Crear una colección externaCompatible with Milvus 3.0.x
Una colección externa es un tipo de colección de datos en Milvus que accede a datos de sistemas de almacenamiento externos o tablas de bases de datos como AWS S3 e Iceberg sin copiarlos en Milvus. Actúa como una capa de consulta sobre los lagos de datos mientras mantiene la compatibilidad con las interfaces de consulta de Milvus.
Visión general
En una canalización de datos de IA típica, es posible que los usuarios ya hayan almacenado sus datos en Parquet u otros formatos en su sistema de almacenamiento, como AWS S3. Para hacer que Milvus consuma estos datos almacenados externamente, los usuarios normalmente necesitan importarlos al propio almacenamiento de Milvus utilizando canalizaciones Extract-Transform-Load (ETL).
Este flujo de trabajo de traer los datos a Milvus crea datos redundantes que son difíciles de sincronizar y aumenta la carga de mantenimiento de ingeniería para garantizar la coherencia de los datos.
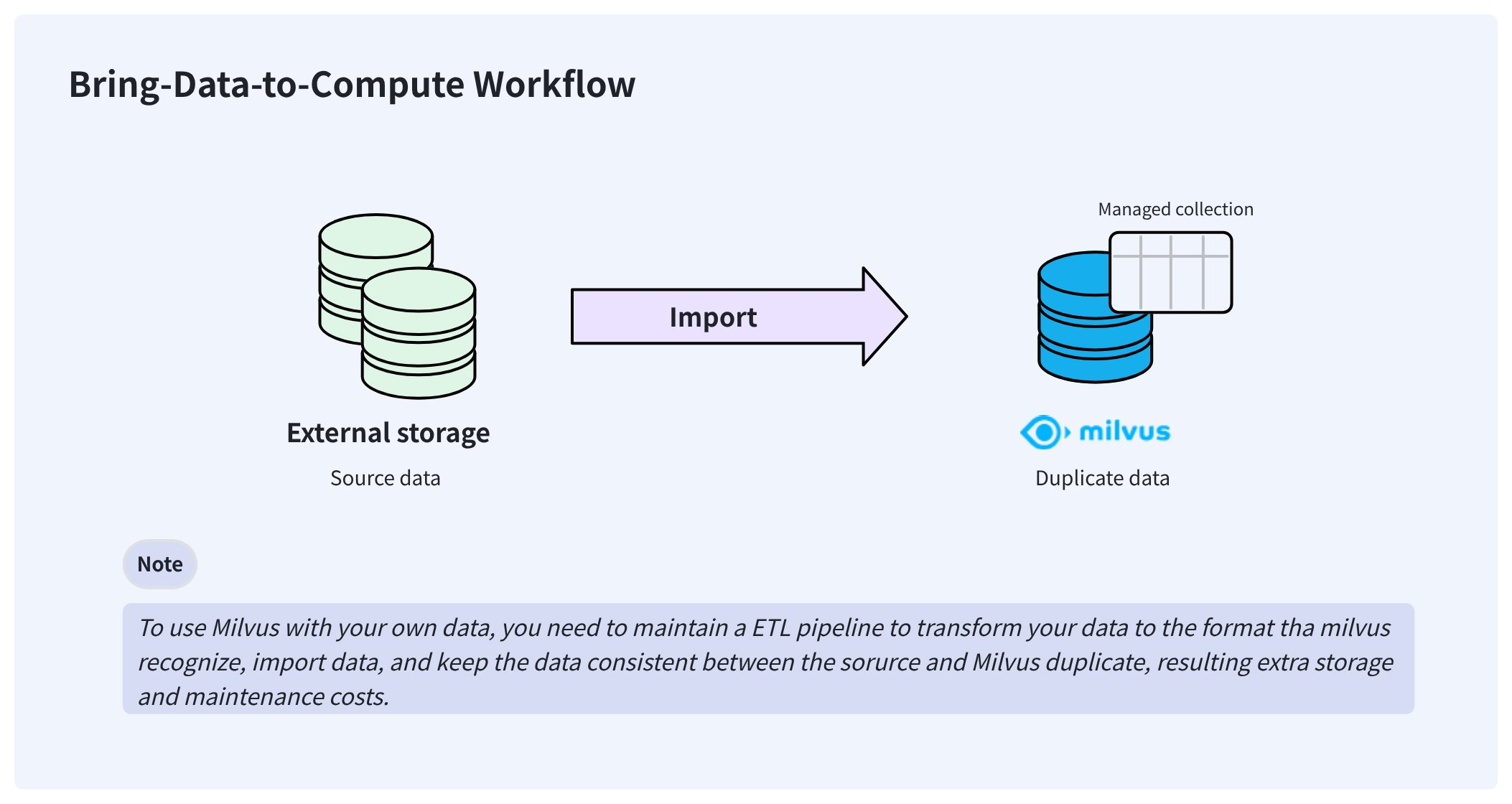 Flujo de trabajo de llevar los datos a la computación
Flujo de trabajo de llevar los datos a la computación
Para resolver estos problemas, Milvus ofrece colecciones externas que le permiten acceder a sus datos almacenados externamente desde Milvus sin tener que preocuparse por la sincronización de datos y las canalizaciones ETL.
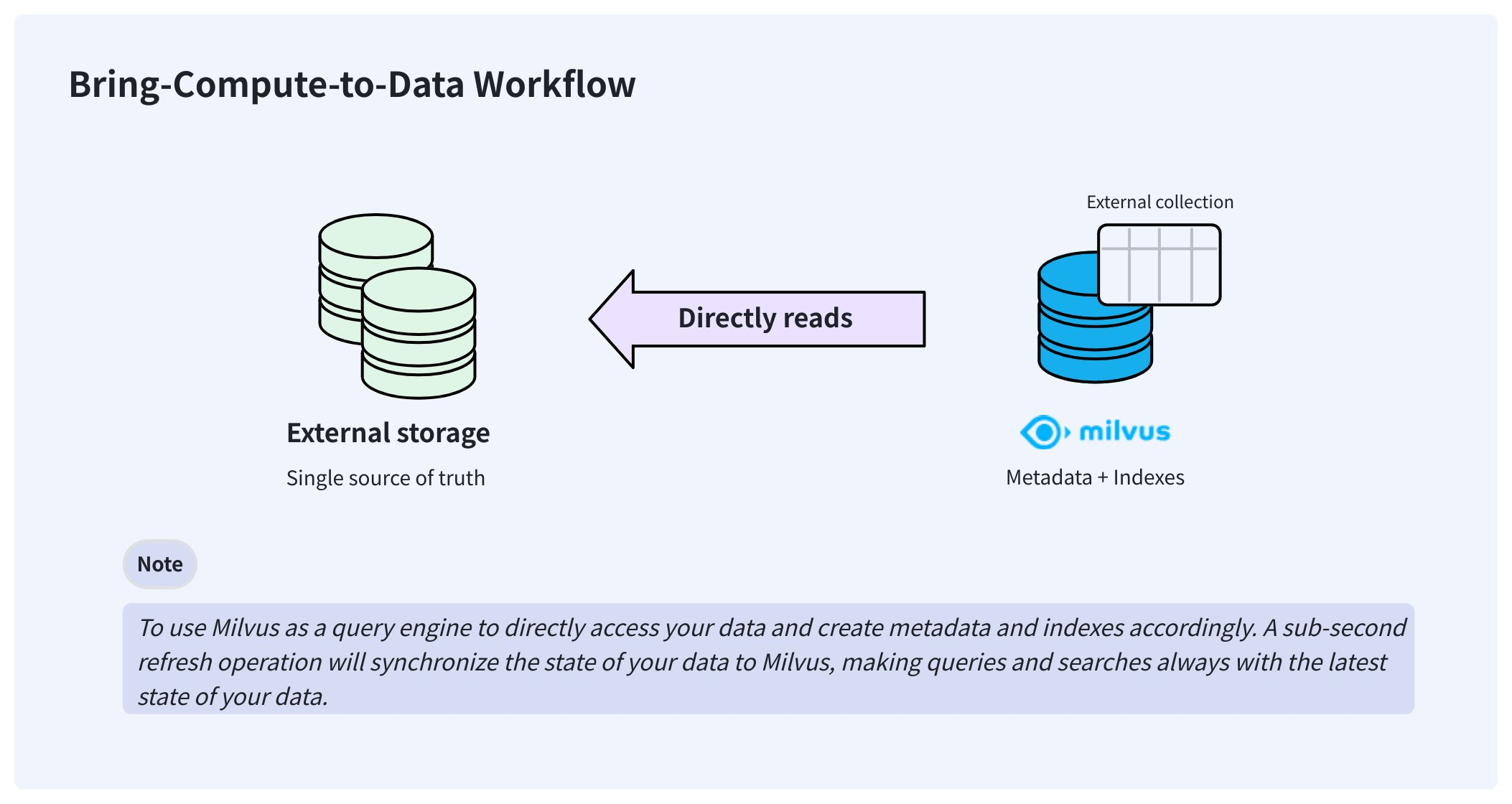 Llevar la computación al flujo de trabajo de datos
Llevar la computación al flujo de trabajo de datos
Una vez creada, una colección externa puede acceder directamente a sus datos y mantenerlos en el mismo lugar donde los almacena. En segundo plano, Milvus crea archivos de manifiesto para registrar las correspondencias entre los metadatos de Milvus y las filas de los archivos de datos externos. Una vez que los archivos de manifiesto están listos, puede crear índices en la colección externa como lo haría en cualquier colección gestionada.
Cuando sus datos cambien, la activación manual de una actualización en menos de un segundo actualizará los metadatos, manteniendo Milvus siempre al día.
Paso 1: Crear esquema
Al igual que al crear una colección gestionada, también es necesario crear un esquema antes de crear una colección externa. Sin embargo, el esquema es ligeramente diferente al de una colección gestionada.
from pymilvus import MilvusClient, DataType
schema = MilvusClient.create_schema(
external_source='s3://s3.<region-id>.amazonaws.com/<bucket>/',
external_spec='{
"format": "parquet",
"extfs": {
...
}
}'
)
import com.google.gson.JsonObject;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
JsonObject externalSpec = new JsonObject();
externalSpec.addProperty("format", "parquet");
externalSpec.add("extfs", new JsonObject());
CreateCollectionReq.CollectionSchema schema = CreateCollectionReq.CollectionSchema.builder()
.externalSource("s3://s3.<region-id>.amazonaws.com/<bucket>/")
.externalSpec(externalSpec)
.build();
import (
"github.com/milvus-io/milvus/client/v2/entity"
client "github.com/milvus-io/milvus/client/v2/milvusclient"
)
schema := entity.NewSchema().
WithName("product_embeddings").
WithExternalSource("s3://my-bucket/embeddings/").
WithExternalSpec(`{"format": "parquet", "extfs": { ... }}`)
// node
export fields='[
{
"fieldName": "product_id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "embedding",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "768"
}
},
{
"fieldName": "product_name",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 512
}
}
]'
Para crear el esquema de una colección externa, debe especificar el URI de los datos de origen, el formato de los datos y la configuración de autenticación.
Nombre del parámetro |
Descripción del parámetro |
Ejemplo Valor |
|---|---|---|
|
Formato de los archivos de datos de origen de destino. |
|
|
Un ID de instantánea de tabla Iceberg válido. Este parámetro sólo se aplica cuando se establece |
|
|
Configuración del sistema de archivos externo en una estructura JSON stringificada. |
-- |
Dispone de las siguientes opciones para establecer la configuración de autenticación:
Usar AWS AK/SK
Esta opción se aplica a MinIO autoalojado o al escenario en el que tiene AK/SK para trabajar.
{
"format": "...",
"extfs": {
"access_key_id": "AKIA..",
"access_key_value": "u4Lh...",
"region": "us-west-2",
"cloud_provider": "aws",
"use_ssl": "true",
"use_virtual_host": "true"
}
}
Nombre del parámetro |
Parámetro Descripción |
Ejemplo Valor |
|---|---|---|
|
ID de la clave de acceso |
|
|
Valor de la clave de acceso |
|
|
ID de región de la nube |
|
|
ID del proveedor de la nube |
|
|
Si se utiliza SSL para establecer conexiones. |
|
|
Si se utiliza alojamiento virtual para acceder a su bucket. Para obtener más información, consulte este artículo. |
|
Utilizar AWS IAM
Esta opción se aplica al escenario en el que Milvus se ejecuta en una instancia EC2 o en un clúster EKS. En este caso, no necesita codificar el AK/SK.
{
"format": "...",
"extfs": {
"use_iam": "true",
"iam_endpoint": "https://sts.<region>.amazonaws.com",
"region": "us-west-2",
"cloud_provider": "aws",
"use_ssl": "true"
}
}
Nombre del parámetro |
Descripción del parámetro |
Ejemplo Valor |
|---|---|---|
|
Si utilizar AWS IAM. Establézcalo en |
|
|
Un endpoint AWS STS válido. Para obtener más información, consulte este artículo. |
|
|
ID de región de nube |
|
|
ID del proveedor de la nube |
|
|
Si se utiliza SSL para establecer conexiones. |
|
Usar credenciales globales de Milvus
Esta opción se aplica cuando almacena datos externos en el cubo de Milvus, y la configuración global de MinIO especificada en milvus.yaml puede utilizarse directamente para acceder a los datos.
{
"format": "...",
"extfs": {
"storage_type": "remote"
}
}
Utilizar ARN de rol de IAM
Esta opción se aplica cuando su organización utiliza diferentes cuentas de AWS para administrar el clúster Milvus y el cubo que contiene los archivos de datos de destino.
En este caso, el propietario del cubo debe crear un rol IAM que
Adjunte
AmazonS3FullAccesso una política más detallada para el acceso al cubo.Incluye un
sts:ExternalIdautodefinido en el campo Condición de la Política de confianza del rol.
A continuación, el propietario del cubo debe proporcionarle el ARN del rol IAM y el ID externo para que pueda llamar a sts:AssumeRole con esos valores para asumir el rol IAM.
El siguiente es un ejemplo de política de permisos que se adjuntará al rol IAM con los permisos permitidos. Usted puede ajustar esto para satisfacer sus necesidades.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": "arn:aws:s3:::SOURCE-DATA-BUCKET"
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": "arn:aws:s3:::SOURCE-DATA-BUCKET/*"
}
]
}
Y la política de confianza asociada al rol IAM define quién está autorizado a asumirlo.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::ACCOUNT_RUNNING_MILVUS:root"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": "YOUR_UNIQUE_EXTERNAL_ID"
}
}
}
]
}
Una vez que haya obtenido el ARN del rol IAM y el ID externo, puede configurar el parámetro external_spec de la siguiente manera:
{
"format": "...",
"extfs": {
"cloud_provider": "aws",
"region": "us-west-2",
"storage_type": "remote",
"use_ssl": "true",
"use_iam": "true",
"role_arn": "arn:aws:iam::306787000000:role/lentitude-bucket-role",
"external_id": "YOUR_UNIQUE_EXTERNAL_ID",
"load_frequency": "900"
}
}
Nombre del parámetro |
Descripción del parámetro |
Ejemplo Valor |
|---|---|---|
|
ID del proveedor de la nube |
|
|
ID de región de nube |
|
|
Si se utiliza SSL para establecer conexiones. |
|
|
Si se utiliza AWS IAM. Establezca esta opción en |
|
|
ARN de rol de IAM obtenido del propietario del bucket. |
|
|
ID externo obtenido del propietario del bucket. |
-- |
|
Intervalo en el que Milvus recupera credenciales de autenticación temporales en segundos. |
|
Paso 2: Añadir campos
Una vez que el esquema está listo, puede añadir campos de la siguiente manera:
schema.add_field(
field_name="product_id",
datatype=DataType.INT64,
# highlight-next
external_field="id" # field name in the external data file
)
schema.add_field(
field_name="product_name",
datatype=DataType.VARCHAR,
max_length=512,
# highlight-next
external_field="name"
)
schema.add_field(
field_name="embedding",
datatype=DataType.FLOAT_VECTOR,
dim=768,
# highlight-next
external_field="vector"
)
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
schema.addField(AddFieldReq.builder()
.fieldName("product_id")
.dataType(DataType.Int64)
.externalField("id")
.build());
schema.addField(AddFieldReq.builder()
.fieldName("product_name")
.dataType(DataType.VarChar)
.maxLength(512)
.externalField("name")
.build());
schema.addField(AddFieldReq.builder()
.fieldName("embedding")
.dataType(DataType.FloatVector)
.dimension(768)
.externalField("vector")
.build());
import (
"github.com/milvus-io/milvus/client/v2/entity"
client "github.com/milvus-io/milvus/client/v2/milvusclient"
)
schema = schema.
WithField(
entity.NewField().
WithName("product_id").
WithDataType(entity.FieldTypeInt64).
WithExternalField("id"),
).
WithField(
entity.NewField().
WithName("product_name").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(512).
WithExternalField("name"),
).
WithField(
entity.NewField().
WithName("embedding").
WithDataType(entity.FieldTypeFloatVector).
WithDim(768).
WithExternalField("vector"),
)
// node
export schema="{
\"externalSource\": \"volume://my_volume/path/to/a/folder\",
\"externalSpec\": \"{\\\"format\\\": \\\"parquet\\\"}\",
\"fields\": $fields
}"
Paso 3: Crear una colección
Después de añadir todos los campos al esquema, puedes crear la colección externa.
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
client.create_collection(
collection_name="test_collection",
schema=schema
)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
ConnectConfig connectConfig = ConnectConfig.builder()
.uri("http://localhost:19530")
.token("root:Milvus")
.build();
MilvusClientV2 client = new MilvusClientV2(connectConfig);
CreateCollectionReq createReq = CreateCollectionReq.builder()
.collectionName("test_collection")
.collectionSchema(schema)
.build();
client.createCollection(createReq);
import (
"github.com/milvus-io/milvus/client/v2/entity"
client "github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "http://localhost:19530"
token := "root:Milvus"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
APIKey: token
})
err = client.CreateCollection(ctx, milvusclient.NewCreateCollectionOption("test_collection", schema))
if err != nil {
fmt.Println(err.Error())
// handle error
}
// node
curl --request POST \
--url "${PROJECT_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d "{
\"dbName\": \"my_database\",
\"collectionName\": \"test_collection\",
\"schema\": $schema
}"
Paso 4: Crear índices
Puedes crear índices para las columnas de la colección externa como lo haces en las colecciones gestionadas.
index_params = client.prepare_index_params()
# Add indexes
index_params.add_index(
field_name="embedding",
index_type="AUTOINDEX",
metric_type="COSINE"
)
index_params.add_index(
field_name="product_name",
index_type="AUTOINDEX"
)
client.create_index(
db_name="my_database",
collection_name="test_collection",
index_params=index_params
)
import io.milvus.v2.common.IndexParam;
import io.milvus.v2.service.index.request.CreateIndexReq;
import java.util.*;
IndexParam indexParamForIdField = IndexParam.builder()
.fieldName("product_name")
.indexType(IndexParam.IndexType.AUTOINDEX)
.build();
IndexParam indexParamForVectorField = IndexParam.builder()
.fieldName("embedding")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.COSINE)
.build();
List<IndexParam> indexParams = new ArrayList<>();
indexParams.add(indexParamForIdField);
indexParams.add(indexParamForVectorField);
CreateIndexReq createIndexReq = CreateIndexReq.builder()
.dbName("my_database")
.collectionName("test_collection")
.indexParams(indexParams)
.build();
client.createIndex(createIndexReq);
import (
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
collectionName := "test_collection"
indexOptions := []milvusclient.CreateIndexOption{
milvusclient.NewCreateIndexOption(collectionName, "embedding", index.NewAutoIndex(entity.COSINE)),
milvusclient.NewCreateIndexOption(collectionName, "product_name", index.NewAutoIndex(index.AUTOINDEX)),
}
indexTask, err := client.CreateIndex(ctx, indexOptions)
if err != nil {
// handler err
}
err = indexTask.Await(ctx)
if err != nil {
// handler err
}
client.createIndex({
db_name: "my_database",
collection_name: "test_collection",
field_name: "product_name",
index_type: "AUTOINDEX"
})
client.createIndex({
db_name: "my_database",
collection_name: "test_collection",
field_name: "embedding",
index_type: "AUTOINDEX",
metric_type: "COSINE"
})
export indexParams='[
{
"fieldName": "embedding",
"indexName": "my_vector",
"indexType": "AUTOINDEX"
},
{
"fieldName": "product_name",
"indexName": "my_id",
"indexType": "AUTOINDEX"
}
]'
curl --request POST \
--url "${PROJECT_ENDPOINT}/v2/vectordb/indexes/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d "{
\"dbName\": \"my_database\",
\"collectionName\": \"test_collection\",
\"indexParams\": $indexParams
}"
Paso 5: Actualizar datos
Una vez que la colección esté lista, actualízala para crear los metadatos e índices para tus datos.
job_id = client.refresh_external_collection(
db_name="my_database",
collection_name="test_collection"
)
while True:
progress = client.get_refresh_external_collection_progress(job_id=job_id)
print(f" {progress.state}: {progress.progress}%")
if progress.state == "RefreshCompleted":
elapsed = progress.end_time - progress.start_time
print(f" Completed in {elapsed}ms")
break
elif progress.state == "RefreshFailed":
print(f" Failed: {progress.reason}")
break
time.sleep(2)
import io.milvus.v2.service.utility.request.GetRefreshExternalCollectionProgressReq;
import io.milvus.v2.service.utility.request.ListRefreshExternalCollectionJobsReq;
import io.milvus.v2.service.utility.request.RefreshExternalCollectionReq;
import io.milvus.v2.service.utility.response.GetRefreshExternalCollectionProgressResp;
import io.milvus.v2.service.utility.response.ListRefreshExternalCollectionJobsResp;
import io.milvus.v2.service.utility.response.RefreshExternalCollectionJobInfo;
import io.milvus.v2.service.utility.response.RefreshExternalCollectionResp;
while (true) {
GetRefreshExternalCollectionProgressResp resp = client.getRefreshExternalCollectionProgress(
GetRefreshExternalCollectionProgressReq.builder()
.jobId(jobId)
.build());
RefreshExternalCollectionJobInfo jobInfo = resp.getJobInfo();
if ("RefreshCompleted".equals(jobInfo.getState())) {
long elapsed = jobInfo.getEndTime() - jobInfo.getStartTime();
System.out.printf(" Refresh completed in %dms%n", elapsed);
break;
} else if ("RefreshFailed".equals(jobInfo.getState())) {
System.out.printf(" Refresh failed: %s%n", jobInfo.getReason());
}
TimeUnit.SECONDS.sleep(2);
}
refreshResult, err := client.RefreshExternalCollection(ctx,
client.NewRefreshExternalCollectionOption("test_collection"))
jobID := refreshResult.JobID
for {
progress, _ := client.GetRefreshExternalCollectionProgress(ctx,
client.NewGetRefreshExternalCollectionProgressOption(jobID))
fmt.Printf("State: %s\n", progress.State)
if progress.State == entity.RefreshStateCompleted {
fmt.Println("Refresh completed!")
break
}
if progress.State == entity.RefreshStateFailed {
fmt.Printf("Refresh failed: %s\n", progress.Reason)
break
}
time.Sleep(2 * time.Second)
}
// node
curl --request POST \
--url "${PROJECT_ENDPOINT}/v2/vectordb/jobs/external_collection/refresh" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d "{
\"dbName\": \"my_database\",
\"collectionName\": \"test_collection\",
\"externalSource\": \"volume://my_volume/path/to/a/folder\",
\"externalSpec\": \"{\\\"format\\\": \\\"parquet\\\"}\"
}"
La operación de actualización es asíncrona, por lo que es necesario configurar una iteración para supervisar su progreso.
La operación de actualización escanea los metadatos de los archivos de datos y genera los archivos de manifiesto en consecuencia. Suele tardar entre 150 y 250 ms.
Los archivos de manifiesto registran la correspondencia entre los metadatos de Milvus y las filas de los archivos externos.
Si se produce una actualización de los datos de origen, deberá volver a llamar manualmente a refrescar para mantener Milvus actualizado.
Una actualización que requiere la eliminación de todos los metadatos activos sin ninguna inserción da lugar a una denegación.
Seguimiento
Una vez que haya actualizado la colección externa, puede cargar y liberar la colección y realizar búsquedas y consultas de similitud en la colección externa como lo haría en cualquier colección gestionada, con la excepción de que las colecciones en una base de datos para computación bajo demanda deben adjuntarse a un clúster bajo demanda para búsquedas y consultas.
Antes de realizar operaciones DQL, como la búsqueda, la consulta, la obtención y la búsqueda híbrida, es necesario crear una sesión para adjuntar los recursos informáticos de un clúster bajo demanda.