How to Choose the Right Embedding Model?
Selecting the right embedding model is a critical decision when building systems that understand and work with unstructured data like text, images, or audio. These models transform raw input into fixed-size, high-dimensional vectors that capture semantic meaning, enabling powerful applications in similarity search, recommendations, classification, and more.
But not all embedding models are created equal. With so many options available, how do you choose the right one? The wrong choice can lead to suboptimal accuracy, performance bottlenecks, or unnecessary costs. This guide provides a practical framework to help you evaluate and select the best embedding model for your specific requirements.
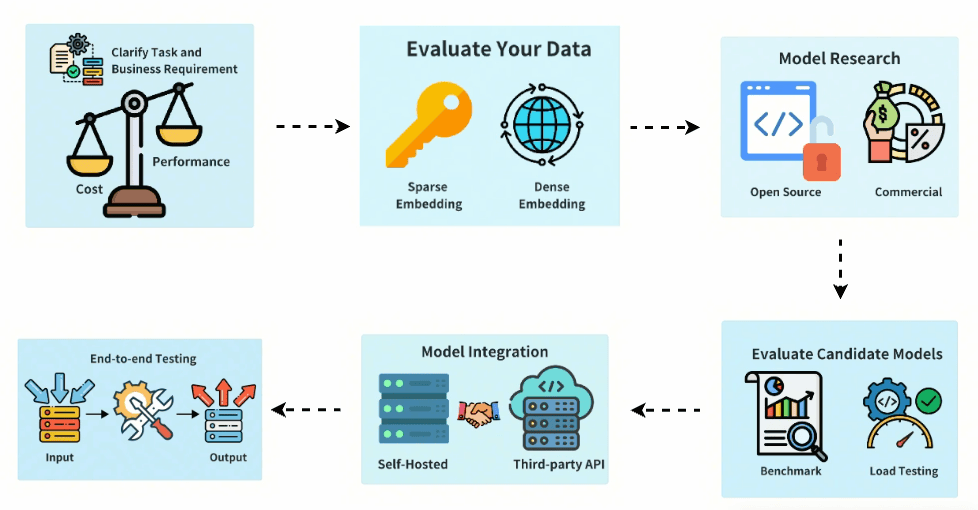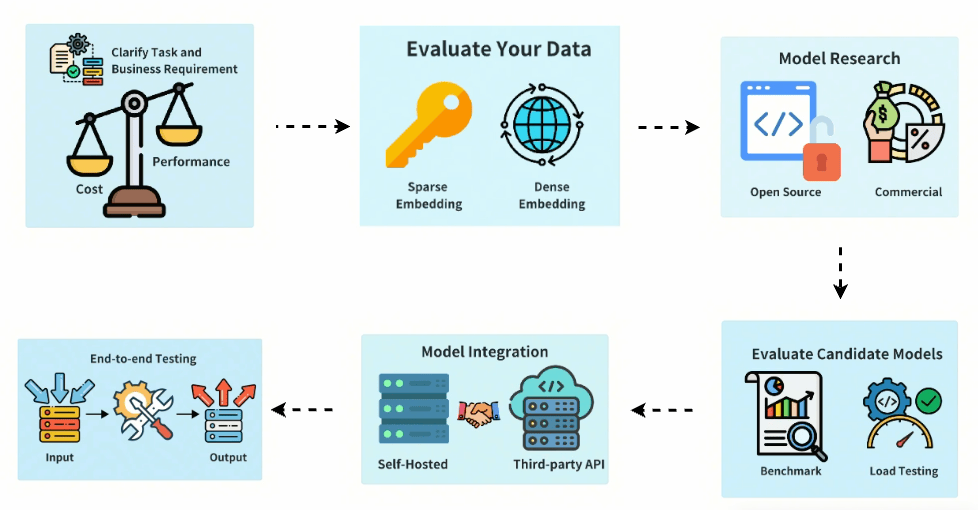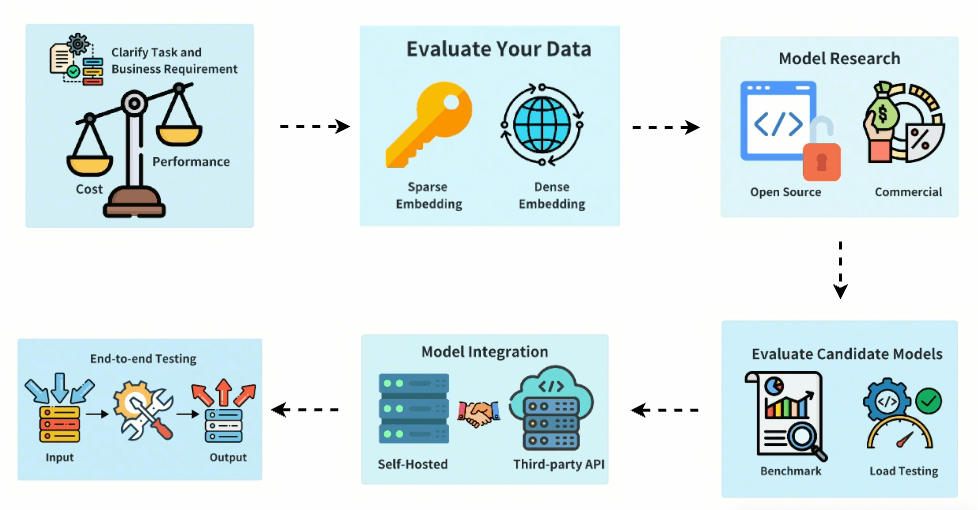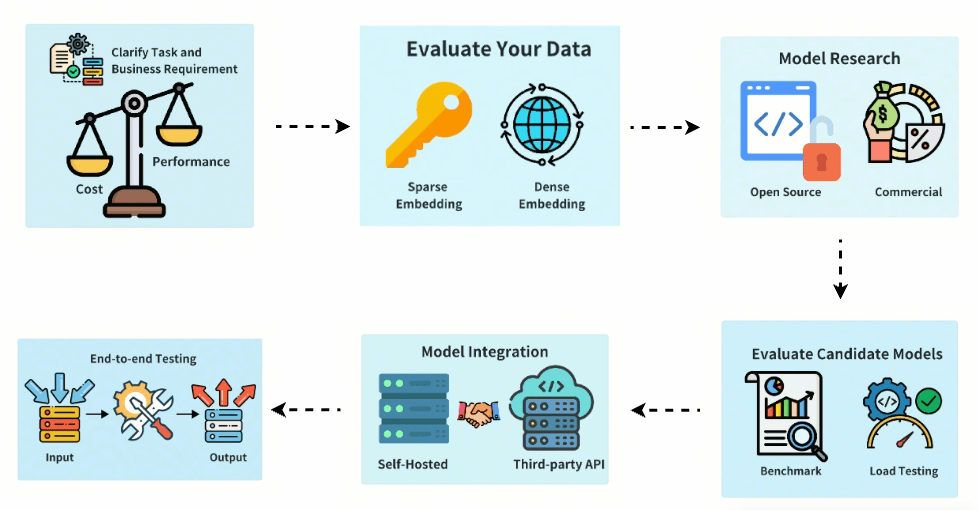
1. Define Your Task and Business Requirements
Before choosing an embedding model, start by clarifying your core objectives:
- Task Type: Start by identifying the core application you’re building—semantic search, a recommender system, a classification pipeline, or something else entirely. Each use case has different requirements for how embeddings should represent and organize information. For example, if you are building a semantic search engine, you need models like Sentence-BERT that capture nuanced semantic meaning between queries and documents, ensuring that similar concepts are close in vector space. For classification tasks, embeddings must reflect category-specific structure, so that inputs from the same class are placed close together in the vector space. This makes it easier for downstream classifiers to distinguish between classes. Models like DistilBERT, and RoBERTa are commonly used. In recommender systems, the goal is to find embeddings that reflect user-item relationships or preferences. For this, you might use models that are specifically trained on implicit feedback data like Neural Collaborative Filtering (NCF).
- ROI Assessment: Balance performance against costs based on your specific business context. Mission-critical applications (like healthcare diagnostics) may justify premium models with higher accuracy since it could be a matter of like and death, while cost-sensitive applications with high volume need careful cost-benefit analysis. The key is determining whether a mere 2-3% performance improvement justifies potentially significant cost increases in your particular scenario.
- Other Constraints: Consider your technical requirements when narrowing down options. If you need multilingual support, many general models struggle with non-English content, so specialized multilingual models may be necessary. If you’re working in specialized domains (medical/legal), general-purpose embeddings often miss domain-specific jargon—for example, they might not understand that “stat” in a medical context means “immediately”, or that “consideration” in legal documents refers to something of value exchanged in a contract. Similarly, hardware limitations and latency requirements will directly impact which models are feasible for your deployment environment.
2. Evaluate Your Data
The nature of your data significantly influences the choice of embedding model. Key considerations include:
- Data Modality: Is your data textual, visual, or multimodal in nature? Match your model to your data type. Use transformer-based models like BERT or Sentence-BERT for text, CNN architectures or Vision Transformers (ViT) for images, specialized models for audio, and multimodal models like CLIP and MagicLens for multimodal applications.
- Domain Specificity: Consider whether general models are sufficient, or if you need domain-specific models that understand specialized knowledge. General models trained on diverse datasets (like OpenAI text embedding models) work well for common topics but often miss subtle distinctions in specialized fields. However, in fields like healthcare or legal services, they often miss subtle distinctions—so domain-specific embeddings like BioBERT or LegalBERT may be more suitable.
- Embedding Type: Sparse embeddings excel at keyword matching, making them ideal for product catalogs or technical documentation. Dense embeddings capture semantic relationships better, making them suitable for natural language queries and intent understanding. Many production systems like e-commerce recommender systems benefit from a hybrid approach that leverages both types—for example, using BM25 (sparse) for keyword matching while adding BERT (dense embeddings) to capture semantic similarity.
3. Research Available Models
After understanding your task and data, it’s time to research available embedding models. Here’s how you can approach this:
Popularity: Prioritize models with active communities and widespread adoption. These models usually benefit from better documentation, broader community support, and regular updates. This can significantly reduce implementation difficulties. Familiarize yourself with leading models in your domain. For example:
- For Text: consider OpenAI embeddings, Sentence-BERT variants, or E5/BGE models.
- For image: look at ViT and ResNet, or CLIP and SigLIP for text-image alignment.
- For Audio: check PNNs, CLAP or other popular models.
Copyright and Licensing: Carefully evaluate the licensing implications as they directly affect both short and long-term costs. Open-source models (like MIT, Apache 2.0, or similar licenses) provide flexibility for modification and commercial use, giving you full control over deployment but requiring infrastructure expertise. Proprietary models accessed via APIs offer convenience and simplicity but come with ongoing costs and potential data privacy concerns. This decision is especially critical for applications in regulated industries where data sovereignty or compliance requirements may make self-hosting necessary despite the higher initial investment.
4. Evaluate Candidate Models
Once you’ve shortlisted a few models, it’s time to test them with your sample data. Here are key factors you should consider:
- Evaluation: When evaluating embedding quality—especially in retrieval augmented generation (RAG) or search application—it’s important to measure how accurate, relevant, and complete the returned results are. Key metrics include faithfulness, answer relevancy, context precision, and recall. Frameworks like Ragas, DeepEval, Phoenix, and TruLens-Eval streamline this evaluation process by providing structured methodologies for assessing different aspects of embedding quality. Datasets are equally important for meaningful evaluation. They can be hand-crafted to represent real use cases, synthetically generated by LLMs to test specific capabilities, or created using tools like Ragas and FiddleCube to target particular testing aspects. The right combination of dataset and framework depends on your specific application and the level of evaluation granularity you need to make confident decisions.
- Benchmark Performance: Evaluate models on task-specific benchmarks (e.g., MTEB for retrieval). Remember that rankings vary significantly by scenario (search vs. classification), datasets (general vs. domain-specific like BioASQ), and metrics (accuracy, speed). While benchmark performance provide valuable insights, it doesn’t always translate perfectly to real-world applications. Cross-check top performers that align with your data type and goals, but always validate with your own custom test cases to identify models that might overfit to benchmarks but underperform in real-world conditions with your specific data patterns.
- Load Testing: For self-hosted models, simulate realistic production loads to evaluate performance under real-world conditions. Measure throughput as well as GPU utilization and memory consumption during inference to identify potential bottlenecks. A model that performs well in isolation may become problematic when handling concurrent requests or complex inputs. If the model is too resource-intensive, it may not be suitable for large-scale or real-time applications regardless of its accuracy on benchmark metrics.
5. Model Integration
After selecting a model, now it is time to plan your integration approach.
- Weights Selection: Decide between using pre-trained weights for quick deployment or fine-tuning on domain-specific data for improved performance. Remember fine-tuning can improve performance but is resource heavy. Consider whether performance gains justify the additional complexity.
- Self-Hosting vs. Third-party Inference Service: Choose your deployment approach based on your infrastructure capabilities and requirements. Self-hosting gives you complete control over the model and data flow, potentially reducing per-request costs at scale and ensuring data privacy. However, it requires infrastructure expertise and ongoing maintenance. Third-party inference services offer rapid deployment with minimal setup but introduce network latency, potential usage caps, and continuous costs that can become significant at scale.
- Integration Design: Plan your API design, caching strategies, batch processing approach, and vector database selection for storing and querying embeddings efficiently.
6. End-to-End Testing
Before full deployment, run end-to-end tests to ensure the model works as expected:
- Performance: Always evaluate the model on your own dataset to ensure they perform well in your specific use case. Consider metrics like MRR, MAP and NDCG for retrieval quality, precision, recall and F1 for accuracy, and throughput and latency percentiles for operational performance.
- Robustness: Test the model under different conditions, including edge cases and diverse data inputs, to verify that it performs consistently and accurately.
Summary
As we’ve seen throughout this guide, selecting the right embedding model requires following these six critical steps:
- Define your business requirements and task type
- Analyze your data characteristics and domain specificity
- Research available models and their licensing terms
- Rigorously evaluate candidates against relevant benchmarks and test datasets
- Plan your integration approach considering deployment options
- Conduct comprehensive end-to-end testing before production deployment
By following this framework, you can make an informed decision that balances performance, cost, and technical constraints for your specific use case. Remember that the “best” model isn’t necessarily the one with the highest benchmark scores—it’s the one that best meets your particular requirements within your operational constraints.
With embedding models evolving rapidly, it’s also worth periodically reassessing your choice as new options emerge that might offer significant improvements for your application.
- 1. Define Your Task and Business Requirements
- 2. Evaluate Your Data
- 3. Research Available Models
- 4. Evaluate Candidate Models
- 5. Model Integration
- 6. End-to-End Testing
- Summary
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



