How OpusSearch Built Exact Matching for Enterprise RAG with Milvus BM25
This post was originally published on Medium and is reposted here with permission.
The Semantic Search Blind Spot
Picture this: You’re a video editor on deadline. You need clips from “episode 281” of your podcast. You type it into our search. Our AI-powered semantic search, proud of its intelligence, returns clips from 280, 282, and even suggests episode 218 because the numbers are similar, right?
Wrong.
When we launched OpusSearch for enterprises in January 2025, we thought semantic search would be enough. Natural language queries like “find funny moments about dating” worked beautifully. Our Milvus-powered RAG system was crushing it.
But then reality hit us in the face with user feedback:
“I just want clips from episode 281. Why is this so hard?”
“When I search ‘That’s what she said,’ I want EXACTLY that phrase, not ‘that’s what he meant.’”
Turns out that video editors and clippers don’t always want AI to be clever. Sometimes they want software to be straightforward and correct.
Why do we care about Search?
We built an enterprise search function because we identified that monetizing large video catalogs is the key challenge organizations face. Our RAG-powered platform serves as a growth agent that enables enterprises to search, repurpose, and monetize their entire video libraries. Read about success case stories from All The Smoke, KFC Radio and TFTC here.
Why We Doubled Down on Milvus (Instead of Adding Another Database)
The obvious solution was to add Elasticsearch or MongoDB for exact matching. However, as a startup, maintaining multiple search systems introduces significant operational overhead and complexity.
Milvus had recently shipped their full-text search feature, and an evaluation with our own dataset without any tuning showed compelling advantages:
Superior partial matching accuracy. For example “drinking story” and “jumping high”, other vector DBs returns sometimes “dining story” and “getting high” which alters the meaning.
Milvus returns longer, more comprehensive results than other databases when queries are general, which is naturally more ideal for our use case.
Architecture from 5000 feet
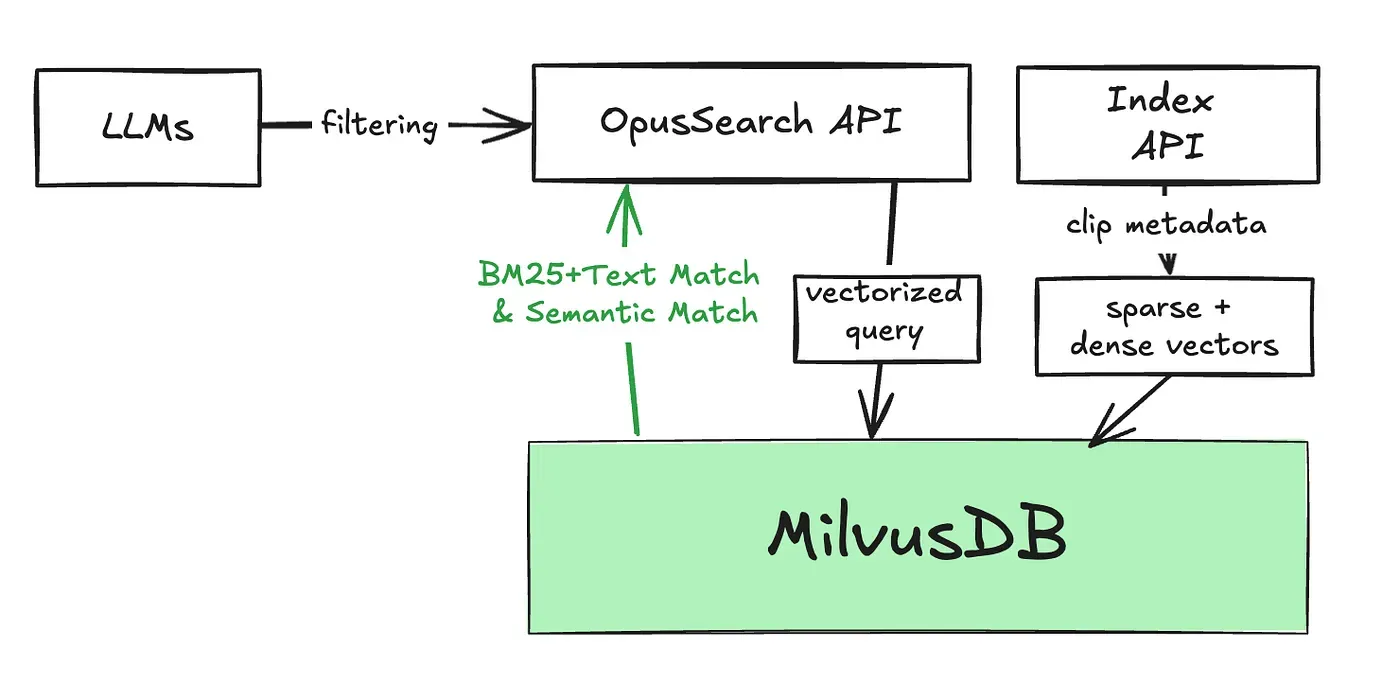
BM25 + Filtering = Exact Match Magic
Milvus’s full-text search isn’t really about exact matching, but it’s about relevance scoring using BM25 (Best Matching 25), which calculates how relevant a document is to your query. It’s great for “find me something close,” but terrible for “find me exactly this.”
We then combined BM25’s power with Milvus’s TEXT_MATCH filtering. Here’s how it works:
Filter first: TEXT_MATCH finds documents containing your exact keywords
Rank second: BM25 sorts those exact matches by relevance
Win: You get exact matches, ranked intelligently
Think of it as “give me everything with ‘episode 281’, then show me the best ones first.”
The Code That Made It Work
Schema Design
Important: We disabled stop words entirely, as terms like “The Office” and “Office” represent distinct entities in our content domain.
export function getExactMatchFields(): FieldType[] {
return [
{
name: "id",
data_type: DataType.VarChar,
is_primary_key: true,
max_length: 100,
},
{
name: "text",
data_type: DataType.VarChar,
max_length: 1000,
enable_analyzer: true,
enable_match: true, // This is the magic flag
analyzer_params: {
tokenizer: 'standard',
filter: [
'lowercase',
{
type: 'stemmer',
language: 'english', // "running" matches "run"
},
{
type: 'stop',
stop_words: [], // Keep ALL words (even "the", "a")
},
],
},
},
{
name: "sparse_vector",
data_type: DataType.SparseFloatVector,
},
]
}
BM25 Function Setup
export const FUNCTIONS: FunctionObject[] = [
{
name: 'text_bm25_embedding',
type: FunctionType.BM25,
input_field_names: ['text'],
output_field_names: ['sparse_vector'],
params: {},
},
]
Index Config
These bm25_k1 and bm25_b parameters were tuned against our production dataset for optimal performance.
bm25_k1: Higher values (up to ~2.0) give more weight to repeated term occurrences, while lower values reduce the impact of term frequency after the first few occurrences.
bm25_b: Values closer to 1.0 heavily penalize longer documents, while values closer to 0 ignore document length entirely.
index_params: [
{
field_name: 'sparse_vector',
index_type: 'SPARSE_INVERTED_INDEX',
metric_type: 'BM25',
params: {
inverted_index_algo: 'DAAT_MAXSCORE',
bm25_k1: 1.2, // How much does term frequency matter?
bm25_b: 0.75, // How much does document length matter?
},
},
],
The Search Query That Started Working
await this.milvusClient.search({
collection_name: 'my_collection',
limit: 30,
output_fields: ['id', 'text'],
filter: `TEXT_MATCH(text, "episode 281")`, // Exact match filter
anns_field: 'sparse_vector',
data: 'episode 281', // BM25 ranking query
})
For multi-term exact matches:
filter: `TEXT_MATCH(text, "foo") and TEXT_MATCH(text, "bar")`
The Mistakes We Made (So You Don’t Have To)
Dynamic Fields: Critical for Production Flexibility
Initially, we didn’t enable dynamic fields, which was problematic. Schema modifications required dropping and recreating collections in production environments.
await this.milvusClient.createCollection({
collection_name: collectionName,
fields: fields,
enable_dynamic_field: true, // DO THIS
// ... rest of config
})
Collection Design: Maintain Clear Separation of Concerns
Our architecture uses dedicated collections per feature domain. This modular approach minimizes the impact of schema changes and improves maintainability.
Memory Usage: Optimize with MMAP
Sparse indexes require significant memory allocation. For large text datasets, we recommend configuring MMAP to utilize disk storage. This approach requires adequate I/O capacity to maintain performance characteristics.
// In your Milvus configuration
use_mmap: true
Production Impact and Results
Following the June 2025 deployment of exact match functionality, we observed measurable improvements in user satisfaction metrics and reduced support volume for search-related issues. Our dual-mode approach enables semantic search for exploratory queries while providing precise matching for specific content retrieval.
The key architectural benefit: maintaining a single database system that supports both search paradigms, reducing operational complexity while expanding functionality.
What’s Next?
We’re experimenting with hybrid queries combining semantic and exact match in a single search. Imagine: “Find funny clips from episode 281” where “funny” uses semantic search and “episode 281” uses exact match.
The future of search isn’t picking between semantic AI and exact matching. It’s using both intelligently in the same system.
- The Semantic Search Blind Spot
- Why do we care about Search?
- Why We Doubled Down on Milvus (Instead of Adding Another Database)
- Architecture from 5000 feet
- BM25 + Filtering = Exact Match Magic
- The Code That Made It Work
- Schema Design
- BM25 Function Setup
- Index Config
- The Search Query That Started Working
- The Mistakes We Made (So You Don’t Have To)
- Dynamic Fields: Critical for Production Flexibility
- Collection Design: Maintain Clear Separation of Concerns
- Memory Usage: Optimize with MMAP
- Production Impact and Results
- What’s Next?
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



