Introducing Milvus SDK v2: Native Async Support, Unified APIs, and Superior Performance
TL;DR
You spoke, and we listened! Milvus SDK v2 is a complete reimagining of our developer experience, built directly from your feedback. With a unified API across Python, Java, Go, and Node.js, native async support that you’ve been asking for, a performance-boosting Schema Cache, and a simplified MilvusClient interface, Milvus SDK v2 makes vector search development faster and more intuitive than ever. Whether you’re building RAG applications, recommendation systems, or computer vision solutions, this community-driven update will transform how you work with Milvus.
Why We Built It: Addressing Community Pain Points
Over the years, Milvus has become the vector database of choice for thousands of AI applications. However, as our community grew, we consistently heard about several limitations with our SDK v1:
“Handling high concurrency is too complex.” The lack of native async support in some language SDKs forced developers to rely on threads or callbacks, making code harder to manage and debug, especially in scenarios like batch data loading and parallel queries.
“Performance degrades with scale.” Without a Schema Cache, v1 repeatedly validated schemas during operations, creating bottlenecks for high-volume workloads. In use cases requiring massive vector processing, this problem resulted in increased latency and reduced throughput.
“Inconsistent interfaces between languages create a steep learning curve.” Different language SDKs implemented interfaces in their own ways, complicating cross-language development.
“The RESTful API is missing essential features.” Critical functionalities like partition management and index construction were unavailable, forcing developers to switch between different SDKs.
These weren’t just feature requests — they were real obstacles in your development workflow. SDK v2 is our promise to remove these barriers and let you focus on what matters: building amazing AI applications.
The Solution: Milvus SDK v2
Milvus SDK v2 is the result of a complete redesign focused on developer experience, available across multiple languages:
1. Native Asynchronous Support: From Complex to Concurrent
The old way of handling concurrency involved cumbersome Future objects and callback patterns. SDK v2 introduces true async/await functionality, particularly in Python with AsyncMilvusClient (since v2.5.3). With the same parameters as the synchronous MilvusClient, you can easily run operations like insert, query, and search in parallel.
This simplified approach replaces the old cumbersome Future and callback patterns, leading to cleaner and more efficient code. Complex concurrent logic, like batch vector inserts or parallel multi-queries, can now be effortlessly implemented using tools like asyncio.gather.
2. Schema Cache: Boosting Performance Where It Counts
SDK v2 introduces a Schema Cache that stores collection schemas locally after the initial fetch, eliminating repeated network requests and CPU overhead during operations.
For high-frequency insert and query scenarios, this update translates to:
Reduced network traffic between client and server
Lower latency for operations
Decreased server-side CPU usage
Better scaling under high concurrency
This is particularly valuable for applications like real-time recommendation systems or live search features where milliseconds matter.
3. A Unified and Streamlined API Experience
Milvus SDK v2 introduces a unified and more complete API experience across all supported programming languages. Particularly, the RESTful API has been significantly enhanced to offer near feature parity with the gRPC interface.
In earlier versions, the RESTful API lagged behind gRPC, limiting what developers could do without switching interfaces. That’s no longer the case. Now, developers can use the RESTful API to perform virtually all core operations—such as creating collections, managing partitions, building indexes, and running queries—without needing to fall back on gRPC or other methods.
This unified approach ensures a consistent developer experience across different environments and use cases. It reduces the learning curve, simplifies integration, and improves overall usability.
Note: For most users, the RESTful API offers a faster and easier way to get started with Milvus. However, if your application demands high-performance or advanced features like iterators, the gRPC client remains the go-to option for maximum flexibility and control.
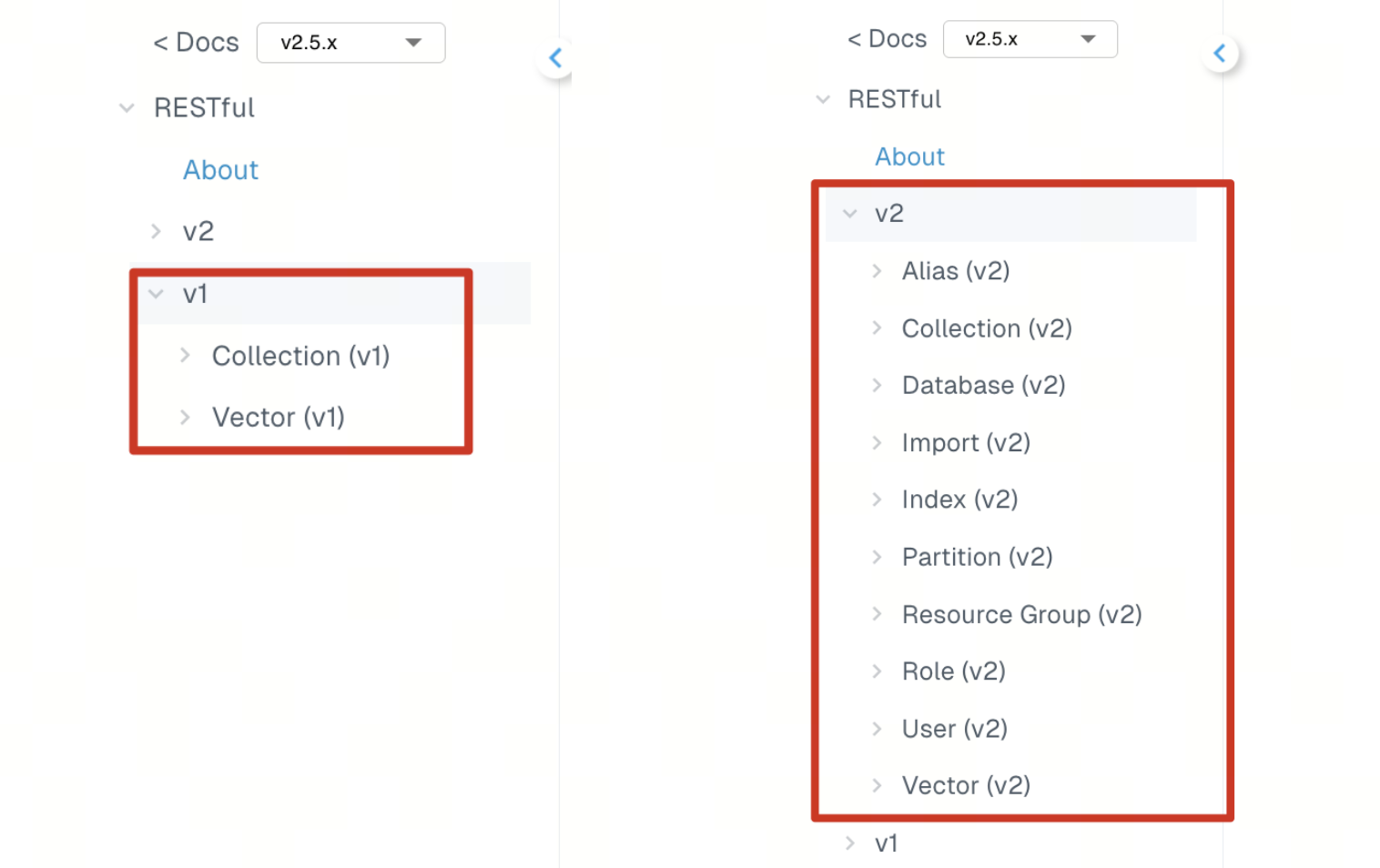
4. Aligned SDK Design Across All Languages
With Milvus SDK v2, we’ve standardized the design of our SDKs across all supported programming languages to deliver a more consistent developer experience.
Whether you’re building with Python, Java, Go, or Node.js, each SDK now follows a unified structure centered around the MilvusClient class. This redesign brings consistent method naming, parameter formatting, and overall usage patterns to every language we support. (See: MilvusClient SDK code example update · GitHub Discussion #33979)
Now, once you’re familiar with Milvus in one language, you can easily switch to another without having to relearn how the SDK works. This alignment not only simplifies onboarding but also makes multi-language development much smoother and more intuitive.
5. A Simpler, Smarter PyMilvus (Python SDK) with MilvusClient
In the previous version, PyMilvus relied on an ORM-style design that introduced a mix of object-oriented and procedural approaches. Developers had to define FieldSchema objects, build a CollectionSchema, and then instantiate a Collection class—all just to create a collection. This process was not only verbose but also introduced a steeper learning curve for new users.
With the new MilvusClient interface, things are much simpler. You can now create a collection in a single step using the create_collection() method. It allows you to quickly define the schema by passing parameters like dimension and metric_type, or you can still use a custom schema object if needed.
Even better, create_collection() supports index creation as part of the same call. If index parameters are provided, Milvus will automatically build the index and load the data into memory—no need for separate create_index() or load() calls. One method does it all: create collection → build index → load collection.
This streamlined approach reduces setup complexity and makes it much easier to get started with Milvus, especially for developers who want a quick and efficient path to prototyping or production.
The new MilvusClient module offers clear advantages in usability, consistency, and performance. While the legacy ORM interface remains available for now, we plan to phase it out in the future (see reference). We strongly recommend upgrading to the new SDK to take full advantage of the improvements.
6. Clearer and More Comprehensive Documentation
We have restructured the product documentation to provide a more complete and clearer API Reference. Our User Guides now include multi-language sample code, enabling you to get started quickly and understand Milvus’ features with ease. Additionally, the Ask AI assistant available on our documentation site can introduce new features, explain internal mechanisms, and even help generate or modify sample code, making your journey through the documentation smoother and more enjoyable.
7. Milvus MCP Server: Designed for the Future of AI Integration
The MCP Server, built on top of the Milvus SDK, is our answer to a growing need in the AI ecosystem: seamless integration between large language models (LLMs), vector databases, and external tools or data sources. It implements the Model Context Protocol (MCP), providing a unified and intelligent interface for orchestrating Milvus operations and beyond.
As AI agents become more capable—not just generating code but autonomously managing backend services—the demand for smarter, API-driven infrastructure is rising. The MCP Server was designed with this future in mind. It enables intelligent and automated interactions with Milvus clusters, streamlining tasks like deployment, maintenance, and data management.
More importantly, it lays the groundwork for a new kind of machine-to-machine collaboration. With the MCP Server, AI agents can call APIs to dynamically create collections, run queries, build indexes, and more—all without human intervention.
In short, the MCP Server transforms Milvus into not just a database, but a fully programmable, AI-ready backend—paving the way for intelligent, autonomous, and scalable applications.
Getting Started with Milvus SDK v2: Sample Code
The examples below show how to use the new PyMilvus (Python SDK v2) interface to create a collection and perform asynchronous operations. Compared to the ORM-style approach in the previous version, this code is cleaner, more consistent, and easier to work with.
1. Creating a Collection, Defining Schemas, Building Indexes, and Loading Data with MilvusClient
The Python code snippet below demonstrates how to create a collection, define its schema, build indexes, and load data—all in one call:
from pymilvus import MilvusClient, DataType
# 1. Connect to Milvus (initialize the client)
client = MilvusClient(uri="http://localhost:19530")
# 2. Define the collection schema
schema = MilvusClient.create_schema(auto_id=False, description="schema for example collection")
schema.add_field("id", DataType.INT64, is_primary=True) # Primary key field
schema.add_field("embedding", DataType.FLOAT_VECTOR, dim=128) # Vector field
# 3. Prepare index parameters (optional if indexing at creation time)
index_params = client.prepare_index_params()
index_params.add_index(
field_name="embedding",
index_type="AUTOINDEX",
metric_type="L2"
)
# 4. Create the collection with indexes and load it into memory automatically
client.create_collection(
collection_name="example_collection",
schema=schema,
index_params=index_params
)
print("Collection created and loaded with index!")
The create_collection method’s index_params parameter eliminates the need for separate calls for create_index and load_collection—everything happens automatically.
In addition, MilvusClient supports a quick table creation mode. For example, a collection can be created in a single line of code by specifying only the required parameters:
client.create_collection(
collection_name="test_collection",
dimension=128
)
(Comparison note: In the old ORM approach, you had to create a Collection(schema), then separately call collection.create_index() and collection.load(); now, MilvusClient streamlines the entire process.)
2. Performing High-Concurrency Asynchronous Inserts with AsyncMilvusClient
The following example shows how to use the AsyncMilvusClient to perform concurrent insert operations using async/await:
import asyncio
from pymilvus import AsyncMilvusClient
async def insert_vectors_concurrently():
client = AsyncMilvusClient(uri="http://localhost:19530")
vectors_to_insert = [[...], [...], ...] # Assume 100,000 vectors
batch_size = 1000 # Recommended batch size
tasks = []
for i in range(0, len(vectors_to_insert), batch_size):
batch_vectors = vectors_to_insert[i:i+batch_size]
# Construct batch data
data = [
list(range(i, i + len(batch_vectors))), # Batch IDs
batch_vectors # Batch vectors
]
# Add an asynchronous task for inserting each batch
tasks.append(client.insert("example_collection", data=data))
# Concurrently execute batch inserts
insert_results = await asyncio.gather(*tasks)
await client.close()
# Execute asynchronous tasks
asyncio.run(insert_vectors_concurrently())
In this example, AsyncMilvusClient is used to concurrently insert data by scheduling multiple insertion tasks with asyncio.gather. This approach takes full advantage of Milvus’ backend concurrent processing capabilities. Unlike the synchronous, line-by-line insertions in v1, this native asynchronous support dramatically increases throughput.
Similarly, you can modify the code to perform concurrent queries or searches—for example, by replacing the insert call with client.search("example_collection", data=[query_vec], limit=5). Milvus SDK v2’s asynchronous interface ensures that each request is executed in a non-blocking manner, fully leveraging both client and server resources.
Migration Made Easy
We know you’ve invested time in SDK v1, so we’ve designed SDK v2 with your existing applications in mind. SDK v2 includes backward compatibility, so existing v1/ORM-style interfaces will continue to work for a while. But we strongly recommend upgrading to SDK v2 as soon as possible—support for v1 will end with the release of Milvus 3.0 (end of 2025).
Moving to SDK v2 unlocks a more consistent, modern developer experience with simplified syntax, better async support, and improved performance. It’s also where all new features and community support are focused going forward. Upgrading now ensures you’re ready for what’s next and gives you access to the best Milvus has to offer.
Conclusion
Milvus SDK v2 brings significant improvements over v1: enhanced performance, a unified and consistent interface across multiple programming languages, and native asynchronous support that simplifies high-concurrency operations. With clearer documentation and more intuitive code examples, Milvus SDK v2 is designed to streamline your development process, making it easier and faster to build and deploy AI applications.
For more detailed information, please refer to our latest official API Reference and User Guides. If you have any questions or suggestions regarding the new SDK, feel free to provide feedback on GitHub and Discord. We look forward to your input as we continue to enhance Milvus.
- TL;DR
- Why We Built It: Addressing Community Pain Points
- The Solution: Milvus SDK v2
- Getting Started with Milvus SDK v2: Sample Code
- Migration Made Easy
- Conclusion
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word



