We Replaced Kafka/Pulsar with a Woodpecker for Milvus—Here’s What Happened
TL;DR: We built Woodpecker, a cloud-native Write-Ahead Logging (WAL) system, to replace Kafka and Pulsar in Milvus 2.6. The result? Simplified operations, better performance, and lower costs for our Milvus vector database.

The Starting Point: When Message Queues No Longer Fit
We loved and used Kafka and Pulsar. They worked until they didn’t. As Milvus, the leading open-source vector database, evolved, we found that these powerful message queues no longer met our scalability requirements. So we made a bold move: we rewrote the streaming backbone in Milvus 2.6 and implemented our own WAL — Woodpecker.
Let me walk you through our journey and explain why we made this change, which might seem counterintuitive at first glance.
Cloud-Native From Day One
Milvus has been a cloud-native vector database from its inception. We leverage Kubernetes for elastic scaling and quick failure recovery, alongside object storage solutions like Amazon S3 and MinIO for data persistence.
This cloud-first approach offers tremendous advantages, but it also presents some challenges:
Cloud object storage services like S3 provide virtually unlimited capability of handling throughputs and availability, but with latencies often exceeding 100ms.
These services’ pricing models (based on access patterns and frequency) can add unexpected costs to real-time database operations.
Balancing cloud-native characteristics with the demands of real-time vector search introduces significant architectural challenges.
The Shared Log Architecture: Our Foundation
Many vector search systems restrict themselves to batch processing because building a streaming system in a cloud-native environment presents even greater challenges. In contrast, Milvus prioritizes real-time data freshness and implements a shared log architecture—think of it as a hard drive for a filesystem.
This shared log architecture provides a critical foundation that separates consensus protocols from core database functionality. By adopting this approach, Milvus eliminates the need to manage complex consensus protocols directly, allowing us to focus on delivering exceptional vector search capabilities.
We’re not alone in this architectural pattern—databases such as AWS Aurora, Azure Socrates, and Neon all leverage a similar design. However, a significant gap remains in the open-source ecosystem: despite the clear advantages of this approach, the community lacks a low-latency, scalable, and cost-effective distributed write-ahead log (WAL) implementation.
Existing solutions like Bookie proved inadequate for our needs due to their heavyweight client design and the absence of production-ready SDKs for Golang and C++. This technological gap led us to our initial approach with message queues.
Our Initial Solution: Message Queues as WAL
To bridge this gap, our initial approach utilized message queues (Kafka/Pulsar) as our write-ahead log (WAL). The architecture worked like this:
All incoming real-time updates flow through the message queue.
Writers receive immediate confirmation once it is accepted by the message queue.
QueryNode and DataNode process this data asynchronously, ensuring high write throughput while maintaining data freshness
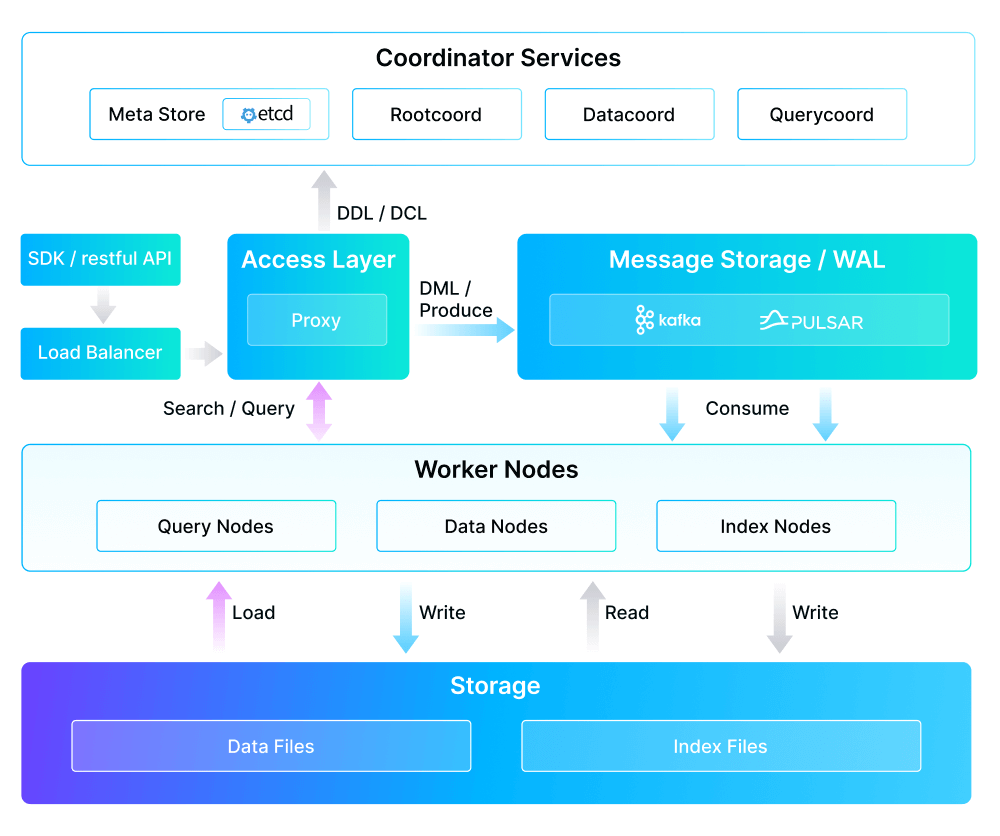
Figure: Milvus 2.0 Architecture Overview
This system effectively provided immediate write confirmation while enabling asynchronous data processing, which was crucial for maintaining the balance between throughput and data freshness that Milvus users expect.
Why We Needed Something Different for WAL
With Milvus 2.6, we’ve decided to phase out external message queues in favor of Woodpecker, our purpose-built, cloud-native WAL implementation. This wasn’t a decision we made lightly. After all, we had successfully used Kafka and Pulsar for years.
The issue wasn’t with these technologies themselves—both are excellent systems with powerful capabilities. Instead, the challenge came from the increasing complexity and overhead that these external systems introduced as Milvus evolved. As our requirements became more specialized, the gap between what general-purpose message queues offered and what our vector database needed continued to widen.
Three specific factors ultimately drove our decision to build a replacement:
Operational Complexity
External dependencies like Kafka or Pulsar demand dedicated machines with multiple nodes and careful resource management. This creates several challenges:
- Increased operational complexity
- Steeper learning curves for system administrators
- Higher risks of configuration errors and security vulnerabilities
Architectural Constraints
Message queues like Kafka have inherent limitations on the number of supported topics. We developed VShard as a workaround for topic sharing across components, but this solution—while effectively addressing scaling needs—introduced significant architectural complexity.
These external dependencies made it harder to implement critical features—such as log garbage collection—and increased integration friction with other system modules. Over time, the architectural mismatch between general-purpose message queues and the specific, high-performance demands of a vector database became increasingly clear, prompting us to reassess our design choices.
Resource Inefficiency
Ensuring high availability with systems like Kafka and Pulsar typically demands:
Distributed deployment across multiple nodes
Substantial resource allocation even for smaller workloads
Storage for ephemeral signals (like Milvus’s Timetick), which don’t actually require long-term retention
However, these systems lack the flexibility to bypass persistence for such transient signals, leading to unnecessary I/O operations and storage usage. This leads to disproportionate resource overhead and increased cost—especially in smaller-scale or resource-constrained environments.
Introducing Woodpecker - A Cloud-Native, High-Performance WAL Engine
In Milvus 2.6, we’ve replaced Kafka/Pulsar with Woodpecker, a purpose-built, cloud-native WAL system. Designed for object storage, Woodpecker simplifies operations while boosting performance and scalability.
Woodpecker is built from the ground up to maximize the potential of cloud-native storage, with a focused goal: to become the highest-throughput WAL solution optimized for cloud environments while delivering the core capabilities needed for an append-only write-ahead log.
The Zero-Disk Architecture for Woodpecker
Woodpecker’s core innovation is its Zero-Disk architecture:
All log data stored in cloud object storage (such as Amazon S3, Google Cloud Storage, or Alibaba OS)
Metadata managed through distributed key-value stores like etcd
No local disk dependencies for core operations
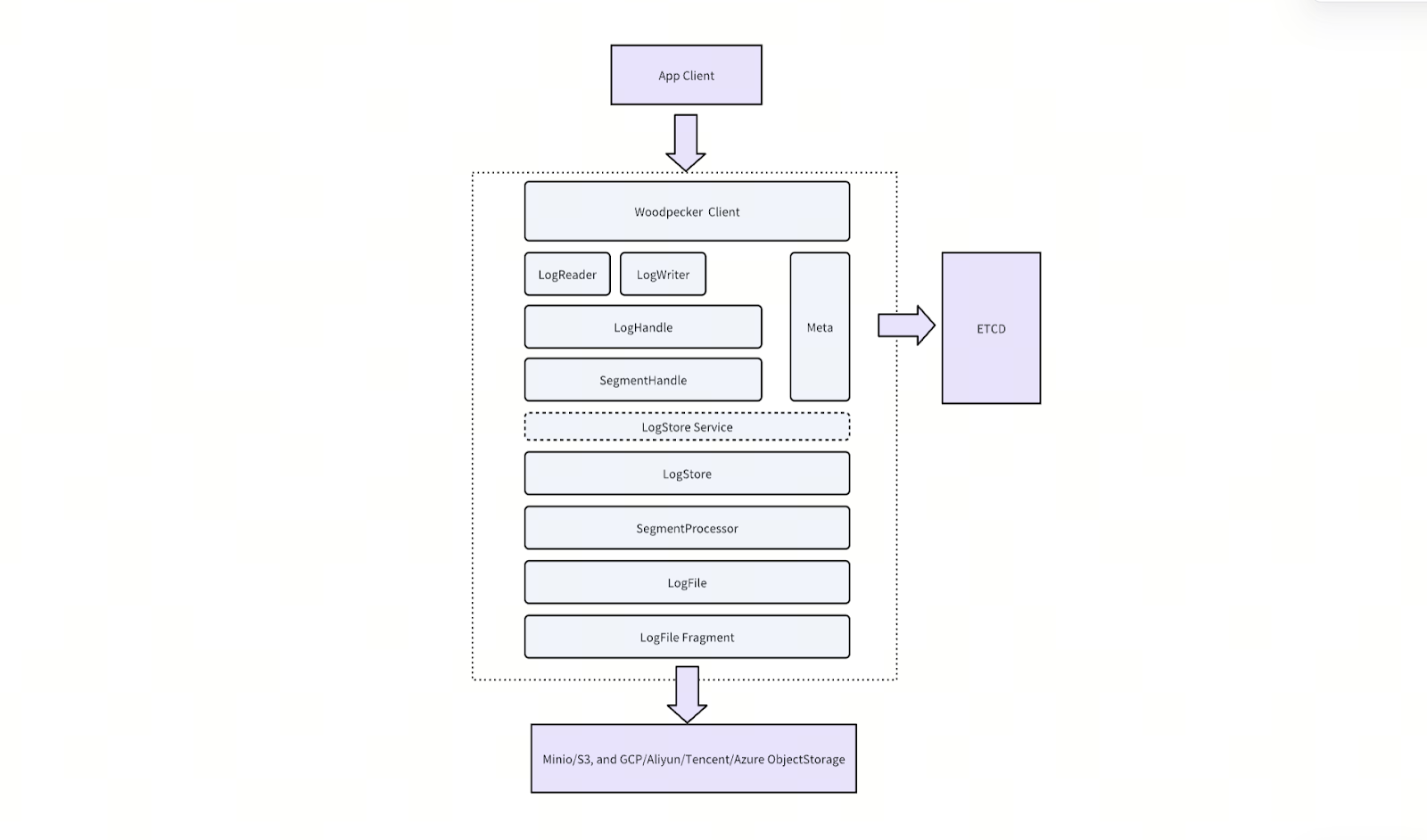
Figure: Woodpecker Architecture Overview
This approach dramatically reduces operational overhead while maximizing durability and cloud efficiency. By eliminating local disk dependencies, Woodpecker aligns perfectly with cloud-native principles and significantly reduces the operational burden on system administrators.
Performance Benchmarks: Exceeding Expectations
We ran comprehensive benchmarks to evaluate Woodpecker’s performance in a single-node, single-client, single-log-stream setup. The results were impressive when compared to Kafka and Pulsar:
| System | Kafka | Pulsar | WP MinIO | WP Local | WP S3 |
|---|---|---|---|---|---|
| Throughput | 129.96 MB/s | 107 MB/s | 71 MB/s | 450 MB/s | 750 MB/s |
| Latency | 58 ms | 35 ms | 184 ms | 1.8 ms | 166 ms |
For context, we measured the theoretical throughput limits of different storage backends on our test machine:
MinIO: ~110 MB/s
Local file system: 600–750 MB/s
Amazon S3 (single EC2 instance): up to 1.1 GB/s
Remarkably, Woodpecker consistently achieved 60-80% of the maximum possible throughput for each backend—an exceptional efficiency level for middleware.
Key Performance Insights
Local File System Mode: Woodpecker achieved 450 MB/s—3.5× faster than Kafka and 4.2× faster than Pulsar—with ultra-low latency at just 1.8 ms, making it ideal for high-performance single-node deployments.
Cloud Storage Mode (S3): When writing directly to S3, Woodpecker reached 750 MB/s (about 68% of S3’s theoretical limit), 5.8× higher than Kafka and 7× higher than Pulsar. While latency is higher (166 ms), this setup provides exceptional throughput for batch-oriented workloads.
Object Storage Mode (MinIO): Even with MinIO, Woodpecker achieved 71 MB/s—around 65% of MinIO’s capacity. This performance is comparable to Kafka and Pulsar but with significantly lower resource requirements.
Woodpecker is particularly optimized for concurrent, high-volume writes where maintaining order is critical. And these results only reflect the early stages of development—ongoing optimizations in I/O merging, intelligent buffering, and prefetching are expected to push performance even closer to theoretical limits.
Design Goals
Woodpecker addresses the evolving demands of real-time vector search workloads through these key technical requirements:
High-throughput data ingestion with durable persistence across availability zone
Low-latency tail reads for real-time subscriptions and high-throughput catch-up reads for failure recovery
Pluggable storage backends, including cloud object storage and file systems with NFS protocol support
Flexible deployment options, supporting both lightweight standalone setups and large-scale clusters for multi-tenant Milvus deployments
Architecture Components
A standard Woodpecker deployment includes the following components.
Client – Interface layer for issuing read and write requests
LogStore – Manages high-speed write buffering, asynchronous uploads to storage, and log compaction
Storage Backend – Supports scalable, low-cost storage services such as S3, GCS, and file systems like EFS
ETCD – Stores metadata and coordinates log state across distributed nodes
Flexible Deployments to Match Your Specific Needs
Woodpecker offers two deployment modes to match your specific needs:
MemoryBuffer Mode – Lightweight and Maintenance-Free
MemoryBuffer Mode provides a simple and lightweight deployment option where Woodpecker temporarily buffers incoming writes in memory and periodically flushes them to a cloud object storage service. Metadata is managed using etcd to ensure consistency and coordination. This mode is best suited for batch-heavy workloads in smaller-scale deployments or production environments that prioritize simplicity over performance, especially when low write latency is not critical.
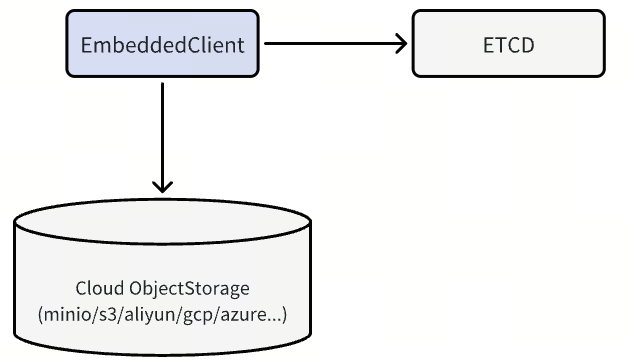
Figure: The memoryBuffer Mode
QuorumBuffer Mode – Optimized for Low-Latency, High-Durability Deployments
QuorumBuffer Mode is designed for latency-sensitive, high-frequency read/write workloads requiring both real-time responsiveness and strong fault tolerance. In this mode, Woodpecker functions as a high-speed write buffer with three-replica quorum writes, ensuring strong consistency and high availability.
A write is considered successful once it’s replicated to at least two of the three nodes, typically completing within single-digit milliseconds, after which the data is asynchronously flushed to cloud object storage for long-term durability. This architecture minimizes on-node state, eliminates the need for large local disk volumes, and avoids complex anti-entropy repairs often required in traditional quorum-based systems.
The result is a streamlined, robust WAL layer ideal for mission-critical production environments where consistency, availability, and fast recovery are essential.
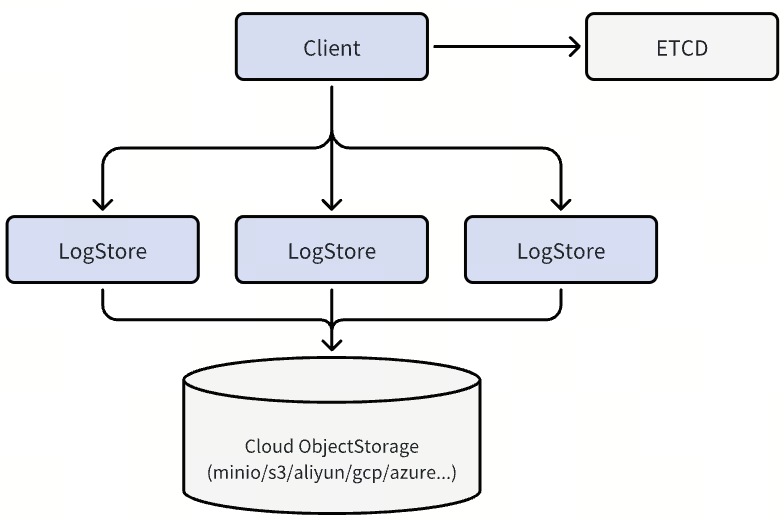
Figure: The QuorumBuffer Mode
StreamingService: Built for Real-Time Data Flow
Beyond Woodpecker, Milvus 2.6 introduces the StreamingService—a specialized component designed for log management, log ingestion, and streaming data subscription.
To understand how our new architecture works, it’s important to clarify the relationship between these two components:
Woodpecker is the storage layer that handles the actual persistence of write-ahead logs, providing durability and reliability
StreamingService is the service layer that manages log operations and provides real-time data streaming capabilities
Together, they form a complete replacement for external message queues. Woodpecker provides the durable storage foundation, while StreamingService delivers the high-level functionality that applications interact with directly. This separation of concerns allows each component to be optimized for its specific role while working seamlessly together as an integrated system.
Adding Streaming Service to Milvus 2.6
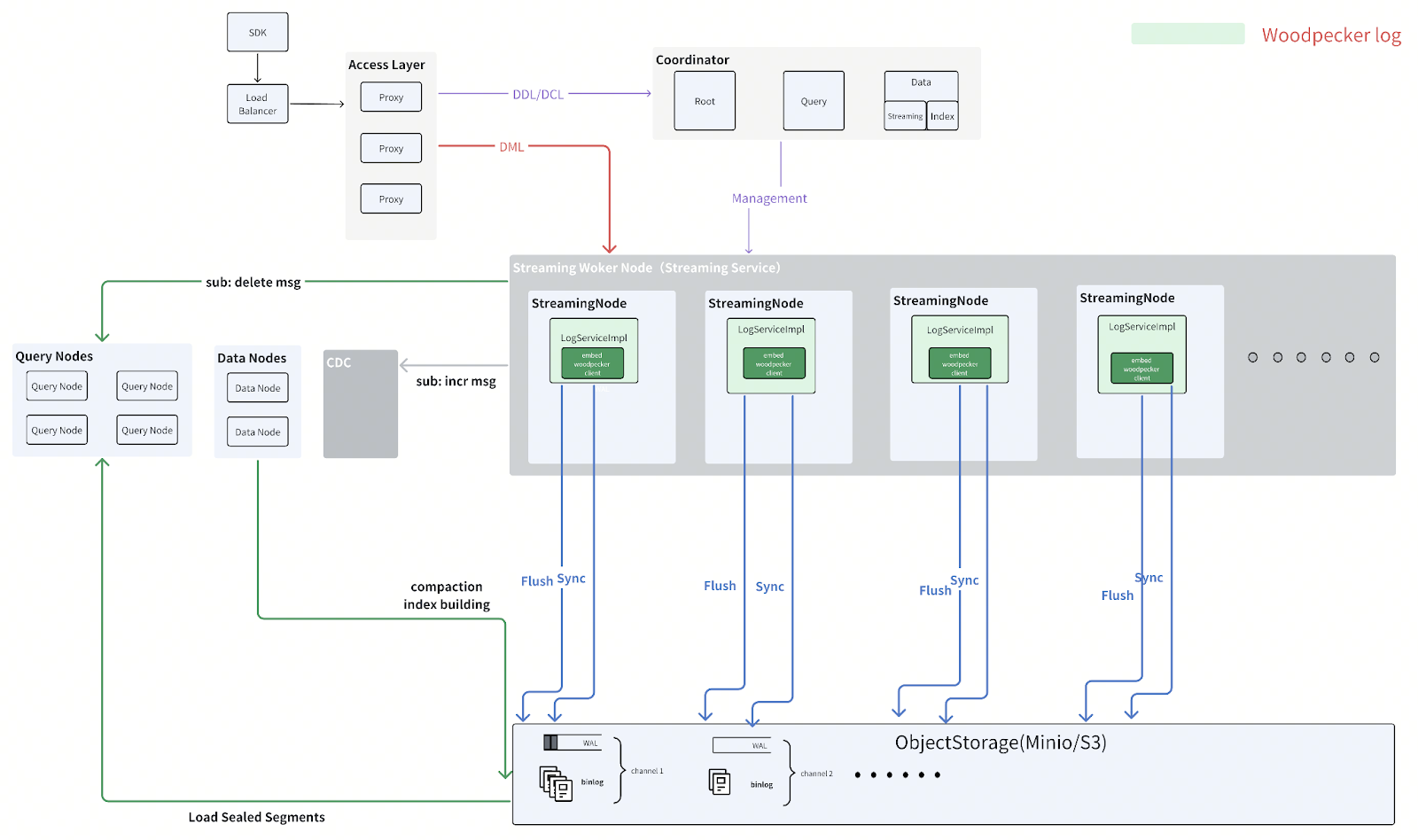
Figure: Streaming Service Added in Milvus 2.6 Architecture
The Streaming Service is composed of three core components:
Streaming Coordinator
Discovers available Streaming Nodes by monitoring Milvus ETCD sessions
Manages the status of WALs and collects load balancing metrics through the ManagerService
Streaming Client
Queries the AssignmentService to determine WAL segment distribution across Streaming Nodes
Performs read/write operations via the HandlerService on the appropriate Streaming Node
Streaming Node
Handles actual WAL operations and provides publish-subscribe capabilities for real-time data streaming
Includes the ManagerService for WAL administration and performance reporting
Features the HandlerService that implements efficient publish-subscribe mechanisms for WAL entries
This layered architecture allows Milvus to maintain clear separation between the streaming functionality (subscription, real-time processing) and the actual storage mechanisms. Woodpecker handles the “how” of log storage, while StreamingService manages the “what” and “when” of log operations.
As a result, the Streaming Service significantly enhances the real-time capabilities of Milvus by introducing native subscription support, eliminating the need for external message queues. It reduces memory consumption by consolidating previously duplicated caches in the query and data paths, lowers latency for strongly consistent reads by removing asynchronous synchronization delays, and improves both scalability and recovery speed across the system.
Conclusion - Streaming on a Zero-Disk Architecture
Managing state is hard. Stateful systems often sacrifice elasticity and scalability. The increasingly accepted answer in cloud-native design is to decouple state from compute—allowing each to scale independently.
Rather than reinventing the wheel, we delegate the complexity of durable, scalable storage to the world-class engineering teams behind services like AWS S3, Google Cloud Storage, and MinIO. Among them, S3 stands out for its virtually unlimited capacity, eleven nines (99.999999999%) of durability, 99.99% availability, and high-throughput read/write performance.
But even “zero-disk” architectures have trade-offs. Object stores still struggle with high write latency and small-file inefficiencies—limitations that remain unresolved in many real-time workloads.
For vector databases—especially those supporting mission-critical RAG, AI agents, and low-latency search workloads—real-time access and fast writes are non-negotiable. That’s why we rearchitected Milvus around Woodpecker and the Streaming Service. This shift simplifies the overall system (let’s face it—no one wants to maintain a full Pulsar stack inside a vector database), ensures fresher data, improves cost-efficiency, and speeds up failure recovery.
We believe Woodpecker is more than just a Milvus component—it can serve as a foundational building block for other cloud-native systems. As cloud infrastructure evolves, innovations like S3 Express may bring us even closer to the ideal: cross-AZ durability with single-digit millisecond write latency.
Getting Started with Milvus 2.6
Milvus 2.6 is available now. In addition to Woodpecker, it introduces dozens of new features and performance optimizations such as tiered storage, RabbitQ quantization method, and enhanced full-text search and multitenancy, directly addressing the most pressing challenges in vector search today: scaling efficiently while keeping costs under control.
Ready to explore everything Milvus offers? Dive into our release notes, browse the complete documentation, or check out our feature blogs.
Have questions? You’re also welcome to join our Discord community or file an issue on GitHub — we’re here to help you make the most of Milvus 2.6.
- The Starting Point: When Message Queues No Longer Fit
- Cloud-Native From Day One
- The Shared Log Architecture: Our Foundation
- Our Initial Solution: Message Queues as WAL
- Why We Needed Something Different for WAL
- Operational Complexity
- Architectural Constraints
- Resource Inefficiency
- Introducing Woodpecker - A Cloud-Native, High-Performance WAL Engine
- The Zero-Disk Architecture for Woodpecker
- Performance Benchmarks: Exceeding Expectations
- Design Goals
- Architecture Components
- Flexible Deployments to Match Your Specific Needs
- StreamingService: Built for Real-Time Data Flow
- Adding Streaming Service to Milvus 2.6
- Conclusion - Streaming on a Zero-Disk Architecture
- Getting Started with Milvus 2.6
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



