с рабочим адресом электронной почты вы получаете 100 долларов бесплатных кредитов. Вы также можете связаться с нами, чтобы обсудить ваш конкретный сценарий использования.
Вы также можете следить за выпуском Milvus 3.0, чтобы увидеть, как Loon развивается в рамках этого движка с открытым исходным кодом.
Zilliz Vector Lakebase объединяет:
- Многоуровневое обслуживание для различных компромиссов между производительностью в реальном времени и затратами
- Поиск по запросу для крупномасштабных или исследовательских рабочих нагрузок без постоянного использования вычислительных ресурсов
- Поиск во внешнем озере данных, позволяющий индексировать и выполнять поиск непосредственно по существующим данным озера
- Полноспектральный поиск по векторным, текстовым, JSON- и геопространственным данным с гибридным извлечением и переранжированием
- Единое хранилище, встроенное в «озеро» данных и построенное на базе Vortex — открытого формата, разработанного для более быстрого и экономичного произвольного чтения данных с преобладанием векторных элементов
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word