When Context Engineering Is Done Right, Hallucinations Can Be the Spark of AI Creativity
For a long time, many of us — myself included — treated LLM hallucinations as nothing more than defects. An entire toolchain has been built around eliminating them: retrieval systems, guardrails, fine-tuning, and more. These safeguards are still valuable. But the more I’ve studied how models actually generate responses — and how systems like Milvus fit into broader AI pipelines — the less I believe hallucinations are simply failures. In fact, they can also be the spark of AI creativity.
If we look at human creativity, we find the same pattern. Every breakthrough relies on imaginative leaps. But those leaps never come out of nowhere. Poets first master rhythm and meter before they break the rules. Scientists rely on established theories before venturing into untested territory. Progress depends on these leaps, as long as they are grounded in solid knowledge and understanding.
LLMs operate in much the same way. Their so-called “hallucinations” or “leaps”— analogies, associations, and extrapolations — emerge from the same generative process that allows models to make connections, extend knowledge, and surface ideas beyond what they’ve been explicitly trained on. Not every leap succeeds, but when it does, the results can be compelling.
That’s why I see Context Engineering as the critical next step. Rather than trying to eliminate every hallucination, we should focus on steering them. By designing the right context, we can strike a balance — keeping models imaginative enough to explore new ground, while ensuring they remain anchored enough to be trusted.
What is Context Engineering?
So what exactly do we mean by context engineering? The term may be new, but the practice has been evolving for years. Techniques such as RAG, prompting, function calling, and MCP are all early attempts at solving the same problem: providing models with the right environment to produce useful results. Context engineering is about unifying those approaches into a coherent framework.
The Three Pillars of Context Engineering
Effective context engineering rests on three interconnected layers:
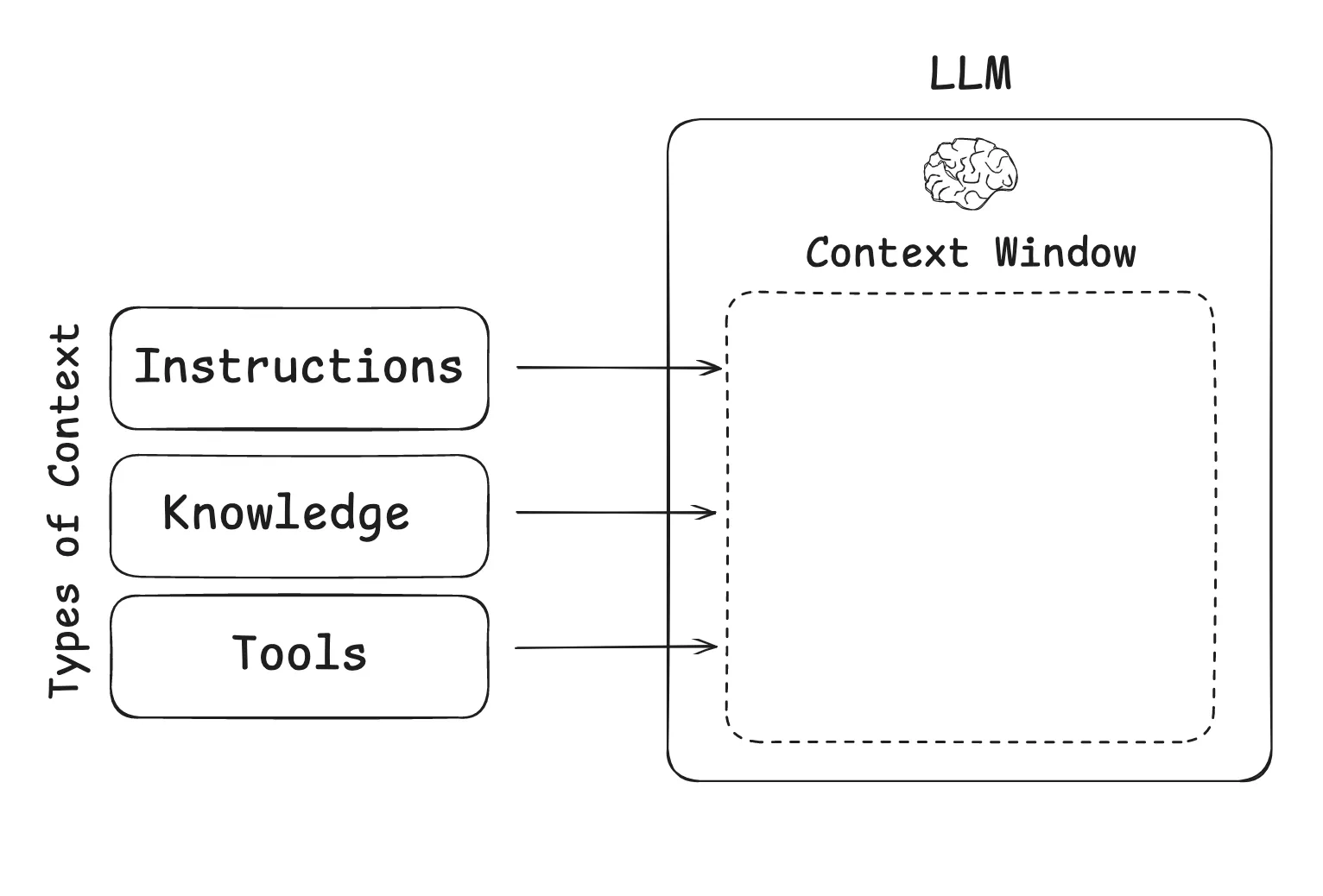
1. The Instructions Layer — Defining Direction
This layer includes prompts, few-shot examples, and demonstrations. It’s the model’s navigation system: not just a vague “go north,” but a clear route with waypoints. Well-structured instructions set boundaries, define goals, and reduce ambiguity in model behavior.
2. The Knowledge Layer — Supplying Ground Truth
Here we place the facts, code, documents, and state that the model needs to reason effectively. Without this layer, the system improvises from incomplete memory. With it, the model can ground its outputs in domain-specific data. The more accurate and relevant the knowledge, the more reliable the reasoning.
3. The Tools Layer — Enabling Action and Feedback
This layer covers APIs, function calls, and external integrations. It’s what enables the system to move beyond reasoning to execution—retrieving data, performing calculations, or triggering workflows. Just as importantly, these tools provide real-time feedback that can be looped back into the model’s reasoning. That feedback is what enables correction, adaptation, and continuous improvement. In practice, this is what transforms LLMs from passive responders into active participants in a system.
These layers aren’t silos—they reinforce each other. Instructions set the destination, knowledge provides the information to work with, and tools turn decisions into action and feed results back into the loop. Orchestrated well, they create an environment where models can be both creative and dependable.
The Long Context Challenges: When More Becomes Less
Many AI models now advertise million-token windows—enough for ~75,000 lines of code or a 750,000-word document. But more context doesn’t automatically yield better results. In practice, very long contexts introduce distinct failure modes that can degrade reasoning and reliability.
Context Poisoning — When Bad Information Spreads
Once false information enters the working context—whether in goals, summaries, or intermediate state—it can derail the entire reasoning process. DeepMind’s Gemini 2.5 report provides a clear example. An LLM agent playing Pokémon misread the game state and decided its mission was to “catch the uncatchable legendary.” That incorrect goal was recorded as fact, leading the agent to generate elaborate but impossible strategies.
As shown in the excerpt below, the poisoned context trapped the model in a loop—repeating errors, ignoring common sense, and reinforcing the same mistake until the entire reasoning process collapsed.

Figure 1: Excerpt from Gemini 2.5 Tech Paper
Context Distraction — Lost in the Details
As context windows expand, models can start to overweight the transcript and underuse what they learned during training. DeepMind’s Gemini 2.5 Pro, for example, supports a million-token window but begins to drift around ~100,000 tokens—recycling past actions instead of generating new strategies. Databricks’ research shows that smaller models, like Llama 3.1-405B, reach that limit far sooner at roughly ~32,000 tokens. It’s a familiar human effect: too much background reading, and you lose the plot.

Figure 2: Excerpt from Gemini 2.5 Tech Paper
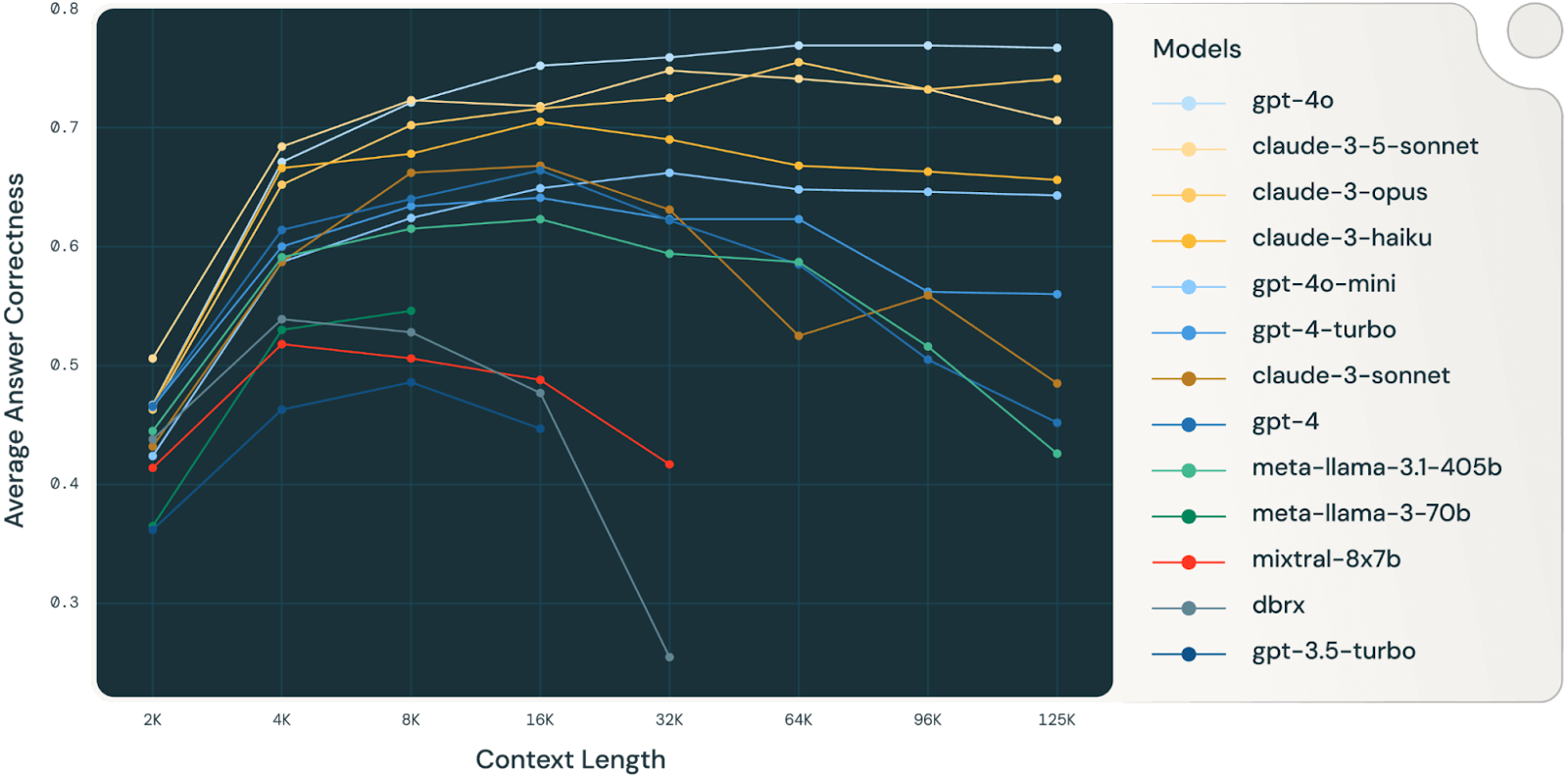
Figure 3: Long context performance of GPT, Claude, Llama, Mistral and DBRX models on 4 curated RAG datasets (Databricks DocsQA, FinanceBench, HotPotQA and Natural Questions) [Source: Databricks]
Context Confusion — Too Many Tools in the Kitchen
Adding more tools doesn’t always help. The Berkeley Function-Calling Leaderboard shows that when the context displays extensive tool menus—often with many irrelevant options—model reliability decreases, and tools are invoked even when none are needed. One clear example: a quantized Llama 3.1-8B failed with 46 tools available, but succeeded when the set was reduced to 19. It’s the paradox of choice for AI systems—too many options, worse decisions.
Context Clash — When Information Conflicts
Multi-turn interactions add a distinct failure mode: early misunderstandings compound as the dialogue branches. In Microsoft and Salesforce experiments, both open- and closed-weight LLMs performed markedly worse in multi-turn vs. single-turn settings—an average 39% drop across six generation tasks. Once a wrong assumption enters the conversation state, subsequent turns inherit it and amplify the error.
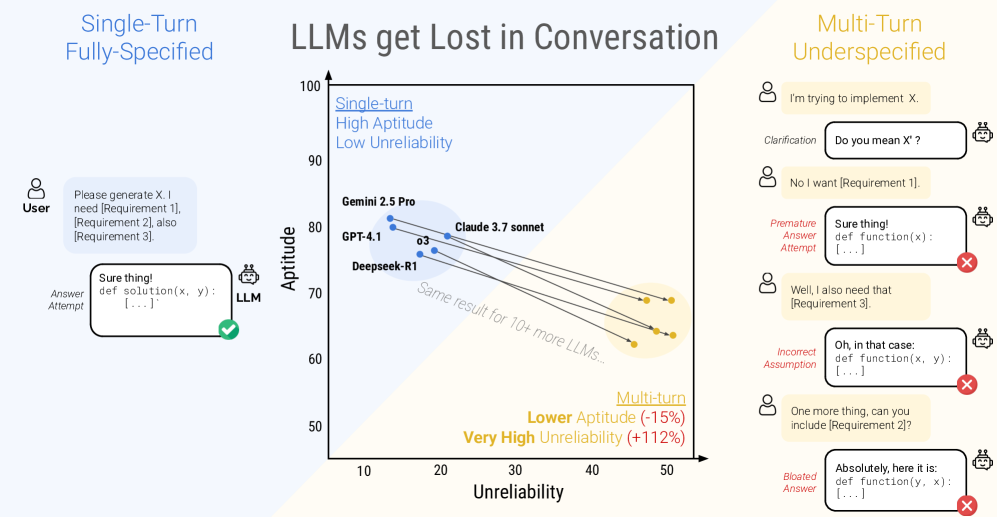
Figure 4: LLMs get lost in multi-turn conversations in experiments
The effect shows up even in frontier models. When benchmark tasks were distributed across turns, the performance score of OpenAI’s o3 model fell from 98.1 to 64.1. An initial misread effectively “sets” the world model; each reply builds on it, turning a small contradiction into a hardened blind spot unless explicitly corrected.
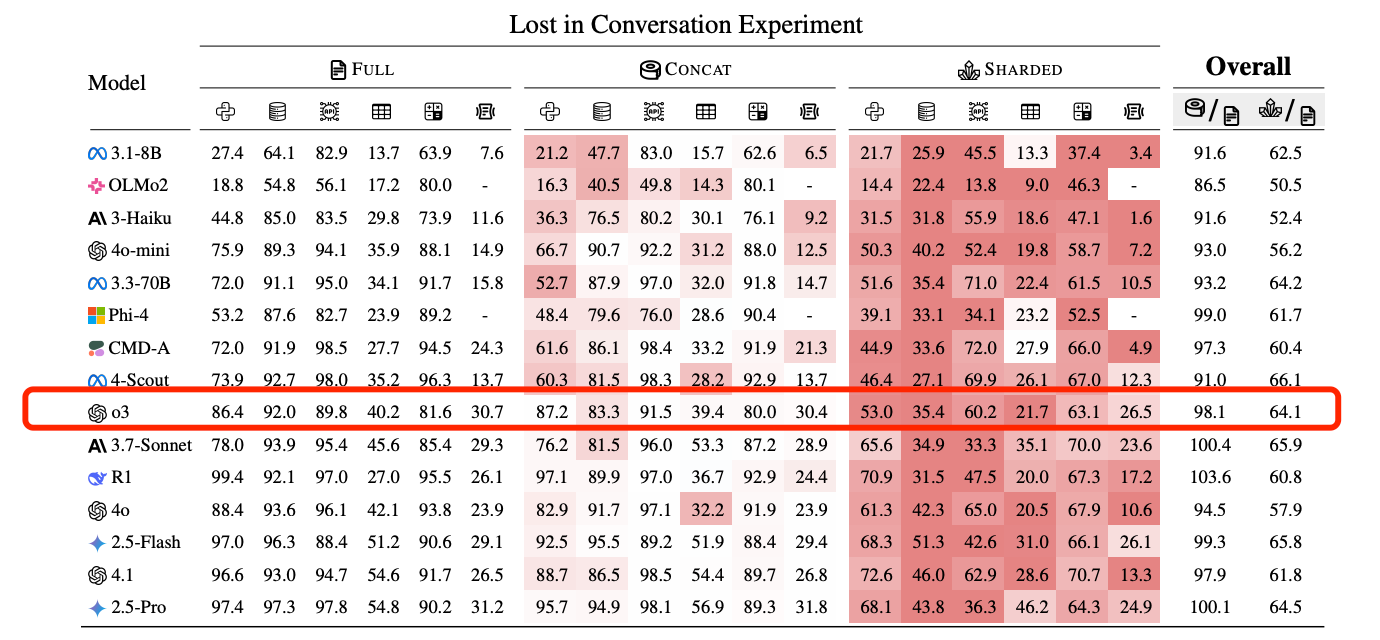
Figure 4: The performance scores in LLM multi-turn conversation experiments
Six Strategies to Tame Long Context
The answer to long-context challenges isn’t to abandon the capability—it’s to engineer it with discipline. Here are six strategies we’ve seen work in practice:
Context Isolation
Break complex workflows into specialized agents with isolated contexts. Each agent focuses on its own domain without interference, reducing the risk of error propagation. This not only improves accuracy but also enables parallel execution, much like a well-structured engineering team.
Context Pruning
Regularly audit and trim the context. Remove redundant details, stale information, and irrelevant traces. Think of it as refactoring: clean out dead code and dependencies, leaving only the essentials. Effective pruning requires explicit criteria for what belongs and what doesn’t.
Context Summarization
Long histories don’t need to be carried around in full. Instead, condense them into concise summaries that capture only what is essential for the next step. Good summarization retains the critical facts, decisions, and constraints, while eliminating repetition and unnecessary details. It’s like replacing a 200-page spec with a one-page design brief that still gives you everything you need to move forward.
Context Offloading
Not every detail needs to be part of the live context. Persist non-critical data in external systems—knowledge bases, document stores, or vector databases like Milvus—and fetch it only when needed. This lightens the model’s cognitive load while keeping background information accessible.
Strategic RAG
Information retrieval is powerful only if it’s selective. Introduce external knowledge through rigorous filtering and quality controls, ensuring the model consumes relevant and accurate inputs. As with any data pipeline: garbage in, garbage out—but with high-quality retrieval, the context becomes an asset, not a liability.
Optimized Tool Loading
More tools don’t equal better performance. Studies show reliability drops sharply beyond ~30 available tools. Load only the functions a given task requires, and gate access to the rest. A lean toolbox fosters precision and reduces the noise that can overwhelm decision-making.
The Infrastructure Challenge of Context Engineering
Context engineering is only as effective as the infrastructure it runs on. And today’s enterprises are hitting a perfect storm of data challenges:
Scale Explosion — From Terabytes to Petabytes
Today, data growth has redefined the baseline. Workloads that once fit comfortably in a single database now span petabytes, demanding distributed storage and compute. A schema change that used to be a one-line SQL update can cascade into a full orchestration effort across clusters, pipelines, and services. Scaling isn’t simply about adding hardware—it’s about engineering for coordination, resilience, and elasticity at a scale where every assumption gets stress-tested.
Consumption Revolution — Systems That Speak AI
AI agents don’t just query data; they generate, transform, and consume it continuously at machine speeds. Infrastructure designed just for human-facing applications can’t keep up. To support agents, systems must provide low-latency retrieval, streaming updates, and write-heavy workloads without breaking. In other words, the infrastructure stack must be built to “speak AI” as its native workload, not as an afterthought.
Multimodal Complexity — Many Data Types, One System
AI workloads blend text, images, audio, video, and high-dimensional embeddings, each with rich metadata attached. Managing this heterogeneity is the crux of practical context engineering. The challenge isn’t just storing diverse objects; it’s indexing them, retrieving them efficiently, and keeping semantic consistency across modalities. A truly AI-ready infrastructure must treat multimodality as a first-class design principle, not a bolt-on feature.
Milvus + Loon: Purpose-Built Data Infrastructure for AI
The challenges of scale, consumption, and multimodality can’t be solved with theory alone—they demand infrastructure that is purpose-built for AI. That’s why we at Zilliz designed Milvus and Loon to work together, addressing both sides of the problem: high-performance retrieval at runtime and large-scale data processing upstream.
Milvus: the most widely adopted open-source vector database optimized for high-performance vector retrieval and storage.
Loon: our upcoming cloud-native multimodal data lake service designed to process and organize massive-scale multimodal data before it ever reaches the database. Stay tuned.
Lightning-Fast Vector Search
Milvus is built from the ground up for vector workloads. As the serving layer, it delivers sub-10ms retrieval across hundreds of millions—or even billions—of vectors, whether derived from text, images, audio, or video. For AI applications, retrieval speed isn’t a “nice to have.” It’s what determines whether an agent feels responsive or sluggish, whether a search result feels relevant or out of step. Performance here is directly visible in the end-user experience.
Multimodal Data Lake Service at Scale
Loon is our upcoming multimodal data lake service, designed for massive-scale offline processing and analytics of unstructured data. It complements Milvus on the pipeline side, preparing data before it ever reaches the database. Real-world multimodal datasets—spanning text, images, audio, and video—are often messy, with duplication, noise, and inconsistent formats. Loon takes care of this heavy lifting using distributed frameworks like Ray and Daft, compressing, deduplicating, and clustering the data before streaming it directly into Milvus. The result is simple: no staging bottlenecks, no painful format conversions—just clean, structured data that models can use immediately.
Cloud-Native Elasticity
Both systems are built cloud-native, with storage and compute scaling independently. That means as workloads grow from gigabytes to petabytes, you can balance resources between real-time serving and offline training, rather than overprovisioning for one or undercutting the other.
Future-Proof Architecture
Most importantly, this architecture is designed to grow with you. Context engineering is still evolving. Right now, most teams are focused on semantic search and RAG pipelines. But the next wave will demand more—integrating multiple data types, reasoning across them, and powering agent-driven workflows.
With Milvus and Loon, that transition doesn’t require ripping out your foundation. The same stack that supports today’s use cases can extend naturally into tomorrow’s. You add new capabilities without starting over, which means less risk, lower cost, and a smoother path as AI workloads become more complex.
Your Next Move
Context engineering isn’t just another technical discipline—it’s how we unlock AI’s creative potential while keeping it grounded and reliable. If you’re ready to put these ideas into practice, start where it matters most.
Experiment with Milvus to see how vector databases can anchor retrieval in real-world deployments.
Follow Milvus for updates on Loon’s release and insights into managing large-scale multimodal data.
Join the Zilliz community on Discord to share strategies, compare architectures, and help shape best practices.
The companies that master context engineering today will shape the AI landscape tomorrow. Don’t let infrastructure be the constraint—build the foundation your AI creativity deserves.
- What is Context Engineering?
- The Three Pillars of Context Engineering
- 1\. The Instructions Layer — Defining Direction
- 2\. The Knowledge Layer — Supplying Ground Truth
- 3\. The Tools Layer — Enabling Action and Feedback
- The Long Context Challenges: When More Becomes Less
- Context Poisoning — When Bad Information Spreads
- Context Distraction — Lost in the Details
- Context Confusion — Too Many Tools in the Kitchen
- Context Clash — When Information Conflicts
- Six Strategies to Tame Long Context
- Context Isolation
- Context Pruning
- Context Summarization
- Context Offloading
- Strategic RAG
- Optimized Tool Loading
- The Infrastructure Challenge of Context Engineering
- Scale Explosion — From Terabytes to Petabytes
- Consumption Revolution — Systems That Speak AI
- Multimodal Complexity — Many Data Types, One System
- Milvus + Loon: Purpose-Built Data Infrastructure for AI
- Lightning-Fast Vector Search
- Multimodal Data Lake Service at Scale
- Cloud-Native Elasticity
- Future-Proof Architecture
- Your Next Move
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



