Tokenize Smarter, Retrieve Better: A Deep Dive into Milvus Analyzer for Full-Text Search
Modern AI applications are complex and rarely one-dimensional. In many cases, a single search method can’t solve real-world problems on its own. Take a recommendation system, for example. It requires vector search to comprehend the meaning behind text or images, metadata filtering to refine results by price, category, or location, and full-text search to handle direct queries like “Nike Air Max.” Each method solves a different part of the puzzle—and practical systems depend on all of them working together seamlessly.
Milvus excels at vector search and metadata filtering, and starting with version 2.5, it introduced full-text search based on the optimized BM25 algorithm. This upgrade makes AI search both smarter and more accurate, combining semantic understanding with precise keyword intent. With Milvus 2.6, full-text search becomes even faster—up to 4× the performance of Elasticsearch.
At the heart of this capability is the Milvus Analyzer, the component that transforms raw text into searchable tokens. It’s what enables Milvus to interpret language efficiently and perform keyword matching at scale. In the rest of this post, we’ll dive into how the Milvus Analyzer works—and why it’s key to unlocking the full potential of hybrid search in Milvus.
What is Milvus Analyzer?
To power efficient full-text search—whether for keyword matching or semantic retrieval—the first step is always the same: turning raw text into tokens that the system can understand, index, and compare.
The Milvus Analyzer handles this step. It’s a built-in text preprocessing and tokenization component that breaks input text into discrete tokens, then normalizes, cleans, and standardizes them to ensure consistent matching across queries and documents. This process lays the foundation for accurate, high-performance full-text search and hybrid retrieval.
Here’s an overview of the Milvus Analyzer architecture:
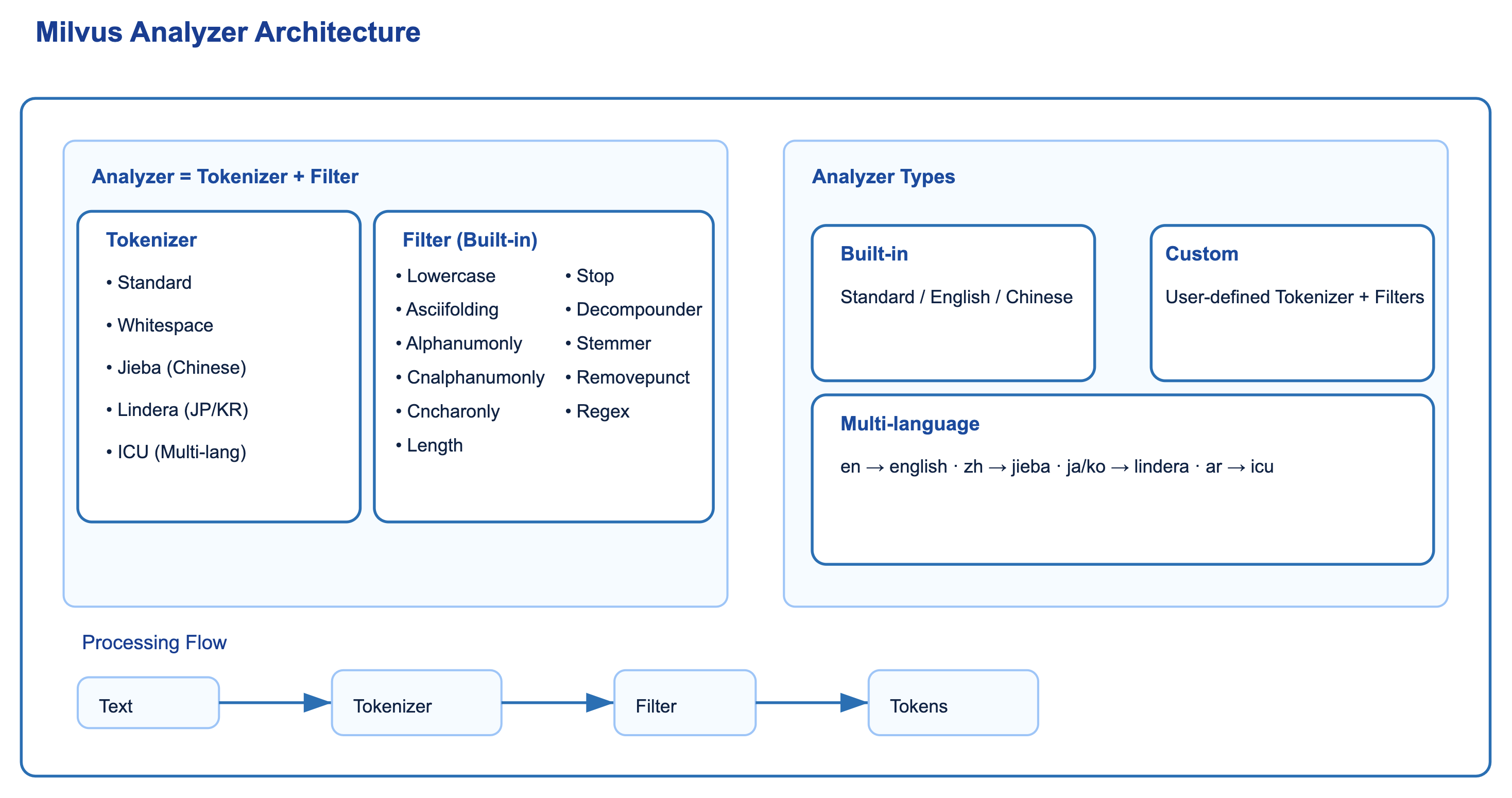
As the diagram shows, Analyzer has two core components: the Tokenizer and the Filter. Together, they convert input text into tokens and optimize them for efficient indexing and retrieval.
Tokenizer: Splits text into basic tokens using methods like whitespace splitting (Whitespace), Chinese word segmentation (Jieba), or multilingual segmentation (ICU).
Filter: Processes tokens through specific transformations. Milvus includes a rich set of built-in filters for operations like case normalization (Lowercase), punctuation removal (Removepunct), stop word filtering (Stop), stemming (Stemmer), and pattern matching (Regex). You can chain multiple filters to handle complex processing needs.
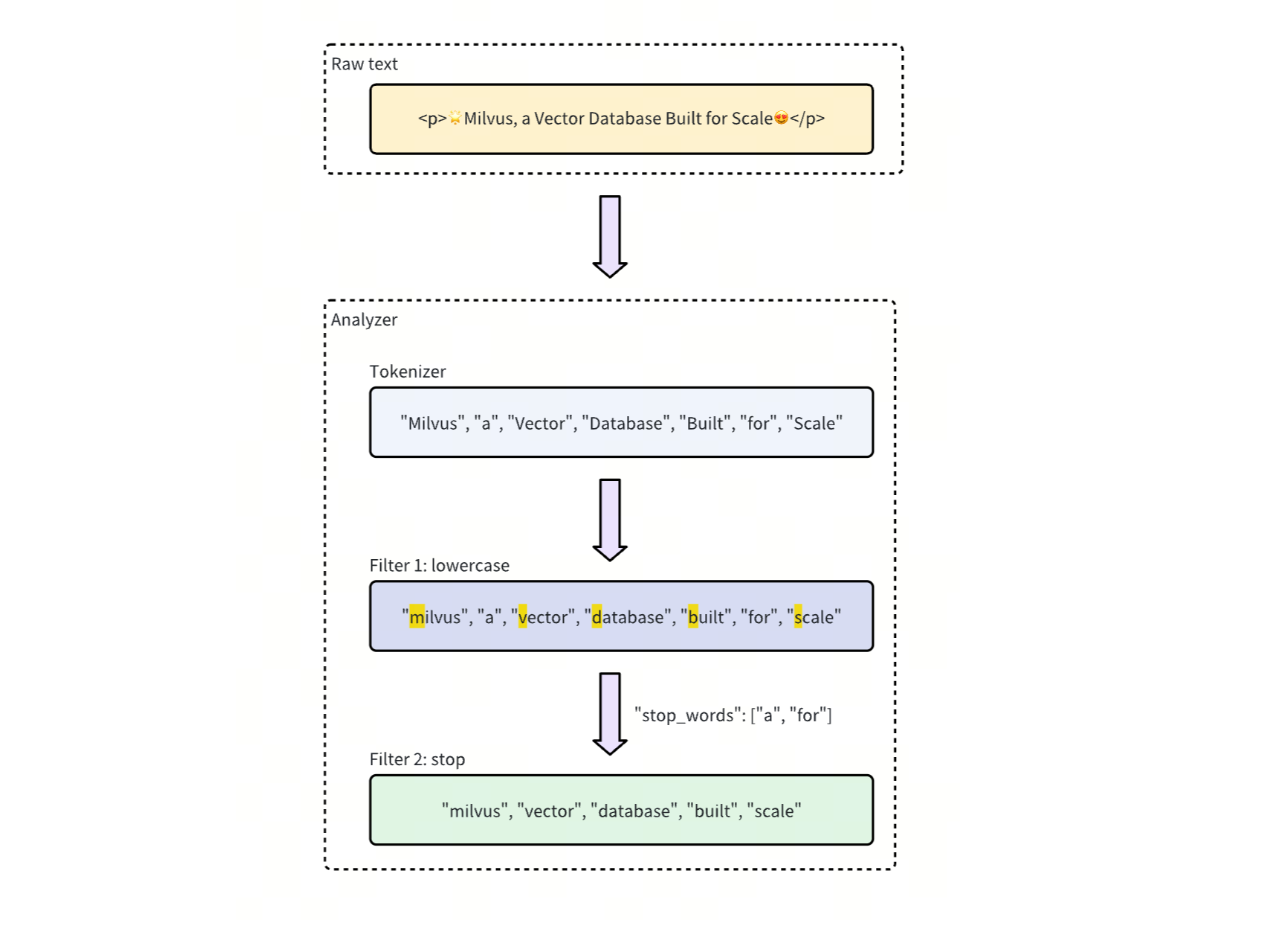
Milvus offers several Analyzer types: three built-in options (Standard, English, and Chinese), Custom Analyzers where you define your own Tokenizer and Filter combinations, and the Multi-language Analyzer for handling multilingual documents. The processing flow is straightforward: Raw text → Tokenizer → Filter → Tokens.
Tokenizer
The Tokenizer is the first processing step. It splits raw text into smaller tokens (words or subwords), and the right choice depends on your language and use case.
Milvus currently supports the following types of tokenizers:
| Tokenizer | Use Case | Description |
|---|---|---|
| Standard | English and space-delimited languages | The most common general-purpose tokenizer; detects word boundaries and splits accordingly. |
| Whitespace | Simple text with minimal preprocessing | Splits only by spaces; does not handle punctuation or casing. |
| Jieba(Chinese) | Chinese text | Dictionary and probability-based tokenizer that splits continuous Chinese characters into meaningful words. |
| Lindera(JP/KR) | Japanese and Korean text | Uses Lindera morphological analysis for effective segmentation. |
| ICU(Multi-language) | Complex languages like Arabic, and multilingual scenarios | Based on the ICU library with support for multilingual tokenization across Unicode. |
You can configure the Tokenizer when creating your Collection’s Schema, specifically when defining VARCHAR fields through the analyzer_params parameter. In other words, the Tokenizer is not a standalone object but a field-level configuration. Milvus automatically performs tokenization and preprocessing when inserting data.
FieldSchema(
name="text",
dtype=DataType.VARCHAR,
max_length=512,
analyzer_params={
"tokenizer": "standard" # Configure Tokenizer here
}
)
Filter
If the Tokenizer cuts text apart, the Filter refines what’s left. Filters standardize, clean, or transform your tokens to make them search-ready.
Common Filter operations include normalizing case, removing stop words (like “the” and “and”), stripping punctuation, and applying stemming (reducing “running” to “run”).
Milvus includes many built-in Filters for most language processing needs:
| Filter Name | Function | Use Case |
|---|---|---|
| Lowercase | Converts all tokens to lowercase | Essential for English search to avoid case mismatches |
| Asciifolding | Converts accented characters to ASCII | Multilingual scenarios (e.g., “café” → “cafe”) |
| Alphanumonly | Keeps only letters and numbers | Strips mixed symbols from text like logs |
| Cncharonly | Keeps only Chinese characters | Chinese corpus cleaning |
| Cnalphanumonly | Keeps only Chinese, English, and numbers | Mixed Chinese-English text |
| Length | Filters tokens by length | Removes excessively short or long tokens |
| Stop | Stop word filtering | Removes high-frequency meaningless words like “is” and “the” |
| Decompounder | Splits compound words | Languages with frequent compounds like German and Dutch |
| Stemmer | Word stemming | English scenarios (e.g.,"studies" and “studying” → “study” |
| Removepunct | Removes punctuation | General text cleaning |
| Regex | Filters or replaces with a regex pattern | Custom needs, like extracting only email addresses |
The power of Filters is in their flexibility—you can mix and match cleaning rules based on your needs. For English search, a typical combination is Lowercase + Stop + Stemmer, ensuring case uniformity, removing filler words, and normalizing word forms to their stem.
For Chinese search, you’ll usually combine Cncharonly + Stop for cleaner, more precise results. Configure Filters the same way as Tokenizers, through analyzer_params in your FieldSchema:
FieldSchema(
name="text",
dtype=DataType.VARCHAR,
max_length=512,
analyzer_params={
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stop", # Specifies the filter type as stop
"stop_words": ["of", "to", "_english_"], # Defines custom stop words and includes the English stop word list
},
{
"type": "stemmer", # Specifies the filter type as stemmer
"language": "english"
}],
}
)
Analyzer Types
The right Analyzer makes your search both faster and more cost-effective. To fit different needs, Milvus provides three types: Built-in, Multi-language, and Custom Analyzers.
Built-in Analyzer
Built-in Analyzers are ready to use out of the box—standard configurations that work for most common scenarios. They come with predefined Tokenizer and Filter combinations:
| Name | Components(Tokenizer+Filters) | Use Case |
|---|---|---|
| Standard | Standard Tokenizer + Lowercase | General use for English or space-delimited languages |
| English | Standard Tokenizer + Lowercase + Stop + Stemmer | English search with higher precision |
| Chinese | Jieba Tokenizer + Cnalphanumonly | Chinese text search with natural word segmentation |
For straightforward English or Chinese search, these built-in Analyzers work without any extra setup.
One important note: the Standard Analyzer is designed for English by default. If applied to Chinese text, full-text search may return no results.
Multi-language Analyzer
When you deal with multiple languages, a single tokenizer often can’t handle everything. That’s where the Multi-language Analyzer comes in—it automatically picks the right tokenizer based on each text’s language. Here’s how languages map to Tokenizers:
| Language Code | Tokenizer Used |
|---|---|
| en | English Analyzer |
| zh | Jieba |
| ja / ko | Lindera |
| ar | ICU |
If your dataset mixes English, Chinese, Japanese, Korean, and even Arabic, Milvus can handle them all in the same field. This cuts down dramatically on manual preprocessing.
Custom Analyzer
When Built-in or Multi-language Analyzers don’t quite fit, Milvus lets you build Custom Analyzers. Mix and match Tokenizers and Filters to create something tailored to your needs. Here’s an example:
FieldSchema(
name="text",
dtype=DataType.VARCHAR,
max_length=512,
analyzer_params={
"tokenizer": "jieba",
"filter": ["cncharonly", "stop"] # Custom combination for mixed Chinese-English text
}
)
Hands-on Coding with Milvus Analyzer
Theory helps, but nothing beats a full code example. Let’s walk through how to use Analyzers in Milvus with the Python SDK, covering both built-in Analyzers and multi-language Analyzers. These examples use Milvus v2.6.1 and Pymilvus v2.6.1.
How to Use Built-in Analyzer
Say you want to build a Collection for English text search that automatically handles tokenization and preprocessing during data insertion. We’ll use the built-in English Analyzer (equivalent to standard + lowercase + stop + stemmer ).
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(
uri="http://localhost:19530",
)
schema = client.create_schema()
schema.add_field(
field_name="id", # Field name
datatype=DataType.INT64, # Integer data type
is_primary=True, # Designate as primary key
auto_id=True # Auto-generate IDs (recommended)
)
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=1000,
enable_analyzer=True,
analyzer_params={
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stop", # Specifies the filter type as stop
"stop_words": ["of", "to", "_english_"], # Defines custom stop words and includes the English stop word list
},
{
"type": "stemmer", # Specifies the filter type as stemmer
"language": "english"
}],
},
enable_match=True,
)
schema.add_field(
field_name="sparse", # Field name
datatype=DataType.SPARSE_FLOAT_VECTOR # Sparse vector data type
)
bm25_function = Function(
name="text_to_vector", # Descriptive function name
function_type=FunctionType.BM25, # Use BM25 algorithm
input_field_names=["text"], # Process text from this field
output_field_names=["sparse"] # Store vectors in this field
)
schema.add_function(bm25_function)
index_params = client.prepare_index_params()
index_params.add_index(
field_name="sparse", # Field to index (our vector field)
index_type="AUTOINDEX", # Let Milvus choose optimal index type
metric_type="BM25" # Must be BM25 for this feature
)
COLLECTION_NAME = "english_demo"
if client.has_collection(COLLECTION_NAME):
client.drop_collection(COLLECTION_NAME)
print(f"Dropped existing collection: {COLLECTION_NAME}")
client.create_collection(
collection_name=COLLECTION_NAME, # Collection name
schema=schema, # Our schema
index_params=index_params # Our search index configuration
)
print(f"Successfully created collection: {COLLECTION_NAME}")
# Prepare sample data
sample_texts = [
"The quick brown fox jumps over the lazy dog",
"Machine learning algorithms are revolutionizing artificial intelligence",
"Python programming language is widely used for data science projects",
"Natural language processing helps computers understand human languages",
"Deep learning models require large amounts of training data",
"Search engines use complex algorithms to rank web pages",
"Text analysis and information retrieval are important NLP tasks",
"Vector databases enable efficient similarity searches",
"Stemming reduces words to their root forms for better searching",
"Stop words like 'the', 'and', 'of' are often filtered out"
]
# Insert data
print("\nInserting data...")
data = [{"text": text} for text in sample_texts]
client.insert(
collection_name=COLLECTION_NAME,
data=data
)
print(f"Successfully inserted {len(sample_texts)} records")
# Demonstrate tokenizer effect
print("\n" + "="*60)
print("Tokenizer Analysis Demo")
print("="*60)
test_text = "The running dogs are jumping over the lazy cats"
print(f"\nOriginal text: '{test_text}'")
# Use run_analyzer to show tokenization results
analyzer_result = client.run_analyzer(
texts=test_text,
collection_name=COLLECTION_NAME,
field_name="text"
)
print(f"Tokenization result: {analyzer_result}")
print("\nBreakdown:")
print("- lowercase: Converts all letters to lowercase")
print("- stop words: Filtered out ['of', 'to'] and common English stop words")
print("- stemmer: Reduced words to stem form (running -> run, jumping -> jump)")
# Full-text search demo
print("\n" + "="*60)
print("Full-Text Search Demo")
print("="*60)
# Wait for indexing to complete
import time
time.sleep(2)
# Search query examples
search_queries = [
"jump", # Test stem matching (should match "jumps")
"algorithm", # Test exact matching
"python program", # Test multi-word query
"learn" # Test stem matching (should match "learning")
]
for i, query in enumerate(search_queries, 1):
print(f"\nQuery {i}: '{query}'")
print("-" * 40)
# Execute full-text search
search_results = client.search(
collection_name=COLLECTION_NAME,
data=[query], # Query text
search_params={"metric_type": "BM25"},
output_fields=["text"], # Return original text
limit=3 # Return top 3 results
)
if search_results and len(search_results[0]) > 0:
for j, result in enumerate(search_results[0], 1):
score = result["distance"]
text = result["entity"]["text"]
print(f" Result {j} (relevance: {score:.4f}): {text}")
else:
print(" No relevant results found")
print("\n" + "="*60)
print("Search complete!")
print("="*60)
Output:
Dropped existing collection: english_demo
Successfully created collection: english_demo
Inserting data...
Successfully inserted 10 records
============================================================
Tokenizer Analysis Demo
============================================================
Original text: 'The running dogs are jumping over the lazy cats'
Tokenization result: ['run', 'dog', 'jump', 'over', 'lazi', 'cat']
Breakdown:
- lowercase: Converts all letters to lowercase
- stop words: Filtered out ['of', 'to'] and common English stop words
- stemmer: Reduced words to stem form (running -> run, jumping -> jump)
============================================================
Full-Text Search Demo
============================================================
Query 1: 'jump'
----------------------------------------
Result 1 (relevance: 2.0040): The quick brown fox jumps over the lazy dog
Query 2: 'algorithm'
----------------------------------------
Result 1 (relevance: 1.5819): Machine learning algorithms are revolutionizing artificial intelligence
Result 2 (relevance: 1.4086): Search engines use complex algorithms to rank web pages
Query 3: 'python program'
----------------------------------------
Result 1 (relevance: 3.7884): Python programming language is widely used for data science projects
Query 4: 'learn'
----------------------------------------
Result 1 (relevance: 1.5819): Machine learning algorithms are revolutionizing artificial intelligence
Result 2 (relevance: 1.4086): Deep learning models require large amounts of training data
============================================================
Search complete!
============================================================
How to Use Multi-language Analyzer
When your dataset contains multiple languages—English, Chinese, and Japanese, for example—you can enable the Multi-language Analyzer. Milvus will automatically pick the right tokenizer based on each text’s language.
from pymilvus import MilvusClient, DataType, Function, FunctionType
import time
# Configure connection
client = MilvusClient(
uri="http://localhost:19530",
)
COLLECTION_NAME = "multilingual_demo"
# Drop existing collection if present
if client.has_collection(COLLECTION_NAME):
client.drop_collection(COLLECTION_NAME)
# Create schema
schema = client.create_schema()
# Add primary key field
schema.add_field(
field_name="id",
datatype=DataType.INT64,
is_primary=True,
auto_id=True
)
# Add language identifier field
schema.add_field(
field_name="language",
datatype=DataType.VARCHAR,
max_length=50
)
# Add text field with multi-language analyzer configuration
multi_analyzer_params = {
"by_field": "language", # Select analyzer based on language field
"analyzers": {
"en": {
"type": "english" # English analyzer
},
"zh": {
"type": "chinese" # Chinese analyzer
},
"jp": {
"tokenizer": "icu", # Use ICU tokenizer for Japanese
"filter": [
"lowercase",
{
"type": "stop",
"stop_words": ["は", "が", "の", "に", "を", "で", "と"]
}
]
},
"default": {
"tokenizer": "icu" # Default to ICU general tokenizer
}
},
"alias": {
"english": "en",
"chinese": "zh",
"japanese": "jp",
"中文": "zh",
"英文": "en",
"日文": "jp"
}
}
schema.add_field(
field_name="text",
datatype=DataType.VARCHAR,
max_length=2000,
enable_analyzer=True,
multi_analyzer_params=multi_analyzer_params
)
# Add sparse vector field for BM25
schema.add_field(
field_name="sparse_vector",
datatype=DataType.SPARSE_FLOAT_VECTOR
)
# Define BM25 function
bm25_function = Function(
name="text_bm25",
function_type=FunctionType.BM25,
input_field_names=["text"],
output_field_names=["sparse_vector"]
)
schema.add_function(bm25_function)
# Prepare index parameters
index_params = client.prepare_index_params()
index_params.add_index(
field_name="sparse_vector",
index_type="AUTOINDEX",
metric_type="BM25"
)
# Create collection
client.create_collection(
collection_name=COLLECTION_NAME,
schema=schema,
index_params=index_params
)
# Prepare multilingual test data
multilingual_data = [
# English data
{"language": "en", "text": "Artificial intelligence is revolutionizing technology industries worldwide"},
{"language": "en", "text": "Machine learning algorithms process large datasets efficiently"},
{"language": "en", "text": "Vector databases provide fast similarity search capabilities"},
# Chinese data
{"language": "zh", "text": "人工智能正在改变世界各行各业"},
{"language": "zh", "text": "机器学习算法能够高效处理大规模数据集"},
{"language": "zh", "text": "向量数据库提供快速的相似性搜索功能"},
# Japanese data
{"language": "jp", "text": "人工知能は世界中の技術産業に革命をもたらしています"},
{"language": "jp", "text": "機械学習アルゴリズムは大量のデータセットを効率的に処理します"},
{"language": "jp", "text": "ベクトルデータベースは高速な類似性検索機能を提供します"},
]
client.insert(
collection_name=COLLECTION_NAME,
data=multilingual_data
)
# Wait for BM25 function to generate vectors
print("Waiting for BM25 vector generation...")
client.flush(COLLECTION_NAME)
time.sleep(5)
client.load_collection(COLLECTION_NAME)
# Demonstrate tokenizer effect
print("\nTokenizer Analysis:")
test_texts = {
"en": "The running algorithms are processing data efficiently",
"zh": "这些运行中的算法正在高效地处理数据",
"jp": "これらの実行中のアルゴリズムは効率的にデータを処理しています"
}
for lang, text in test_texts.items():
print(f"{lang}: {text}")
try:
analyzer_result = client.run_analyzer(
texts=text,
collection_name=COLLECTION_NAME,
field_name="text",
analyzer_names=[lang]
)
print(f" → {analyzer_result}")
except Exception as e:
print(f" → Analysis failed: {e}")
# Multi-language search demo
print("\nSearch Test:")
search_cases = [
("zh", "人工智能"),
("jp", "機械学習"),
("en", "algorithm"),
]
for lang, query in search_cases:
print(f"\n{lang} '{query}':")
try:
search_results = client.search(
collection_name=COLLECTION_NAME,
data=[query],
search_params={"metric_type": "BM25"},
output_fields=["language", "text"],
limit=3,
filter=f'language == "{lang}"'
)
if search_results and len(search_results[0]) > 0:
for result in search_results[0]:
score = result["distance"]
text = result["entity"]["text"]
print(f" {score:.3f}: {text}")
else:
print(" No results")
except Exception as e:
print(f" Error: {e}")
print("\nComplete")
Output:
Waiting for BM25 vector generation...
Tokenizer Analysis:
en: The running algorithms are processing data efficiently
→ ['run', 'algorithm', 'process', 'data', 'effici']
zh: 这些运行中的算法正在高效地处理数据
→ ['这些', '运行', '中', '的', '算法', '正在', '高效', '地', '处理', '数据']
jp: これらの実行中のアルゴリズムは効率的にデータを処理しています
→ ['これらの', '実行', '中の', 'アルゴリズム', '効率', '的', 'データ', '処理', 'し', 'てい', 'ます']
Search Test:
zh '人工智能':
3.300: 人工智能正在改变世界各行各业
jp '機械学習':
3.649: 機械学習アルゴリズムは大量のデータセットを効率的に処理します
en 'algorithm':
2.096: Machine learning algorithms process large datasets efficiently
Complete
Also, Milvus supports the language_identifier tokenizer for search. It automatically detects the languages of a given text, which means the language field is optional. For more details, check out How Milvus 2.6 Upgrades Multilingual Full-Text Search at Scale.
Conclusion
The Milvus Analyzer turns what used to be a simple preprocessing step into a well-defined, modular system for handling text. Its design—built around tokenization and filtering—gives developers fine-grained control over how language is interpreted, cleaned, and indexed. Whether you’re building a single-language application or a global RAG system that spans multiple languages, the Analyzer provides a consistent foundation for full-text search. It’s the part of Milvus that quietly makes everything else work better.
Have questions or want a deep dive on any feature? Join our Discord channel or file issues on GitHub. You can also book a 20-minute one-on-one session to get insights, guidance, and answers to your questions through Milvus Office Hours.
- What is Milvus Analyzer?
- Tokenizer
- Filter
- Analyzer Types
- Built-in Analyzer
- Multi-language Analyzer
- Custom Analyzer
- Hands-on Coding with Milvus Analyzer
- How to Use Built-in Analyzer
- How to Use Multi-language Analyzer
- Conclusion
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



